







Java开发者の模型召唤术:LangChain4j咏唱指南(三)
往期回顾:
上两期博客中简单的为大家介绍了
- langchain4j是什么、java 集成 langchain4j、集成阿里云百炼平台的各个模型以及本地安装的ollama模型的调用流程
- langchain4jSpring-boot集成、流式输出、记忆对话、function-call、预设角色等更深层次的知识
那么本期教程将会与大家分享关于langchain4j中的向量、向量存储、模型外接知识库相关的知识,码字不易,各位喜欢请一键三连~
1.RAG介绍
虽然对于我们上一期实现的模型来说,可以根据一些@Tools,@SystemMessage,对大模型的回答做一些限制,但是如果大模型需要在一些专业的领域回答问题,也不能通篇@Tools去实现专业领域的问题。因此往往会给大模型外接一个知识库。
1.1什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索与文本生成的先进AI技术,旨在通过引入外部知识库,提升生成内容的准确性和相关性。
1.2核心原理
检索(Retrieval)
- 当收到用户输入(如问题)时,RAG模型会从外部知识库(如文档、数据库)中检索相关段落或信息。
- 例如,若用户问“量子计算机的原理是什么?”,模型会先检索与“量子计算”相关的权威资料。
生成(Generation)
- 基于检索到的信息,生成模型(如GPT)会综合上下文,生成自然语言的回答。
- 生成过程不仅依赖模型本身的参数,还结合了检索到的实时数据。
1.3与传统模型的区别
| 传统模型(如GPT) | RAG |
|---|---|
| 仅依赖训练时学到的静态知识 | 动态引入外部最新知识 |
| 可能生成“看似合理但不准确”的内容 | 生成结果更可靠、有据可依 |
| 无法直接引用具体文档 | 可追溯答案来源(如引用某篇论文) |
1.4应用场景
智能问答系统
- 如客服机器人,直接基于企业文档库生成精准回答。
学术研究助手
- 根据论文数据库,解释复杂概念或提供研究建议。
事实核查
- 快速检索权威信息,验证生成内容的真实性。
个性化推荐
- 结合用户历史数据,生成定制化建议(如医疗诊断辅助)。
1.5优略分析
- 优势:
- 解决“模型幻觉”(生成虚构内容)问题。
- 支持知识更新,无需重新训练模型即可扩展知识库。
- 挑战:
- 检索效率影响实时性(需优化检索算法)。
- 对知识库质量依赖高(垃圾数据会导致错误生成)。
比如:在一次与大模型的讯问中,可能是按照下面的步骤进行运作
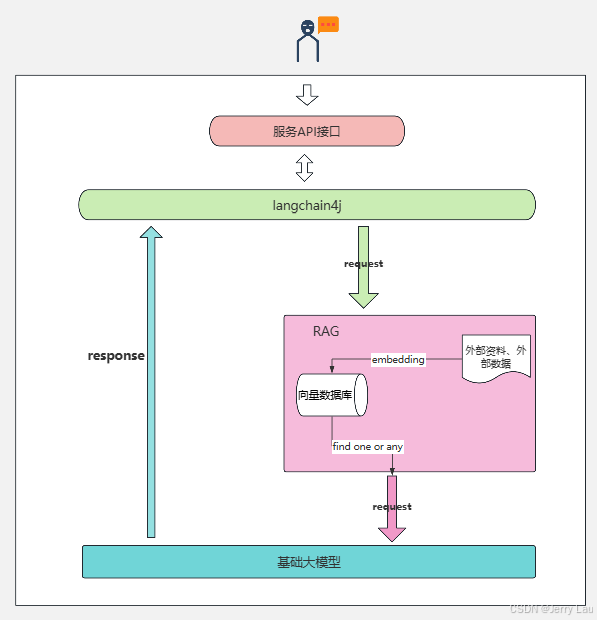
那再进行RAG学习之前,有几个概念,我们在一起了解一下
1.6一些名词解释
在 RAG(检索增强生成) 框架中,向量(Vector) 是连接检索与生成的核心桥梁。通过将文本转化为高维向量,RAG 能够快速从海量知识库中检索相关信息,并基于检索结果生成更准确的回答。
向量通常用来做相似度的搜索,一般可以根据维度等分为一维,二维,多维等。
1.6.1一维向量
一维向量可以表示一些词汇的语义相似度,举个例子,对于"你好",“hello”,"很高兴认识你"这些词的语义大概是差不多的,可以在一维向量中做如下表示:

只是我自己的一点小理解,不一定全对,大家领会精神就行哈。
1.6.2二维/多维向量
那么对于一些比较复杂的对象,比如狗狗,简单的一个维度明显已经不够标志他们,可能得提取多个特征值才能比较准确的描述他们。
举个🌰:
对于一只狗来说,可能存在以下特征值:
- 颜色?
- 毛发?直毛还是卷毛
- 具体的犬种?
