









这两天用Python来实现手写数字识别,刚开始用原始数据进行训练,结果预测结果都是同一个类别,全部是对应数字1。正确率也只有10%左右,下面是代码及运行结果截图:
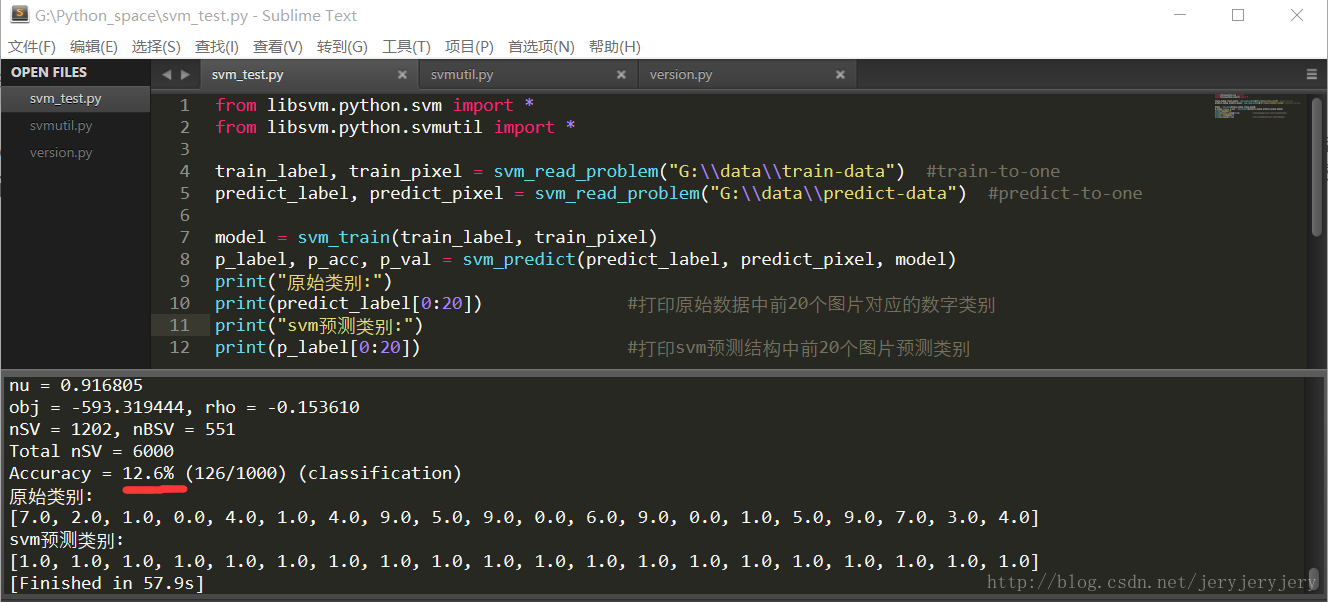
预测结果都是数字1。
数据归一化是指将特征值从一个大范围映射到[0,1]或者[-1,1],如果原始值都是正数,则建议选择映射到[0,1];如果原始值有正数又有负数,则建议映射到[-1,1];具体情况需要具体分析。映射到[0,1]的实现是:
new_value=value−min_valuemax_value−min_value
这样就能实现从原来的范围映射到[0,1]之间。
libsvm中提供了数据归一化工具,就是svm-scale这个工具。如果你的数据文件已经满足了svm的格式要求,即 label1:value12:value2.... 这种格式,那么在window平台下,你可以直接调用libsvm\windows\svm-scale.exe文件来进行归一化操作。具体步骤是在cmd命令行中进入到svm-scale.exe所在文件夹,然后运行svm-scale来实现归一化。svm-scale的语法截图如下:
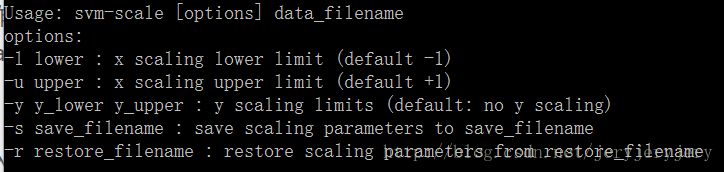
其中-l 指定下界,-u指定上界,-s指定保存scale参数文件路径,-r源文件路径
下面以数据源train.txt为例,将其归一化到[0,1],并存入到train-to-one.txt中,语句截图如下:

因为手写数字图片是由一系列的像素点组成的,像素值从0到255,所以可以让每一个像素值除以255,从而实现映射。可以调用svm-scale来实现,也可以直接编写java代码来实现,然后再以归一化之后的数据进行训练模型并预测,其代码和截图如下:
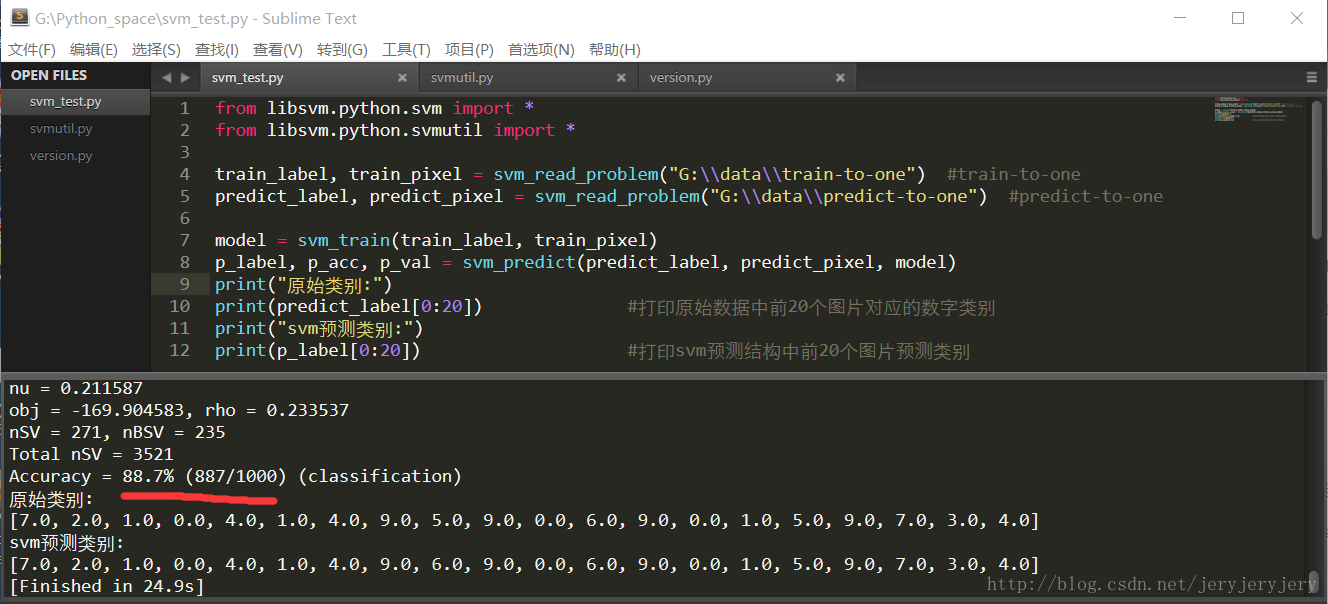
可以看出,准确率和速率明显提高了,不会出现仅仅只有一类的问题。但是其中的原理,本人现在还不知道,等我理解了再解释吧!














 5266
5266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









