






langfuse能系统性维护、测试、监控一个 LLM 应用,主要有如下能力:
- 各种指标监控与统计:访问记录、响应时长、Token 用量、计费等等
- 调试 Prompt
- 测试/验证系统的相关评估指标
- 数据集管理(便于回归测试)
- Prompt 版本管理(便于升级/回滚)
LangFuse是开源的,支持 LangChain 集成或原生 OpenAI API 集成
官方网站:https://langfuse.com/
项目地址:https://github.com/langfuse
文档地址:https://langfuse.com/docs
API文档:https://api.reference.langfuse.com/
Python SDK: https://python.reference.langfuse.com/
LangFuse中用到的几个基本概念
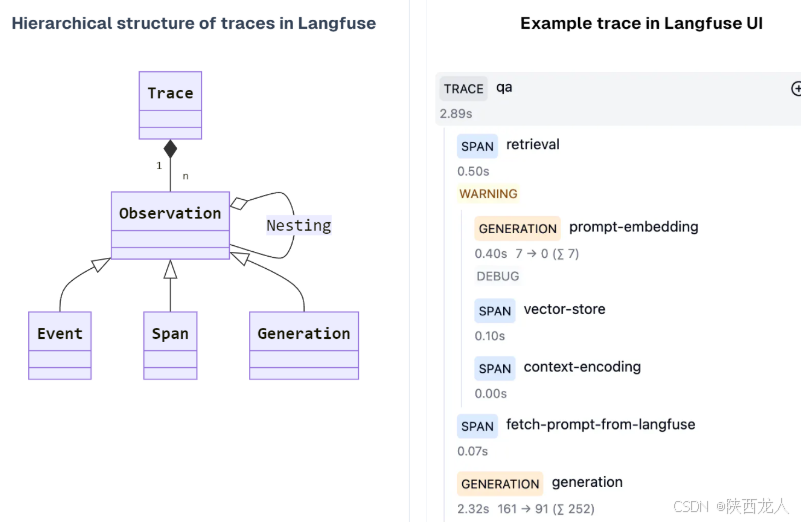
1. Trace 一般表示用户与系统的一次交互,其中记录输入、输出,也包括自定义的 metadata 比如用户名、session id 等;
2. 一个 trace 内部可以包含多个子过程,这里叫 observarions
3. Observation 可以是多个类型
a.Event 是最基本的单元,用于记录一个 trace 中的每个事件
b.Span 表一个 trace 中的一个"耗时"的过程
c. Generation 是用于记录与 AI 模型交互的 span,例如:调用 embedding 模型、调用 LLM
4.Observation 可以嵌套使用
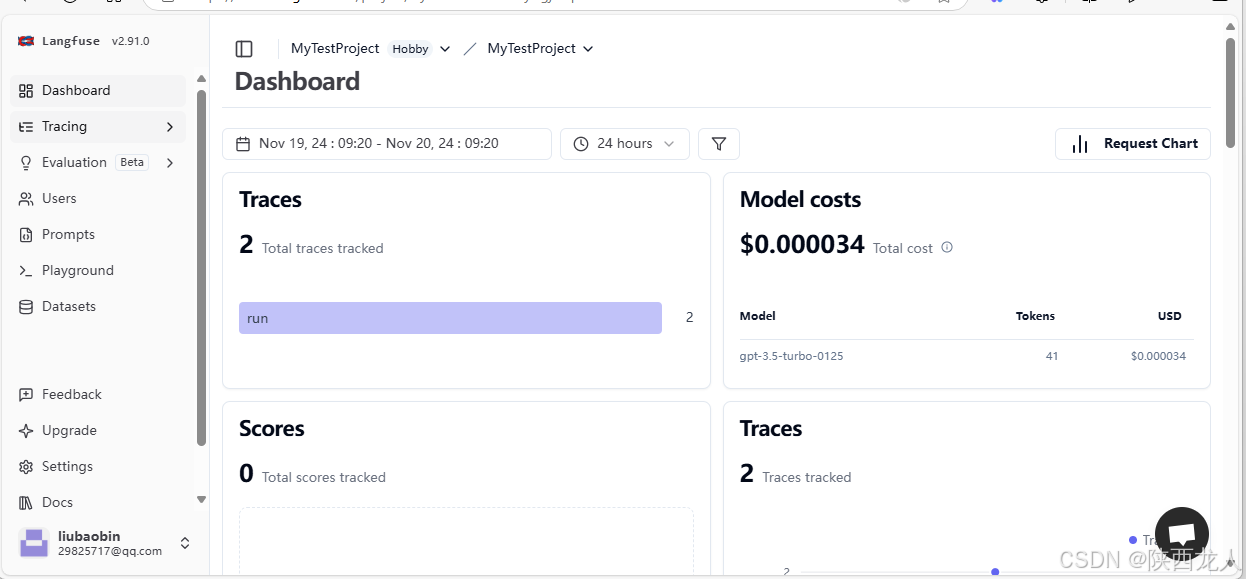
要用LangFuse的云服务,首先要在LangFuse官网上注册,注册完后将页面拉倒最后,点免费的SignUp,

进入后点击Go to project
 就到我们的监控页面了,如下
就到我们的监控页面了,如下
1. 通过装饰器记录访问大模型的信息
1.1案例 observbe
from langfuse.decorators import observe, langfuse_context
from langfuse.openai import openai # OpenAI integration
# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
@observe()
def run():
return openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "对我说Hello, World!"}
],
).choices[0].message.content
print(run())
langfuse_context.flush()
@observe()代表要监视的方法,执行后,会在Traceszhong 有一条Trace,如下

1.2 observe() 装饰器的参数
def observe(
self,
*,
name: Optional[str] = None, # Trace 或 Span 的名称,默认为函数名