- …
那么这些特征值 [黑色,卷毛,小型泰迪,…] 便可以表示出一种狗狗
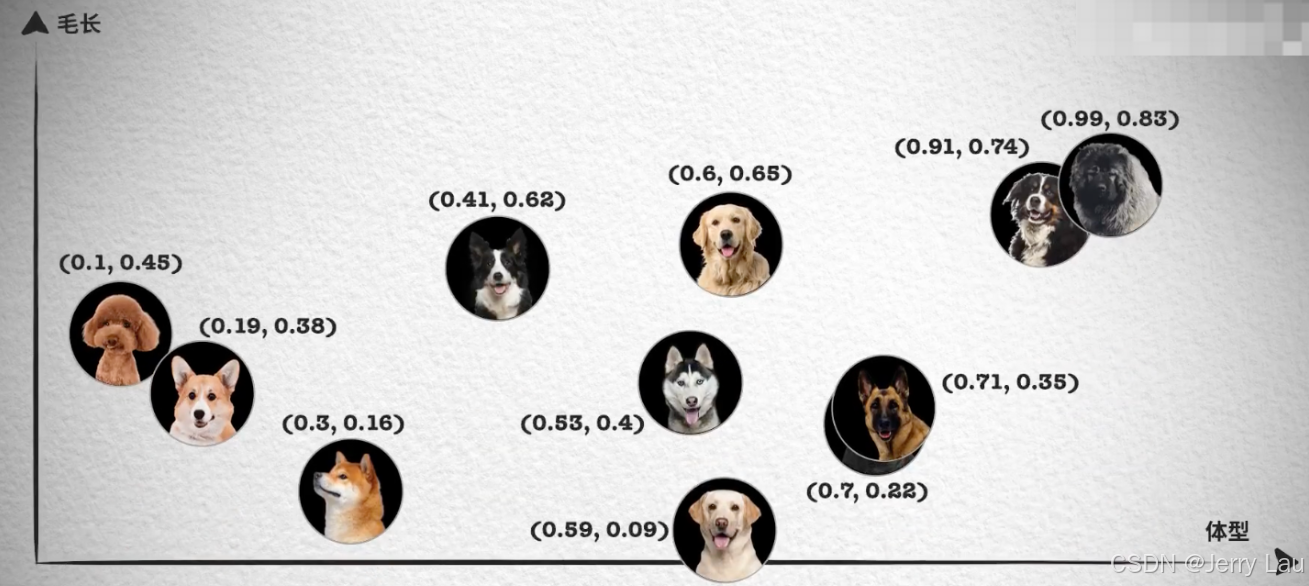
如果需要检索更加精准,我们肯定还需要更多维度的向量,更加确定的将一个物体抽象成一组数据,组成更多维度的空间,在多维向量空间中,相似性检索变得更加复杂。
可能需要使用一些算法,如余弦相似度或欧几里得距离,来计算向量之间的相似性。
但是在langchain4j中会通过向量数据库会帮我们实现。
1.7文本向量化
langchain4j中可以使用文本向量化的方式,实现对于一句话的向量化,并通过相关的向量数据库存储;先来了解一下文本的向量化,具体实现方式如下:
import dev.langchain4j.community.model.dashscope.QwenEmbeddingModel;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.model.output.Response;
/**
* @version 1.0
* @Author jerryLau
* @Date 2025/3/31 8:35
* @注释 简单的向量化示例
*/
public class EmBeddingExample {
public static void main(String[] args) {
QwenEmbeddingModel build = QwenEmbeddingModel.builder()
.apiKey("sk-XXXXXX")
.build();
String text = "我是一个测试文本";
Response<Embedding> embed = build.embed(text);
System.out.println(embed.content().toString());
System.out.println(embed.content().vectorAsList().size());
}
}
代码执行结果:

可以看到“我是一个测试文本”,这句话在QwenEmbeddingModel的向量化之后,生成了一个长度为1536的向量数组,由于是使用的QwenEmbeddingModel进行的向量化,所以这个长度是固定的,不论向量化的文本长度为多少,经向量化后,都会生成长度为1536的向量数组,即向量化结果输出长度固定,不会随被向量化文本长度变化。
那么计算出这个向量后有什么用呢?在举个🌰
比如你要查询一些资料,输入了你想查的问题,在将你的问题向量化后,得到一组数值;获取到这个向量数组后,在向量数据库中寻找到相似度最高的文本资料,返回给你,即你会得到你问题的答案。
1.8向量数据库
1.8.1langchain4j支持的向量数据库
对于向量模型生成出来的向量,我们可以持久化到向量数据库,并且能利用向量数据库来计算两个向量之间的相似度,并且根据相似度找到某个向量最相似的向量。
在LangChain4j中,EmbeddingStore表示向量数据库,它有支持20+嵌入模型:
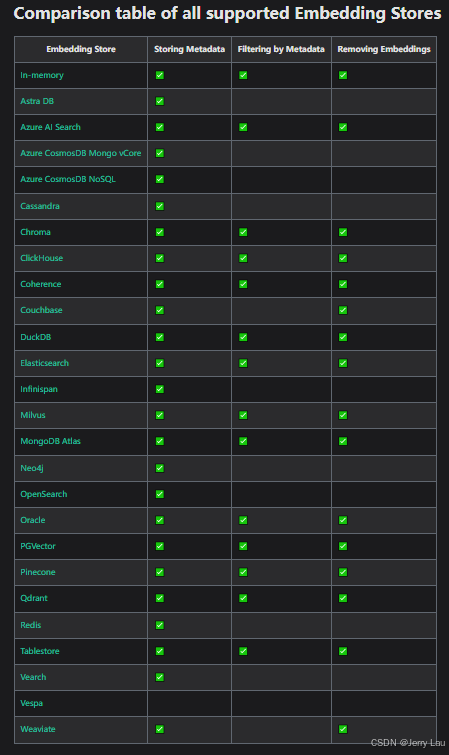
其中我们日常使用中的一些数据库,比如Elasticsearch、MongoDb、Redis等也可以用来存储向量。
下面我们使用比较简单的DuckDB来实现文本话存储以及相似度匹配查询
1.8.2 DuckDB简介
DuckDB 是什么?
