







为了简化命令行方式运行作业,Hadoop自带了一些辅助类。GenericOptionsParser是一个类,用来解释常用的Hadoop命令行选项,并根据需要,为Configuration对象设置相应的取值。通常不直接使用GenericOptionsParser,更方便的方式是:实现Tool接口,通过ToolRunner来运行应用程序,ToolRunner内部调用GenericOptionsParser。
一、相关的类及接口解释
(一)相关类及其对应关系如下:

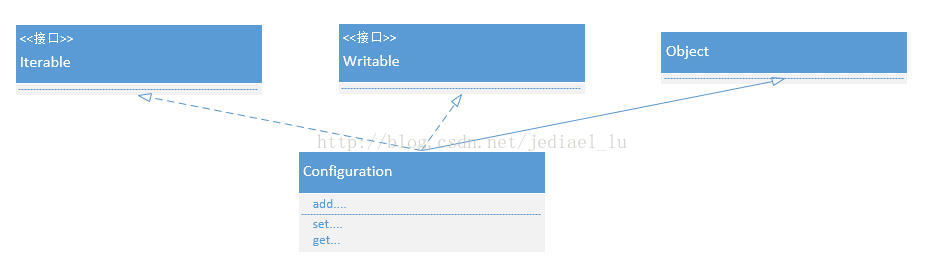
关于ToolRunner典型的实现方法
1、定义一个类(如上图中的MyClass),继承configured,实现Tool接口。
2、在main()方法中通过ToolRunner.run(...)方法调用上述类的run(String[]方法)
见第三部分的例子。
(二)关于ToolRunner
1、ToolRunner与上图中的类、接口无任何的继承、实现关系,它只继承了Object,没实现任何接口。
2、ToolRunner可以方便的运行那些实现了Tool接口的类(调用其run(String[])方法,并通过GenericOptionsParser 可以方便的处理hadoop命令行参数。
A utility to help run Tools.
ToolRunner can be used to run classes implementing Tool interface. It works in conjunction with GenericOptionsParser to parse the generic hadoop command line arguments and modifies the Configuration of the Tool. The application-specific options are passed along without being modified.
3、ToolRunner除了一个空的构造方法以外,只有一个方法,即run()方法,它有以下2种形式:
run
public static int run(Configuration conf, Tool tool, String[] args) throws Exception
- Runs the given Tool by Tool.run(String[]), after parsing with the given generic arguments. Uses the given Configuration, or builds one if null. Sets the Tool's configuration with the possibly modified version of the conf.
-
-
Parameters:
- conf - Configuration for the Tool.
- tool - Tool to run.
- args - command-line arguments to the tool. Returns:
- exit code of the Tool.run(String[]) method. Throws:
- Exception
run
public static int run(Tool tool, String[] args) throws Exception
- Runs the Tool with its Configuration. Equivalent to run(tool.getConf(), tool, args).
-
-
Parameters:
- tool - Tool to run.
- args - command-line arguments to the tool. Returns:
- exit code of the Tool.run(String[]) method. Throws:
- Exception
它们均是静态方法,即可以通过类名调用。
这个方法调用tool的run(String[])方法,并使用conf中的参数,以及args中的参数,而args一般来源于命令行。
这个方法调用tool的run方法,并使用tool类的参数属性,即等同于run(tool.getConf(), tool, args)。
除此以外,还有一个方法:
static void printGenericCommandUsage(PrintStream out)
Prints generic command-line argurments and usage information.
4、ToolRunner完成以下2个功能:
(1)为Tool创建一个Configuration对象。
(2)使得程序可以方便的读取参数配置。
ToolRunner完整源代码如下:
package org.apache.hadoop.util;
import java.io.PrintStream;
import org.apache.hadoop.conf.Configuration;
/**
* A utility to help run {@link Tool}s.
*
* <p><code>ToolRunner</code> can be used to run classes implementing
* <code>Tool</code> interface. It works in conjunction with
* {@link GenericOptionsParser} to parse the
* <a href="{@docRoot}/org/apache/hadoop/util/GenericOptionsParser.html#GenericOptions">
* generic hadoop command line arguments</a> and modifies the
* <code>Configuration</code> of the <code>Tool</code>. The
* application-specific options are passed along without being modified.
* </p>
*
* @see Tool
* @see GenericOptionsParser
*/
public class ToolRunner {
/**
* Runs the given <code>Tool</code> by {@link Tool#run(String[])}, after
* parsing with the given generic arguments. Uses the given
* <code>Configuration</code>, or builds one if null.