as_type: Optional[Literal[‘generation’]] = None, # 将记录定义为 Observation (LLM 调用)
capture_input: bool = True, # 记录输入
capture_output: bool = True, # 记录输出
transform_to_string: Optional[Callable[[Iterable], str]] = None # 将输出转为 string
) -> Callable[[~F], ~F]
1.3 增加observe中的名称
from langfuse.decorators import observe, langfuse_context
from langfuse.openai import openai
@observe(name="HelloWorld")
def run():
return openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "对我说Hello, World!"}
],
).choices[0].message.content
print(run())
langfuse_context.flush()
效果如下
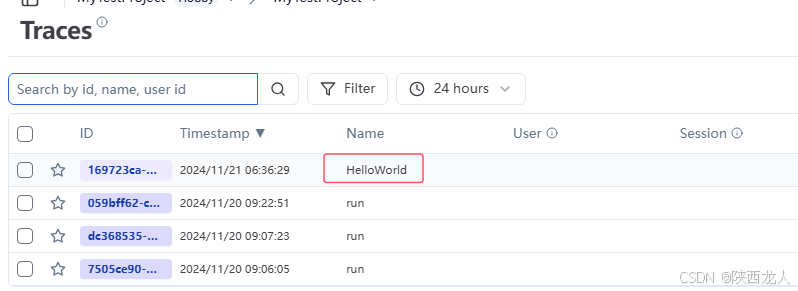
点击每一条,可以看到输入和输出的内容,运行时间等信息
2.通过 langfuse_context 记录 User ID、Metadata 等
from langfuse.decorators import observe, langfuse_context
from langfuse.openai import openai # OpenAI integration
@observe()
def run():
langfuse_context.update_current_trace(
name="HelloWorld",
user_id="wzr",
tags=["test","demo"]
)
return openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "对我说Hello, World!"}
],
).choices[0].message.content
print(run())
langfuse_context.flush()
会将user名及Tags写入
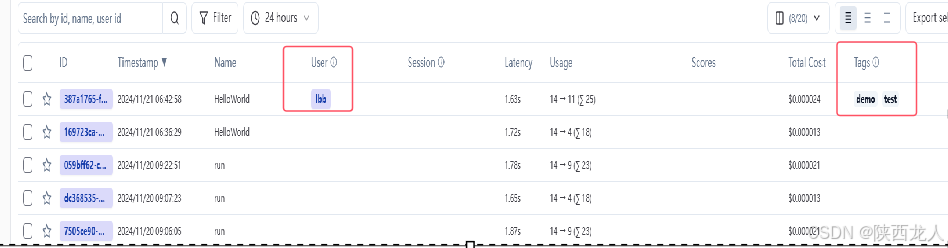
3.通过 LangChain 的回调集成langfuse
del openai
from langchain.prompts import ChatPromptTemplate,HumanMessagePromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
model = ChatOpenAI(model="gpt-3.5-turbo")
prompt = ChatPromptTemplate.from_messages([HumanMessagePromptTemplate.from_template("Say hello to {input}!")])