DuckDB 是一个开源的 嵌入式分析型数据库(OLAP),专为高效的数据分析场景设计。它类似于 SQLite,但专注于高性能的联机分析处理(OLAP),而非事务处理(OLTP)。其核心特点包括:
- 嵌入式设计:无需独立服务器,直接嵌入到应用程序中运行。
- 轻量级:单文件存储,依赖极少,部署简单。
- 高性能:针对复杂分析查询优化,支持列式存储和向量化执行引擎。
- 兼容性:支持标准 SQL 语法,提供 Python、R、Java、C/C++ 等语言接口。
适用场景
- 数据分析与探索:快速处理本地 CSV/Parquet 文件,替代 Pandas 或 Excel 的大数据场景。
- 嵌入式分析:在应用程序中内置高性能分析功能(如报表生成、复杂统计)。
- 数据科学:与 Python/R 集成,替代临时性的 SQLite 或内存计算。
- 边缘计算:在资源受限的设备上运行轻量级分析任务。
存储方式
- 单文件存储
与其他数据库对比
| 特性 | DuckDB | SQLite | PostgreSQL |
|---|---|---|---|
| 设计目标 | OLAP | OLTP | OLTP/OLAP |
| 部署模式 | 嵌入式 | 嵌入式 | 独立服务 |
| 存储格式 | 单文件 | 单文件 | 多文件目录 |
| 分析性能 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
| 事务支持 | 有限 | ACID | ACID |
集成使用
pom.xml依赖引入:
<!-- simple-duckdb-->
<dependency>
<groupId>org.duckdb</groupId>
<artifactId>duckdb_jdbc</artifactId>
<version>1.2.1</version>
</dependency>
<!--langchain4j-duckdb-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-duckdb</artifactId>
<version>${langchain4j.version}</version>
</dependency>
简单的测试:
1-简单的连接使用
/**
* @version 1.0
* @Author jerryLau
* @Date 2025/3/31 10:00
* @注释 DuckDB 连接测试
*/
public class DuckDBConnectExample {
public static void main(String[] args) {
String url="jdbc:duckdb:/duck.db";
try(Connection connection = DriverManager.getConnection(url)){
if (connection.isValid(1000)) {
System.out.println("DuckDB 连接成功");
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
- jdbc:duckdb:langchain4j-springBoot-demo/src/main/java/com/jerry/langchain4jspringbootdemo/store/db/duck.db 默认会在绝对路径下创建这个db文件作为数据库
2-使用CRUD
/**
* @version 1.0
* @Author jerryLau
* @Date 2025/3/31 10:00
* @注释 DuckDB 操作测试
*/
public class DuckDBExample {
public static void main(String[] args) throws SQLException {
queryTable();
}
public static void createTable() throws SQLException {
String url = "jdbc:duckdb:langchain4j-springBoot-demo/src/main/java/com/jerry/langchain4jspringbootdemo/store/db/duck.db";
try (Connection connection = DriverManager.getConnection(url)) {
if (connection.isValid(1000)) {
System.out.println("DuckDB 连接成功");
connection.createStatement().execute("CREATE TABLE IF NOT EXISTS test (id INTEGER, name VARCHAR)");
System.out.println("创建表成功");
int rowsInserted = connection.createStatement()
.executeUpdate("INSERT INTO test VALUES (1, 'Jerry')");
System.out.println("插入数据行数: " + rowsInserted);
if (rowsInserted > 0) {
System.out.println("插入数据成功");
} else {
