









读《鲜活的数据》第二章有个从wunderground.com获取历史天气数据的例子。那是个国外的网站,或许国内的天气网站有更多关于国内城市的天气信息,用搜狗搜了“历史天气”,果然找到一个提供历史数据的网站lishi.tianqi.com,观察了一下它的页面结构,写了一个从这个网站抓取特定城市一年中每天天气的python程序。
历史天气的页面是以月为单位展示数据的,每个城市每个月对应一个页面,在url中体现出来,比如北京2012年3月的天气数据在http://lishi.tianqi.com/beijing/201203.html这个页面中。每天的数据则集中在当月页面中一个class名为"tqtongji2"的div中,这个div有一组ul标签,每个对应一天的数据,但第一行ul是表头,抓取的时候要跳过这个第一行,第一行ul标签有个特点,就是它有个class属性,而其他ul是没有属性的,因而程序可以利用这个特点辨别并跳过这一行。
下面就是python的抓取程序。python是2.7版,使用了 3.1版的BeautifulSoup作为html解析组件。
from __future__ import print_function
import urllib2
from BeautifulSoup import BeautifulSoup
strYear = '2013'
strFile = 'beijingWeather' + strYear + '.csv'
f = open(strFile, 'w')
for month in range(1, 13):
if(month < 10):
strMonth = '0' + str(month)
else:
strMonth = str(month)
strYearMonth = strYear + strMonth
print("\nGetting data for month" + strYearMonth + "...", end='')
url = "http://lishi.tianqi.com/beijing/"+strYearMonth+".html"
page = urllib2.urlopen(url)
soup = BeautifulSoup(page)
weatherSet = soup.find(attrs={"class":"tqtongji2"})
if(weatherSet == None):
print("fail to get the page", end='')
continue
for line in weatherSet.contents:
if(line.__class__.__name__ == 'NavigableString'): continue
if(len(line.attrs) > 0): continue
lis = line.findAll('li')
strDate = lis[0].text
highWeather = lis[1].text
lowWeather = lis[2].text
f.write(strDate +',' + lowWeather +',' + highWeather + '\n')
print("done", end='')
f.close()
print ("\nover")
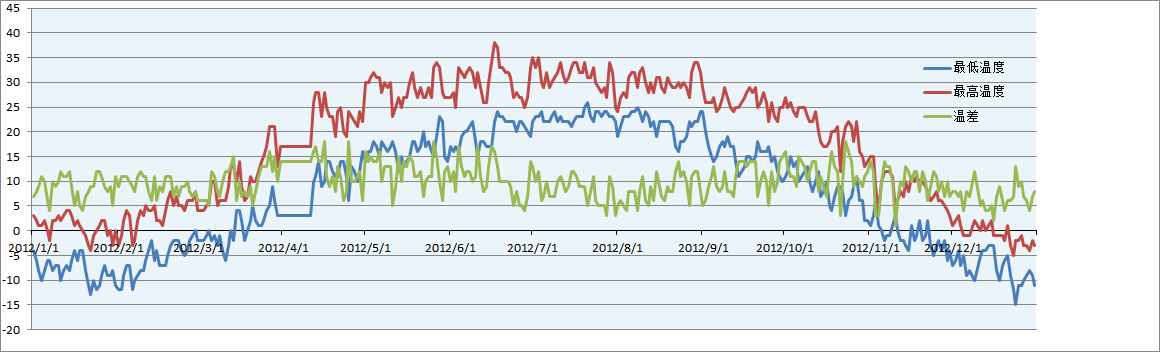
写完程序跑了一下2012年的数据,画了个曲线供参考(网站上缺失2012.4.1到4.11的数据,我用2012.3.31那天的数据填补了这段空缺,所以那几天的线条是直线)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