# 定义输出解析器
parser = StrOutputParser()
chain = ( {"input": RunnablePassthrough()} | prompt | model | parser)
前面代码时langchain的方法,下面是通过回调和langfuse集成写入到数据库
from langfuse.decorators import langfuse_context, observe
@observe()
def run():
langfuse_context.update_current_trace(
name="LangChainTest",
user_id="lbb",
)
# 获取当前 LangChain 回调处理器
langfuse_handler = langfuse_context.get_current_langchain_handler()
return chain.invoke(input="Sysml2", config={"callbacks": [langfuse_handler]})
print(run())
langfuse_context.flush() # Langfuse 回传记录是异步的,可以通过 flush 强制更新
将langfuse_handler事件放到chain中的config中
也支持千帆模型
顺便记录一个计算相似度的方法,就是2调语句的相似度,一般用作比较,超过某一阈值认为2条语句意思一样。
def cos_sim(v, m):
'''计算cosine相似度'''
score = np.dot(m, v)/(np.linalg.norm(m, axis=1)*np.linalg.norm(v))
return score.tolist()
4. 用 Session 记录一个用户的多轮对话
rom langchain_openai import ChatOpenAI
from langchain_core.messages import (
AIMessage, # 等价于OpenAI接口中的assistant role
HumanMessage, # 等价于OpenAI接口中的user role
SystemMessage # 等价于OpenAI接口中的system role
)
from datetime import datetime
from langfuse.decorators import langfuse_context, observe
now = datetime.now()
llm = ChatOpenAI()
messages = [SystemMessage(content="你是课程助理。"),]
session_id = "chat-"+now.strftime("%d/%m/%Y %H:%M:%S")
@observe()
def chat_one_turn(user_input, user_id, turn_id):
langfuse_context.update_current_trace(
name=f"ChatTurn{turn_id}",
user_id=user_id,
session_id=session_id
)
langfuse_handler = langfuse_context.get_current_langchain_handler()
messages.append(HumanMessage(content=user_input))
response = llm.invoke(messages, config={"callbacks": [langfuse_handler]})
messages.append(response)
return response.content
user_id="lbb"
turn_id = 0
while True:
user_input = input("User: ")
if user_input.strip() == "":
break
reply = chat_one_turn(user_input, user_id, turn_id)
print("AI: "+reply)
turn_id += 1
langfuse_context.flush()
执行如下
与 LlamaIndex 集成
from llama_index.core import Settings
from llama_index.core.callbacks import CallbackManager
from langfuse.llama_index import LlamaIndexCallbackHandler
# 定义 LangFuse 的 CallbackHandler
langfuse_callback_handler = LlamaIndexCallbackHandler()
# 修改 LlamaIndex 的全局设定
Settings.callback_manager = CallbackManager([langfuse_callback_handler])
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.node_parser import SentenceSplitter
from llama_index.readers.file import PyMuPDFReader
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# 指定全局llm与embedding模型
Settings.llm = OpenAI(temperature=0, model="gpt-4o")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=512)
Settings.transforms = [SentenceSplitter(chunk_size=300, chunk_overlap=100)]
# 加载 pdf 文档
documents = SimpleDirectoryReader("./data", file_extractor={".pdf": PyMuPDFReader()}).load_data()
# 指定 Vector Store 用于 index
index = VectorStoreIndex.from_documents(documents)
# 构建单轮 query engine
query_engine = index.as_query_engine()
response = query_engine.query("llama2有多少参数")
print(response)
执行llamindex时应用全局设定Setting。
Settings.callback_manager
Settings.llm
Settings.embed_model
Settings.transforms
其中Settings.callback_manager将执行日志写入到langfuse中
LangSmith:目前只支持Open|AI,所以在这里就不介绍了
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