System.out.println("插入数据失败");
}
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public static void queryTable() throws SQLException {
String url = "jdbc:duckdb:langchain4j-springBoot-demo/src/main/java/com/jerry/langchain4jspringbootdemo/store/db/duck.db";
try (Connection connection = DriverManager.getConnection(url)) {
if (connection.isValid(1000)) {
System.out.println("DuckDB 连接成功");
ResultSet rs = connection.createStatement().executeQuery("SELECT * FROM test");
while (rs.next()) {
System.out.println(rs.getString("id") + "\t" + rs.getString("name")+ "\t" );
}
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
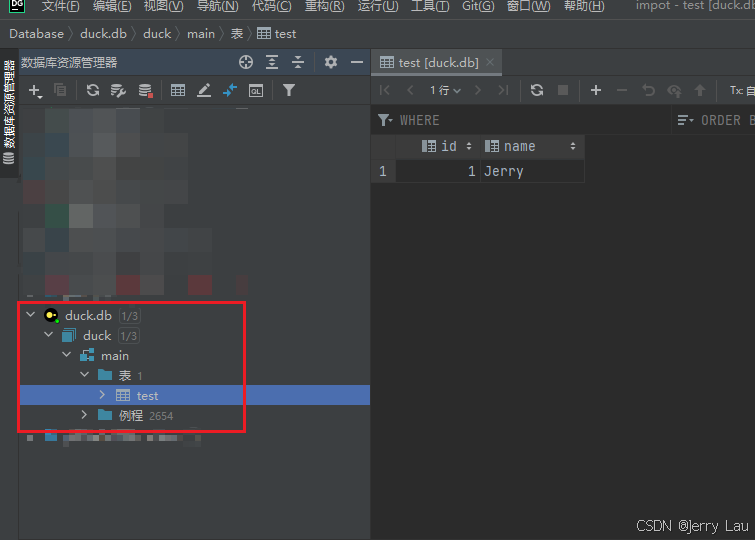
查询时可以看到这个内容已经存储进去了,同时也可以使用DG进行连接查看数据库数据,但注意一点:代码或者可视化工具两个不能同时查询,否则会报错文件正在被另一个线程使用中。
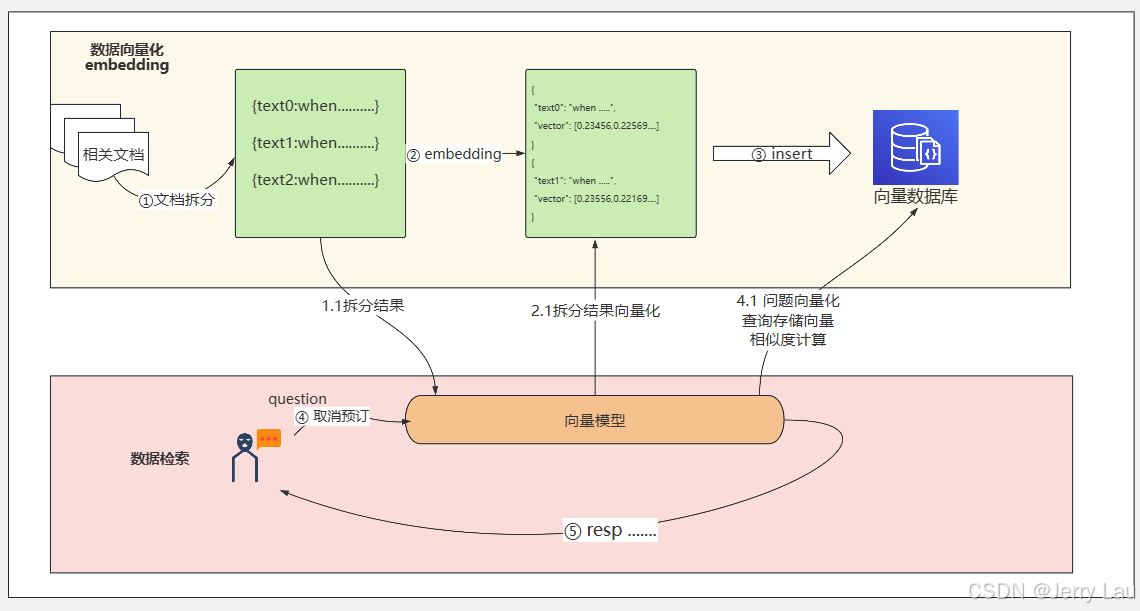
1.8.3 匹配向量
我们考虑做这样一件事情:
- 构造一个十分简单的人工客服,为用户提供预定以及取消预订服务
- 向量存储预定以及取消预订的相关条款
- 根据用户传入的提示词,进行匹配度筛选,返回给用户匹配的描述
在整个过程中流程类似于下图所示:
那么我们一起实现:
package com.jerry.langchain4jspringbootdemo.example.embedding;
import dev.langchain4j.community.model.dashscope.QwenEmbeddingModel;
import dev.langchain4j.community.store.embedding.duckdb.DuckDBEmbeddingStore;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.store.embedding.EmbeddingMatch;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
/**
* @version 1.0
* @Author jerryLau
* @Date 2025/3/31 8:35
* @注释 向量化示例
*/
public class EmBeddingExample2 {
public static void main(String[] args) {
DuckDBEmbeddingStore store = DuckDBEmbeddingStore.builder()
.filePath("langchain4j-springBoot-demo/src/main/java/com/jerry/langchain4jspringbootdemo/store/db/aiAssitant.db")
.tableName("message")
.build();
QwenEmbeddingModel embeddingModel = QwenEmbeddingModel.builder()
.apiKey("sk-xxxxxxxx")
// .modelName("text-embedding-v3")
// .baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
TextSegment segment = TextSegment.from("""
线上预约:
1. 选择预约时间段:在预约页面,您可以选择适合您的时间段进行预约。
2. 选择服务项目:根据您的需求,选择适合您的服务项目。
3. 填写预约信息:在预约页面,您需要填写您的姓名、联系方式、预约日期和预约时间等信息。
4. 提交预约:在填写完预约信息后,您需要点击提交按钮,提交您的预约信息。
5. 支付预约:在提交预约后,您需要支付预约费用15元人民币。
6. 预约成功:在支付预约成功后,您的预约将被成功提交。
""");
TextSegment segment2 = TextSegment.from("""
线上解除预约:
1. 选择预约记录:在预约记录页面,您可以选择需要解除预约的记录。
2. 确认取消:在确认取消页面,您需要确认是否取消预约,最晚取消时间在活动开始时间前12小时。
3. 在活动开始时间前12小时取消不收取手续费,否则按照预约费用的12%收取手续费。
4. 取消成功:在确认取消后,您的预约将被成功取消,费用将于7个工作日内原路返回至您的支付账户。
""");
Embedding content = embeddingModel.embed(segment).content();
