







MapReduce工作机制
1. 剖析MapReduce的工作运行机制

2. 失败
Tasktracker失败:
失败检测机制,是通过心跳进行检测。主要有:
(1) 超时:mapred.tasktracker.expiry.interval属性设置,单位毫秒
(2) 黑名单机制:失败任务数远远高于集群的平均失败任务数。
失败处理机制:
(1) 从等待任务调度的tasktracker池中移除
(2) 未完成的作业,重新运行和调度
(3) 黑名单中的tasktracker通过重启从jobtracker中移出。
JobTracker失败:
最严重的一种,目前Hadoop没有处理jobtracker失败的机制(单点故障)
3. 作业的调度
早期版本:先进先出算法(FIFO)
随后:加入设置作业优先级的功能(mapred.job.priority属性、JobClient的setJobPriority())
不支持抢占(FIFO算法决定)
默认调度器:FIFO;用户调度器:Fair Scheduler、Capacity Scheduler
Fair Scheduler(公平调度器)
目的:让每个用户公平的共享集群能力
特点:
(1) 支持抢占
(2) 短的作业将在合理的时间内完成
使用方式:
属于后续模块,需要专门调整
需要将其JAR文件放在Hadoop的类路径(从Hadoop的contrib/fairscheduler目录复制到lib目录)
设置mapred.jobtracker.taskScheduler属性:mapred.jobtracker.taskScheduler= org.apache.hadoop.mapred.FairScheduler
Capacity Scheduler
针对多用户的调度
允许用户或组织为每个用户或组织模拟一个独立的使用FIFO Scheduling的MapReduce集群。
4. Shuffle和排序
Shuffle:将map输出作为输入传给reducer(系统执行排序的过程)
MapReduce的核心部分,属于不断被优化和改进的代码库的一部分。
Map端:
环形内存缓冲区:
100MB:io.sort.mb 阀值:io.sort.spill.percent80% mapred.local.dir : 作业特定子目录
超过阀值则写入磁盘。如果写入过程中缓冲区填满,则堵塞直到写磁盘完成。
io.sort.factor:一次最多合并多少流,默认10
压缩:mapred.compress.map.output
Tracker.http.threads:针对每个tasktracker,而不是针对每个map任务槽,默认40;在运行大型作业的大型集群上,可以根据需要而增加。
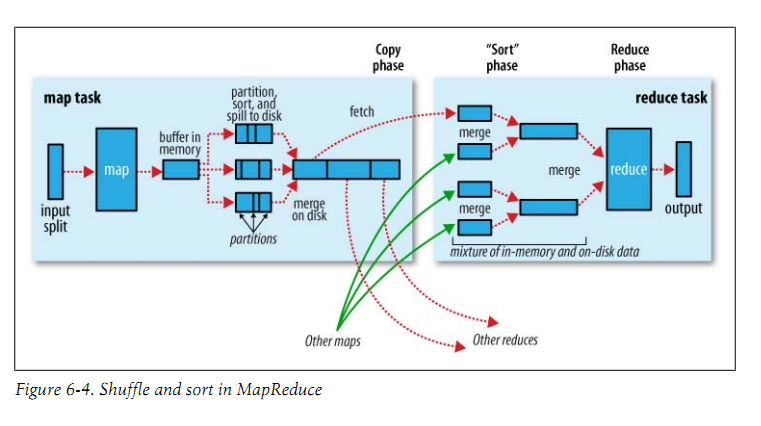
Reduce端
Map输出文件位于运行map任务的tasktracker的本地磁盘;reduce输出并不这样
复制阶段(copyphase):mapred.reduce.parallel.copies ,默认5;设置多少并行获取map输出
排序、合并、合并印子、合并的次数
配置的调优:重要章节
1、给shuffle过程尽量多提供内存空间(猜测原因:避免写入磁盘、提高性能???)。所以,map和reduce应尽量少用内存
2、运行map任务和reduce任务的JVM,其内存大小在mapred.child.java.opts属性设置,应该尽量大。
3、在map端,可以通过避免多次溢出写磁盘来获取最佳性能
4、在reduce端,中间的数据全部驻留在内存时,就能获得最佳性能。
整个调优的思路是:减少磁盘读写(使用内存)、减少数据大小(压缩)
5. 任务的执行
推测执行:
提取为可能出错的任务建立一个备份任务,做好预案。
进行冗余,牺牲性能作为代价。
解决方式:在集群上关闭此选项,但根据个别作业需要再开启。
问题:推测执行选项是对整个集群还是作业???
答案:可以针对某个map和reduece开启,有两个选项
mapred.map.tasks.speculative.execution
mapred.reduce.tasks.speculative.execution
任务JVM重用:
对短时间执行的任务,启用JVM重用,避免启动JVM(1秒左右)的消耗。
mapred.job.reuse.jvm.num.tasks:指定给定作业每个JVM运行的任务的最大数,默认为1
-1则表示同一作业的任务都可以共享同一个JVM
JobConf中的setNumTaskToExecutePerJvm()来设置。
这个设置是针对作业粒度的。
重用是指JVM空闲后可以被分配给其他任务使用。
另一个好处:各个任务之间状态共享;共享数据;
跳过坏记录:
处理坏记录的最佳位置在于mapper和reducer代码。
skipping mode:
出现失败,报告给tasktracker,重新执行后,跳过该记录。
只有在任务失败两次后才会启用skippingmode
流程如下:
(1) 任务失败
(2) 任务失败
(3) 开启skipping mode。任务失败,但是失败记录由tasktracker保存
(4) 仍然启用skipping mode。任务继续运行,但跳过上一次尝试中失败的坏记录。
缺点:每次都只能检测一条坏记录,所以对多条坏记录的话,这个就是个灾难。。。。。
可以通过设置taskattempt的最多次数来设置:mapred.map.max.attemps mapred.reduce.max.attemps
坏记录保存在:_logs/skip
Hadoop fs –text 诊断
任务执行环境:
1、 Mapper和reducer中提供一个 configure() 方法实现。
2、 Streaming环境变量
3、 任务附属文件
防止文件覆盖
将任务写到特定的临时文件夹({mapred.output.dir}/_temporary/${mapred.task.id}),任务完成后,将该目录中的内容复制到作业的输出目录(${mapred.output.dir})。
Hadoop提供了方式便于程序开发使用:
检索mapred.work.output.dir检索
调用FileOutputFormat的getWorkOutputPath()静态方法得到表示工作目录的Path对象。
--------------------------------------------------------------------------------------------------------------------
作者:CNZQS|JesseZhang 个人博客:CNZQS(http://www.cnzqs.com)
版权声明:除非注明,文章均为原创,可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本声明
--------------------------------------------------------------------------------------------------------------------















 2831
2831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