*
* Sets the <code>Tool</code>'s configuration with the possibly modified
* version of the <code>conf</code>.
*
* @param conf <code>Configuration</code> for the <code>Tool</code>.
* @param tool <code>Tool</code> to run.
* @param args command-line arguments to the tool.
* @return exit code of the {@link Tool#run(String[])} method.
*/
public static int run(Configuration conf, Tool tool, String[] args)
throws Exception{
if(conf == null) {
conf = new Configuration();
}
GenericOptionsParser parser = new GenericOptionsParser(conf, args);
//set the configuration back, so that Tool can configure itself
tool.setConf(conf);
//get the args w/o generic hadoop args
String[] toolArgs = parser.getRemainingArgs();
return tool.run(toolArgs);
}
/**
* Runs the <code>Tool</code> with its <code>Configuration</code>.
*
* Equivalent to <code>run(tool.getConf(), tool, args)</code>.
*
* @param tool <code>Tool</code> to run.
* @param args command-line arguments to the tool.
* @return exit code of the {@link Tool#run(String[])} method.
*/
public static int run(Tool tool, String[] args)
throws Exception{
return run(tool.getConf(), tool, args);
}
/**
* Prints generic command-line argurments and usage information.
*
* @param out stream to write usage information to.
*/
public static void printGenericCommandUsage(PrintStream out) {
GenericOptionsParser.printGenericCommandUsage(out);
}
}
(三)关于Configuration
1、默认情况下,hadoop会加载core-default.xml以及core-site.xml中的参数。
Unless explicitly turned off, Hadoop by default specifies two resources, loaded in-order from the classpath:
- core-default.xml : Read-only defaults for hadoop.
- core-site.xml: Site-specific configuration for a given hadoop installation.
见以下代码:
static{
//print deprecation warning if hadoop-site.xml is found in classpath
ClassLoader cL = Thread.currentThread().getContextClassLoader();
if (cL == null) {
cL = Configuration.class.getClassLoader();
}
if(cL.getResource("hadoop-site.xml")!=null) {
LOG.warn("DEPRECATED: hadoop-site.xml found in the classpath. " +
"Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, "
+ "mapred-site.xml and hdfs-site.xml to override properties of " +
"core-default.xml, mapred-default.xml and hdfs-default.xml " +
"respectively");
}
addDefaultResource("core-default.xml");
addDefaultResource("core-site.xml");
}同时,检查是否还存在hadoop-site.xml,若还存在,则给出warning,提醒此配置文件已经废弃。
如何查找到上述2个文件:(见hadoop命令的脚本)
(1)定位HADOOP_CONF_DIR Alternate conf dir. Default is ${HADOOP_HOME}/conf.
(2)将HADOOP_CONF_DIR加入CLASSPATH="${HADOOP_CONF_DIR}"
(3)可以在CLASSPATH中直接查找上述文件。
2、在程序运行时,可以通过命令行修改参数,修改方法如下

3、Configuration类中有大量的add****,set****,get****方法,用于设置及获取参数。
for (Entry<String, String> entry : conf){
.....