Embedding content2 = embeddingModel.embed(segment2).content();
store.add(content, segment);
store.add(content2, segment2);
var queryEmbedding = embeddingModel.embed("取消预约").content();
var request = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
var relevant = store.search(request);
EmbeddingMatch<TextSegment> embeddingMatch = relevant.matches().get(0);
// Show results
System.out.println(embeddingMatch.score());//文本相似度
System.out.println(embeddingMatch.embedded().text()); //相似文本输出
}
}
输出结果为

那么到这一步,外接知识库的操作已经快完成了,只需要将获取到的“知识”在此投喂给ai,使得ai能够极大程度的更具你的“知识”提供回答即可,接着往下看。
2.RAG知识库集成
RAG知识库只需要在上述流程后中在添加一些流程即可,具体图解如下
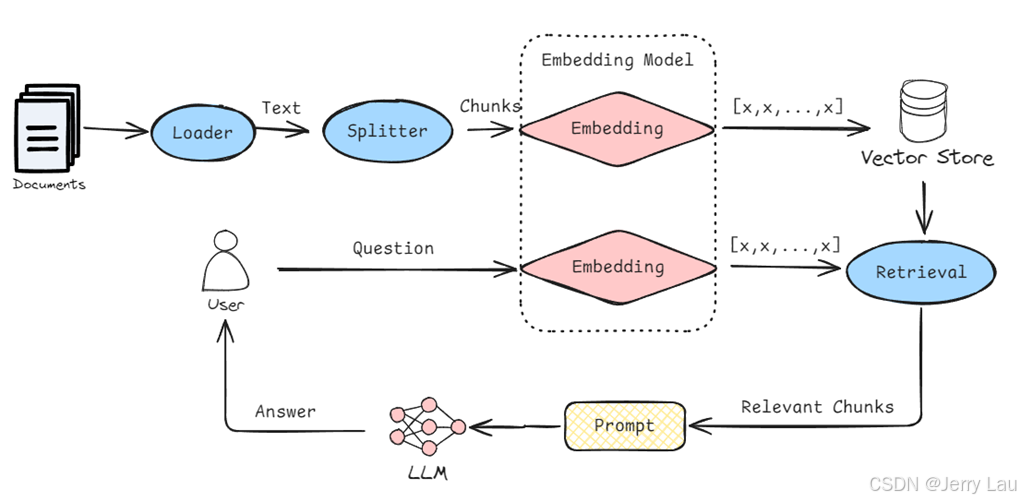
知识库的集成我们 大概要干这么几件事情:
- 获取一个pdf文件,做为我们外接的“知识库”,此处以一个java知识点pdf文件为例子
- 完成pdf文件读取
- 完成pdf文件内容拆分
- 拆分内容文本向量化
- 获取pdf拆分后的文本
- 进行文本向量化
- 向量化文本存储至向量数据库,此处我们以存储至DuckDB为例子
- 搭建javaAssistant,将存储的向量知识配置到ai模型上,进行询问java相关知识,查看输出结果
接下来 开干
2.1 文档读取与文档解析
优先集成langchain4j的文档读取, langchain4j提供了比较多的文档解析器,例如解析txt,excle,pdf等,需要的小伙伴官网自取
langchain4j文档读取|Document Loaders
langchain4j文档解析|Document Parsers
此处选择集成 Apache PDFBox 实现pdf文件的读取与解析
//pdf文档读取与解析
InputStream inputStream = RAGExample.class.getClassLoader().getResourceAsStream("java.pdf");
DocumentParser parser = new ApachePdfBoxDocumentParser();
Document document = parser.parse(inputStream);
System.out.println(document.text());
2.2文档拆分
文档拆分器的作用
在基于大语言模型(LLM)的应用中,文档拆分器用于将长文本分割成较小的片段(chunks),以解决以下问题:
- 突破 LLM 的输入长度限制(如 GPT-3 最大 4096 tokens)。
- 提高处理效率:分块后可以并行处理或逐步分析。
- 保留上下文:通过重叠分块(overlap)避免信息割裂。
langchain4j 支持的拆分器类型
langchain4j 的文档拆分器位于包 dev.langchain4j.data.document.splitter 中,主要分为以下类型:
| 分词器类型 | 匹配能力 | 适用场景 |
|---|---|---|
| DocumentByCharacterSplitter | 无符号分割 | 就是严格根据字数分隔(不推荐,会出现断句) |
| DocumentByRegexSplitter | 正则表达式分隔 | 根据自定义正则分隔 |
| DocumentByParagraphSplitter | 删除大段空白内容 | 处理连续换行符(如段落分隔)(\s*(?>\R)\s*(?>\R)\s* |
| DocumentByLineSplitter | 删除单个换行符周围的空白, 替换一个换行 | (\s*\R\s*) ●示例: ○输入文本:“This is line one.\n\tThis is line two.” ○使用 \s*\R\s* 替换为单个换行符:“This is line one.\nThis is line two.” |
| DocumentByWordSplitter | 删除连续的空白字符。 | \s+ ●示例: ○输入文本:“Hello World” ○使用 \s+ 替换为单个空格:“Hello World” |
| DocumentBySentenceSplitter | 按句子分割 | Apache OpenNLP 库中的一个类,用于检测文本中的句子边界。它能够识别标点符号(如句号、问号、感叹号等)是否标记着句子的末尾,从而将一个较长的文本字符串分割成多个句子。 |
因为我自己尝试过好几种拆分,比如段落拆分,行拆分,句子拆分,对于java.pdf来说不同的问题,存在不一样长度的答案,不太能把握住拆分的长度,拆分长度过长或者过短都会影响拆分结果,出现文本粘连的情况。
