







非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,可以理解为局部最大搜索。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。常用于目标检测,边缘检测中。
- 首先边界点不是极值的搜索范围,所以对于一组长度为n的数来说,搜索范围为2~n –1。
- 局部极大值满足,该点的值大于相邻的左右两边的点的值。当确定该点是局部最大值时,即可将迭代参数增加2,继续寻找下一个局部极大值。
- 迭代参数从左边开始,若不满足该点的值大于右边的值时,则需要将迭代参数依次增加1,直到满足当前点的值大于右边数的值停止,此时得到局部最优值。然后继续第2步,直到遍历所有数为止。
伪代码具体流程如下:
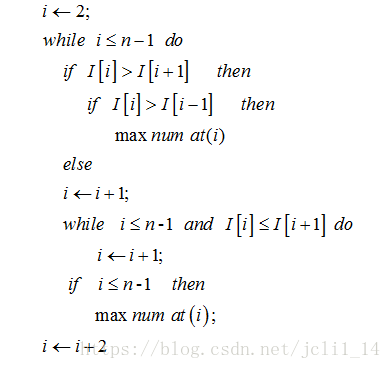
非极大值抑制在目标检测中的应用
最近一直在看Faster RCNN,以此为例,Faster RCNN中的预测出来的box会有重叠部分,即存在同一物体上存在多个重叠的box的问题,这时候就需要利用NMS算法来消除一些冗余的box,保留效果最好的。
例如在R-CNN中对于20000多个(论文中以典型值1000*600大小图片经vgg16的pool5后输出的feature map 大小为40*60,每一点对应生成9个anchor box)region proposals得到特征向量(4096维)后,除去一些和边界相交的box后大约剩下6000多个box。这么多数量的anchorboxes之间肯定是有很多重叠区域,因此需要使用非极大值抑制法(NMS,non-maximum suppression)将IoU>0.7的区域全部合并,最后就剩下约2000个anchor boxes。
将其输入到SVM中进行打分。除了背景以外VOC数据集共有20类。那么2000*4096维特征矩阵与20个SVM组成的权重矩阵4096*20相乘得到结果为6000*20维矩阵。这个矩阵2000行表示有2000个框。20列为每一个框属于这20个类的score(置信度)。也就是每一类有2000个不同的score。那么每一类有这么多候选框肯定大多冗余。NMS不会影响最终的检测准确率,但是大幅地减少了建议框的数量。经过NMS算法之后,我们用建议区域中的top-N个来检测(即排过序后取N个)
具体做法
假设一共有n个框,根据分类器分类概率从大到小排列。第一步,从最大的置信度的box开始,分别判断其余的box的与最大置信度的box的IOU值,大于阈值时则丢弃,小于阈值则保留,同时保留最大置信度的box。第二步经过比较后的在剩余的box内再次选置信度最大的并标记保留,与剩下的box做与第一步的相同的操作,就这样直到找到满足条件所有的保留框。
源码:
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
import numpy as np
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
x1 = dets[:, 0] #所有左上角点横坐标
y1 = dets[:, 1] #所有左上角点纵坐标
x2 = dets[:, 2] #所有右下角点横坐标
y2 = dets[:, 3] #所有右下角点纵坐标
scores = dets[:, 4] #所有框的置信度
areas = (x2 - x1 + 1) * (y2 - y1 + 1) #所有box的面积
order = scores.argsort()[::-1] #按照从大到小的顺序来排列
keep = [] #保留的结果框的集合
while order.size > 0:
i = order[0]
keep.append(i)
#得到两个矩形框的相交区域
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h #相交区域的面积
ovr = inter / (areas[i] + areas[order[1:]] - inter) #计算IOU值
inds = np.where(ovr <= thresh)[0] #保留IOU小于阈值的box
order = order[inds + 1] #ovr数组比order数组少一位,所以下标加上1
return keep


















 7823
7823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