}(四)关于Tool
1、Tool类的源文件如下
package org.apache.hadoop.util;
import org.apache.hadoop.conf.Configurable;
public interface Tool extends Configurable {
int run(String [] args) throws Exception;
}
(五)关于Configrable与Conifgured
1、Configurable的源文件如下:
package org.apache.hadoop.conf;
public interface Configurable {
void setConf(Configuration conf);
Configuration getConf();
}
有2个对于Configuration的set与get方法。
2、Configured的源文件如下:
package org.apache.hadoop.conf;
public class Configured implements Configurable {
private Configuration conf;
public Configured() {
this(null);
}
public Configured(Configuration conf) {
setConf(conf);
}
public void setConf(Configuration conf) {
this.conf = conf;
}
public Configuration getConf() {
return conf;
}
}
实现了Configuable中对于Configuration的set与get方法。
二、示例程序一:呈现所有参数
下面是一个简单的程序:
package org.jediael.hadoopdemo.toolrunnerdemo;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ToolRunnerDemo extends Configured implements Tool {
static {
//Configuration.addDefaultResource("hdfs-default.xml");
//Configuration.addDefaultResource("hdfs-site.xml");
//Configuration.addDefaultResource("mapred-default.xml");
//Configuration.addDefaultResource("mapred-site.xml");
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
for (Entry<String, String> entry : conf) {
System.out.printf("%s=%s\n", entry.getKey(), entry.getValue());
}
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new ToolRunnerDemo(), args);
System.exit(exitCode);
}
}
以上程序用于输出上述xml文件中定义的属性。
1、直接运行程序
[
root@jediael project]#
hadoop jar toolrunnerdemo.jar org.jediael.hadoopdemo.toolrunnerdemo.ToolRunnerDemo
io.seqfile.compress.blocksize=1000000
keep.failed.task.files=false
mapred.disk.healthChecker.interval=60000
dfs.df.interval=60000
dfs.datanode.failed.volumes.tolerated=0
mapreduce.reduce.input.limit=-1
mapred.task.tracker.http.address=0.0.0.0:50060
mapred.used.genericoptionsparser=true
mapred.userlog.retain.hours=24
dfs.max.objects=0
mapred.jobtracker.jobSchedulable=org.apache.hadoop.mapred.JobSchedulable
mapred.local.dir.minspacestart=0
hadoop.native.lib=true
io.seqfile.compress.blocksize=1000000
keep.failed.task.files=false
mapred.disk.healthChecker.interval=60000
dfs.df.interval=60000
dfs.datanode.failed.volumes.tolerated=0
mapreduce.reduce.input.limit=-1
mapred.task.tracker.http.address=0.0.0.0:50060
mapred.used.genericoptionsparser=true
mapred.userlog.retain.hours=24
dfs.max.objects=0
mapred.jobtracker.jobSchedulable=org.apache.hadoop.mapred.JobSchedulable
mapred.local.dir.minspacestart=0
hadoop.native.lib=true
......................
2、通过-D指定新的参数
[
root@jediael project]# hadoop org.jediael.hadoopdemo.toolrunnerdemo.ToolRunnerDemo
-D color=yello | grep color
color=yello
color=yello
3、通过-conf增加新的配置文件
(1)原有参数数量
[
root@jediael project]# hadoop jar toolrunnerdemo.jar org.jediael.hadoopdemo.toolrunnerdemo.ToolRunnerDemo | wc
67 67 2994
(2)增加配置文件后的参数数量
[
root@jediael project]# hadoop jar toolrunnerdemo.jar org.jediael.hadoopdemo.toolrunnerdemo.ToolRunnerDemo
-conf /opt/jediael/hadoop-1.2.0/conf/mapred-site.xml | wc
68 68 3028
68 68 3028
其中mapred-site.xml的内容如下:
<?xml version="1.0"?>
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
可见此文件只有一个property,因此参数数量从67个变成了68个。
4、在代码中增加参数,如上面程序中注释掉的语句
static {
Configuration.addDefaultResource("hdfs-default.xml");
Configuration.addDefaultResource("hdfs-site.xml");
Configuration.addDefaultResource("mapred-default.xml");
Configuration.addDefaultResource("mapred-site.xml");
}
更多选项请见第Configuration的解释。
三、示例程序二:典型用法(修改wordcount程序)
修改经典的wordcount程序,参考:
Hadoop入门经典:WordCount
package org.jediael.hadoopdemo.toolrunnerdemo;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool{
public static class WordCountMap extends
Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return(job.waitForCompletion(true)?0:-1);
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new WordCount(), args);
System.exit(exitCode);
}
}
[root@jediael project]# hadoop fs -mkdir wcin2
[root@jediael project]# hadoop fs -copyFromLocal /opt/jediael/apache-nutch-2.2.1/CHANGES.txt wcin2
[root@jediael project]# hadoop jar wordcount2.jar org.jediael.hadoopdemo.toolrunnerdemo.WordCount wcin2 wcout2
由上可见,关于ToolRunner的典型用法是:
1、定义一个类,继承Configured,实现Tool接口。其中Configured提供了getConf()与setConfig()方法,而Tool则提供了run()方法。
2、在main()方法中通过ToolRunner.run(...)方法调用上述类的run(String[]方法)。
四、总结
1、通过使用ToolRunner.run(...)方法,可以更便利的使用hadoop命令行参数。
2、ToolRunner.run(...)通过调用Tool类中的run(String[])方法来运行hadoop程序,并默认加载core-default.xml与core-site.xml中的参数。















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