在我观察这个文本之后,便选择出了使用正则表达式的方式拆分,正则表达判定序号+"、"作为拆分片段开始,个人感觉拆分的结果还不错。
// 构造正则分割器(演示增强版正则)
DocumentByRegexSplitter splitter = new DocumentByRegexSplitter(
"(\\n\\d+、)", // 核心匹配模式
"\n", // 拼接保留换行
220, // 根据平均题目+答案长度调整
20 // 小幅度重叠避免切断句子
);
// 执行分割
String[] rawSegments = splitter.split(preprocessedText);
// 合并过小片段(如独立存在的答案行)
// List<TextSegment> merged = mergeSmallSegments(rawSegments, 100);
List<TextSegment> merged = new ArrayList<>();
for (int i = 0; i < rawSegments.length; i++) {
merged.add(TextSegment.from(rawSegments[i]));
}
2.3文本向量化
将拆分出来的小片段进行向量化,并存入DuckDB
QwenEmbeddingModel embeddingModel = QwenEmbeddingModel.builder()
.apiKey("sk-xxxxxxx")
.build();
List<Embedding> content = embeddingModel.embedAll(merged).content();
DuckDBEmbeddingStore store = DuckDBEmbeddingStore.builder()
.filePath("langchain4j-springBoot-demo/src/main/java/com/jerry/langchain4jspringbootdemo/store/db/javaInfo.db")
.tableName("message")
.build();
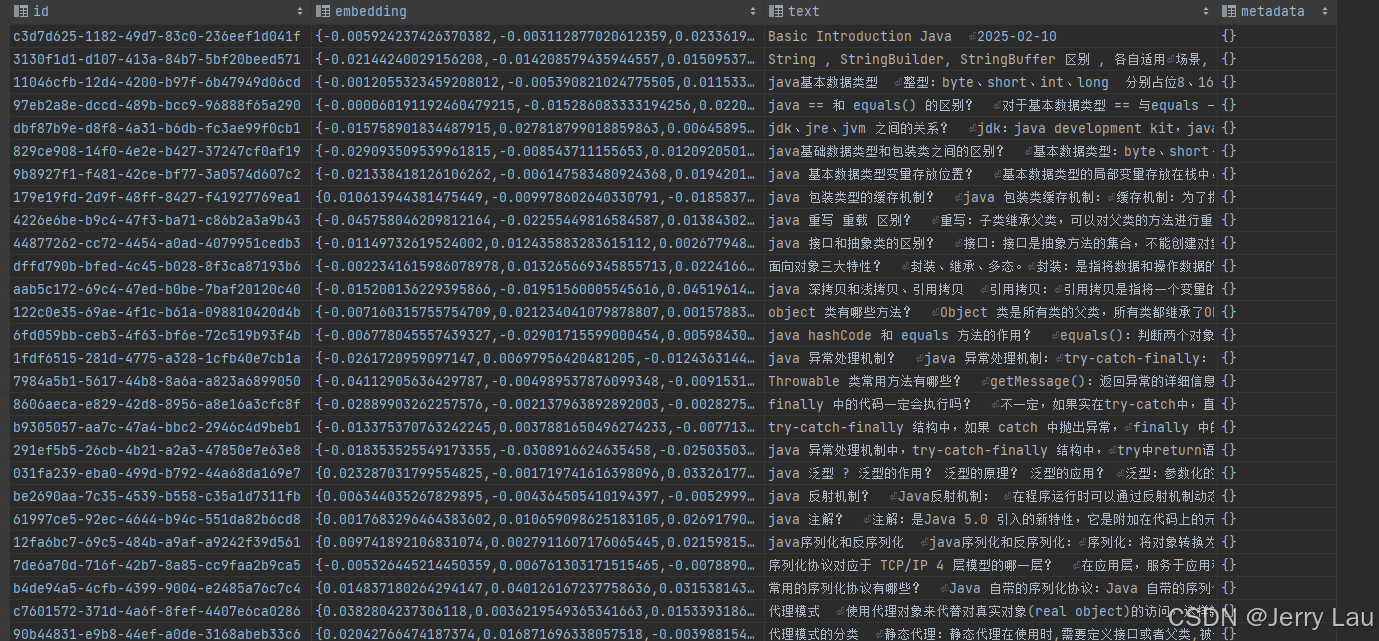
store.addAll(content, merged);
简单存储到DuckDB后数据大致是这个样子
2.4集成简单的问答
简单的输入问答,返回匹配到的相似度较高的答案
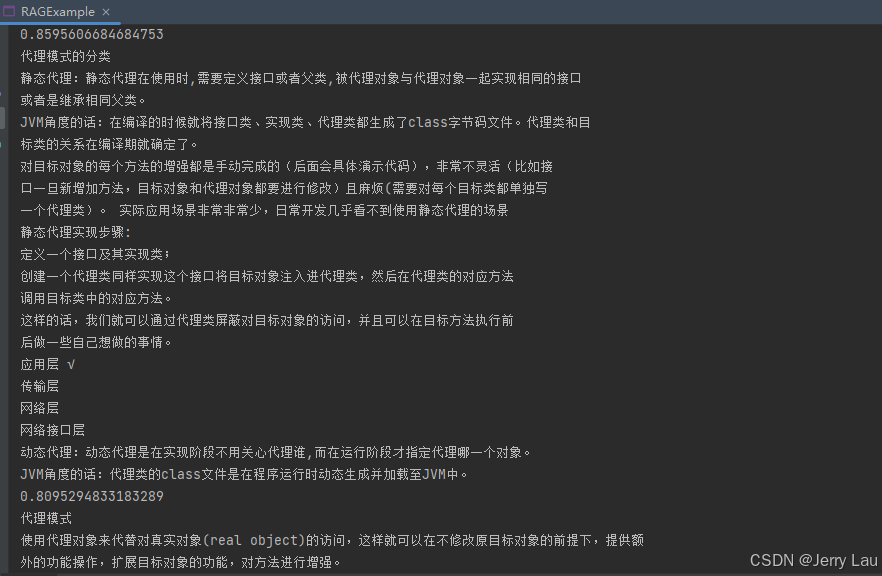
var queryEmbedding = embeddingModel.embed("帮我理解一下java 的 代理模式").content();
var request = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
// .maxResults(1)
.minScore(0.8)
.build();
var relevant = store.search(request);
List<EmbeddingMatch<TextSegment>> matches = relevant.matches();
matches.forEach(embeddingMatch -> {
System.out.println(embeddingMatch.score());
System.out.println(embeddingMatch.embedded().text());
});
2.5集体集成值SpringBoot项目中
再次配置一个新的javaAssistant,引入向量数据库,向量查询,为了简单演示 记忆暂时使用内存保存
package com.jerry.langchain4jspringbootdemo.config;
import com.jerry.langchain4jspringbootdemo.service.ToolService;
import dev.langchain4j.community.model.dashscope.QwenEmbeddingModel;
import dev.langchain4j.community.store.embedding.duckdb.DuckDBEmbeddingStore;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.chat.StreamingChatLanguageModel;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.TokenStream;
import dev.langchain4j.store.embedding.EmbeddingStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @version 1.0
* @Author jerryLau
* @Date 2025/3/26 13:33
* @注释 ai配置类 java 助手
*/
@Configuration
public class AIConfJava {
/***
* java助手接口
*/
public interface ChatAssistantJava {
/***
* 普通聊天 非隔离上下文
* @param question
* @return
*/
String chat(String question);
/***
* 流式输出 非隔离上下文
* @param question
* @return
*/
TokenStream streamChat(String question);
}
@Bean
public EmbeddingStore embeddingStore() {
DuckDBEmbeddingStore store = DuckDBEmbeddingStore.builder()
.filePath("langchain4j-springBoot-demo/src/main/java/com/jerry/langchain4jspringbootdemo/store/db/javaInfo.db")
.tableName("message")
.build();
return store;
}
@Bean
public QwenEmbeddingModel qwenEmbeddingModel() {
QwenEmbeddingModel embeddingModel = QwenEmbeddingModel.builder()
.apiKey("sk-xxxxxxx")
.build();
return embeddingModel;
}
/***
* 注入聊天服务 非隔离上下文
* @param chatLanguageModel
* @param streamingChatLanguageModel
* @return
*/
@Bean
public ChatAssistantJava chatAssistantJava(ChatLanguageModel chatLanguageModel,
StreamingChatLanguageModel streamingChatLanguageModel,
EmbeddingStore embeddingStore,
QwenEmbeddingModel qwenEmbeddingModel,
ToolService toolService) {
//使用简单的ChatMemory - MessageWindowChatMemory来保存聊天记录
MessageWindowChatMemory messageWindowChatMemory = MessageWindowChatMemory.builder()
.maxMessages(10).build(); //最多保存10条记录
//设置向量库
EmbeddingStoreContentRetriever retriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore) //向量库 duckdb
.embeddingModel(qwenEmbeddingModel)//向量化模型
.minScore(0.8) //匹配度80%以上
.build();
ChatAssistantJava build = AiServices.builder(ChatAssistantJava.class)
.chatLanguageModel(chatLanguageModel)
.streamingChatLanguageModel(streamingChatLanguageModel)
.chatMemory(messageWindowChatMemory)
// .tools(toolService)
.contentRetriever(retriever)
.build();
return build;
}
}
简单创建新的Controller进行接口请求
package com.jerry.langchain4jspringbootdemo.controller;
import com.jerry.langchain4jspringbootdemo.config.AIConf;
import com.jerry.langchain4jspringbootdemo.config.AIConfJava;
import com.jerry.langchain4jspringbootdemo.service.AiService;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.model.chat.response.ChatResponse;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
/**
* @version 1.0
* @Author jerryLau
* @Date 2025/3/20 10:54
* rag 例子 接口
* @注释
*/
@RestController
@RequestMapping("/ai/rag")
public class LangChain4jRagController {
@Resource
private AIConfJava.ChatAssistantJava chatAssistantJava;
@GetMapping("/doAsk")
public String langChain4j(@RequestParam(defaultValue = "帮我理解一下 代理模式") String question) {
return chatAssistantJava.chat(question);
}
}
分别使用先前的普通调用及RAG知识库调用接口,询问“ArrayList 和 Array 的区别”这一问题
首先展示一下java.pdf中对于这一问题是怎么描述的

对比下图,左边普通的调用时没有参考任何知识点,只是将这个问题解答了出来,右边通过RAG知识库,AI的解答中大致上是通过上面知识库中的大纲进行的描述解答,可以清楚的看到"ArrayList是一个泛型类"等字眼。
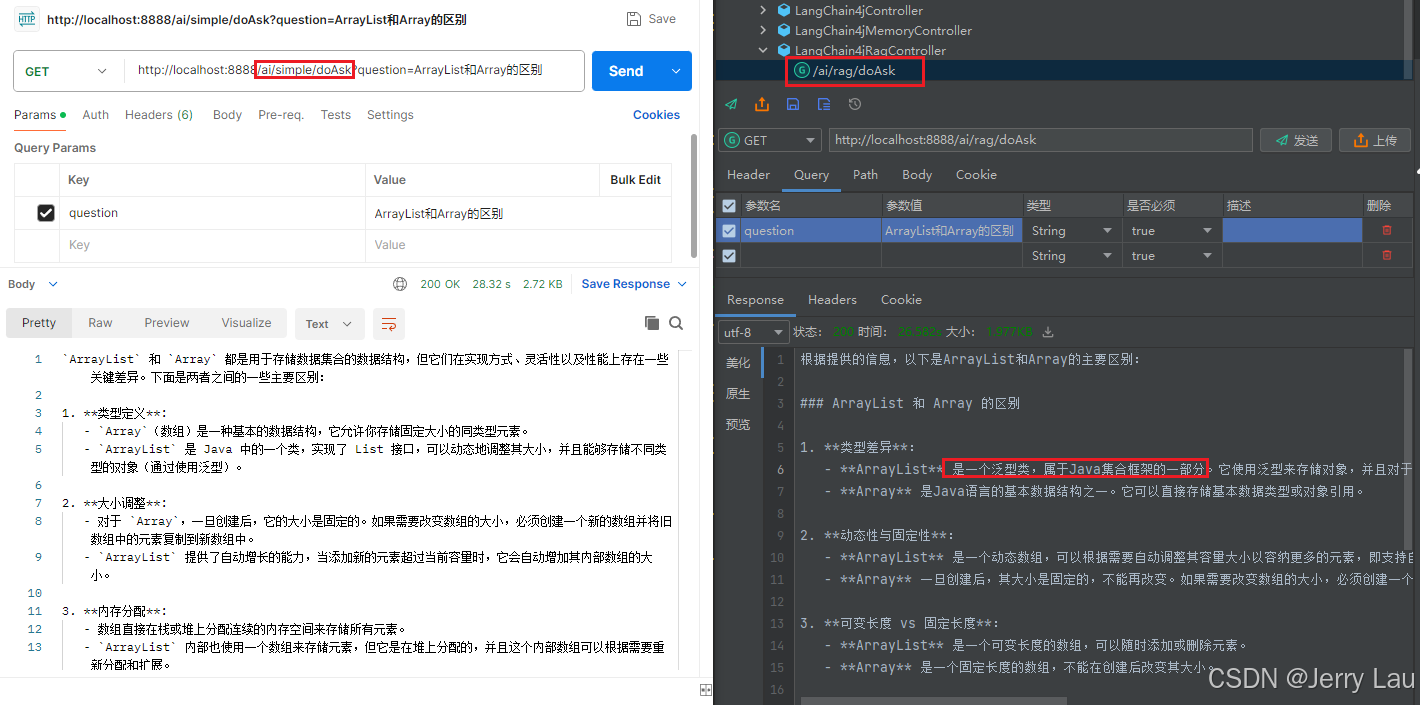
正常普通的调用返回
`ArrayList` 和 `Array` 都是用于存储数据集合的数据结构,但它们在实现方式、灵活性以及性能上存在一些关键差异。下面是两者之间的一些主要区别: 1. **类型定义**: - `Array`(数组)是一种基本的数据结构,它允许你存储固定大小的同类型元素。 - `ArrayList` 是 Java 中的一个类,实现了 List 接口,可以动态地调整其大小,并且能够存储不同类型的对象(通过使用泛型)。 2. **大小调整**: - 对于 `Array`,一旦创建后,它的大小是固定的。如果需要改变数组的大小,必须创建一个新的数组并将旧数组中的元素复制到新数组中。 - `ArrayList` 提供了自动增长的能力,当添加新的元素超过当前容量时,它会自动增加其内部数组的大小。 3. **内存分配**: - 数组直接在栈或堆上分配连续的内存空间来存储所有元素。 - `ArrayList` 内部也使用一个数组来存储元素,但它是在堆上分配的,并且这个内部数组可以根据需要重新分配和扩展。 4. **访问速度**: - 由于数组提供的是基于索引的快速随机访问,所以访问特定位置上的元素非常快。 - `ArrayList` 同样支持基于索引的快速访问,因为底层实现也是基于数组的。 5. **插入与删除操作**: - 在数组中插入或删除元素通常比较低效,特别是对于大型数组,因为这可能涉及到移动大量元素以保持其他元素的位置不变。 - `ArrayList` 虽然提供了方便的方法来进行插入和删除操作,但在列表中间进行这些操作仍然可能导致效率问题,因为它也需要移动元素。不过,在列表末尾添加或移除元素相对更高效。 6. **功能性和便利性**: - 数组提供了最基本的功能,如访问、遍历等。 - `ArrayList` 除了基础功能外,还提供了更多高级功能,比如排序、搜索、迭代器支持等,使得处理集合更加方便。 7. **多线程安全性**: - 标准的数组不是线程安全的。 - 基础的 `ArrayList` 实现也不是线程安全的。如果需要在多线程环境中使用,可以考虑使用 `Collections.synchronizedList()` 方法或者选择 `CopyOnWriteArrayList` 类。 总之,选择使用 `ArrayList` 还是 `Array` 取决于具体的应用场景和需求。如果你需要一个固定大小的简单集合并且关注性能,那么数组可能是更好的选择;而如果你希望拥有更多的灵活性以及额外的功能,则 `ArrayList` 会更适合。
外界知识库后的调用返回:
根据提供的信息,以下是ArrayList和Array的主要区别: ### ArrayList 和 Array 的区别 1. **类型差异**: - **ArrayList** 是一个泛型类,属于Java集合框架的一部分。它使用泛型来存储对象,并且对于基本数据类型(如 `int`, `char` 等),需要将其转换为对应的包装类(例如 `Integer`, `Character`)才能存储。 - **Array** 是Java语言的基本数据结构之一。它可以直接存储基本数据类型或对象引用。 2. **动态性与固定性**: - **ArrayList** 是一个动态数组,可以根据需要自动调整其容量大小以容纳更多的元素,即支持自动扩容。 - **Array** 一旦创建后,其大小是固定的,不能再改变。如果需要改变数组的大小,必须创建一个新的数组并将旧数组中的元素复制到新数组中。 3. **可变长度 vs 固定长度**: - **ArrayList** 是一个可变长度的数组,可以随时添加或删除元素。 - **Array** 是一个固定长度的数组,不能在创建后改变其大小。 4. **操作方法的支持**: - **ArrayList** 提供了丰富的内置方法来进行动态添加、删除和访问元素,如 `add()`, `remove()`, `get()`, `set()` 等。 - **Array** 不提供这些内置方法。对数组的操作通常需要通过下标遍历进行,例如手动编写代码来实现添加和删除元素。 ### 总结 - **类型**:ArrayList是泛型类,需要将基本数据类型转换为包装类;Array可以直接存储基本数据类型。 - **动态性**:ArrayList是动态数组,支持自动扩容;Array是静态数组,大小固定。 - **长度**:ArrayList是可变长度的数组;Array是固定长度的数组。 - **操作方法**:ArrayList提供了丰富的内置方法进行动态操作;Array没有这些内置方法,需要手动处理。 希望这些信息能帮助你更好地理解ArrayList和Array之间的区别。如果你还有其他问题,请随时告诉我!
那么截至到目前位置,RAG知识库的集成完成:✿✿ヽ(°▽°)ノ✿
码字不易,各位观众老爷如果喜欢,别忘了一键三连,支持一波,如果描述中有不当的地方,还请各位大佬指正

















 2291
2291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









