






作者:杨思达zzzz
链接:https://www.zhihu.com/question/38499534/answer/147150281
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
 其实也很明显,通过求偏导我们就能看到
其实也很明显,通过求偏导我们就能看到

这样就算深度很深,梯度也不会消失了
<img src="https://pic4.zhimg.com/50/v2-543d8c86899ec03d623e054b9d100cdb_hd.jpg" data-rawwidth="600" data-rawheight="370" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic4.zhimg.com/v2-543d8c86899ec03d623e054b9d100cdb_r.jpg"> <img src="https://pic1.zhimg.com/50/v2-d0293f59397ee7158dfc57eae6f4f477_hd.jpg" data-rawwidth="600" data-rawheight="452" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic1.zhimg.com/v2-d0293f59397ee7158dfc57eae6f4f477_r.jpg">
<img src="https://pic1.zhimg.com/50/v2-d0293f59397ee7158dfc57eae6f4f477_hd.jpg" data-rawwidth="600" data-rawheight="452" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic1.zhimg.com/v2-d0293f59397ee7158dfc57eae6f4f477_r.jpg">
链接:https://www.zhihu.com/question/38499534/answer/147150281
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
用一句话解释就是,深度网络容易造成梯度在back propagation的过程中消失,导致训练效果很差,而深度残差网络在神经网络的结构层面解决了这一问题,使得就算网络很深,梯度也不会消失。
关于梯度消失的问题,详见这篇文章
http://blog.csdn.net/superCally/article/details/55671064
我们知道,对于神经网络来讲,我们需要通过反向传播来对网络的权重进行调整
就像这样

但是这个时候,如果网络很深很深,就会出现这样的情况




这个时候再做back propagation求偏导的话,就是

这个偏导就是我们求的gradient,这个值本来就很小,而且再计算的时候还要再乘stepsize,就更小了所以通过这里可以看到,梯度在反向传播过程中的计算,如果N很大,那么梯度值传播到前几层的时候就会越来越小,也就是梯度消失的问题
那DRN是怎样解决这个问题的呢?
它在神经网络结构的层面解决了这个问题它将基本的单元改成了这个样子
其实也很明显,通过求偏导我们就能看到
这样就算深度很深,梯度也不会消失了
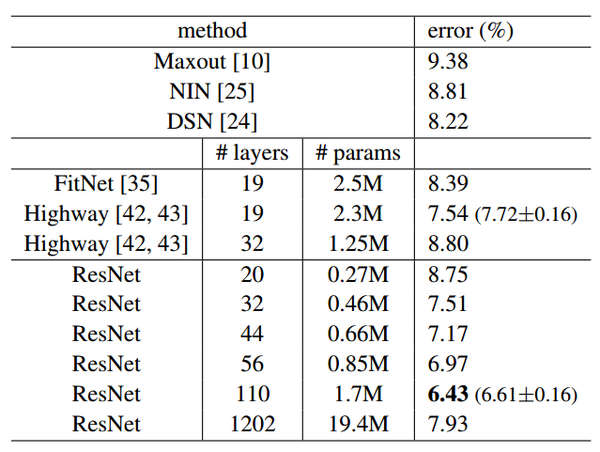
当然深度残差这篇文章最后的效果好,是因为还结合了调参数以及神经网络的其他的细节,这些也很重要,不过就不是这里我们关心的内容了可以看到,对于相同的数据集来讲,残差网络比同等深度的其他网络表现出了更好的性能
<img src="https://pic4.zhimg.com/50/v2-543d8c86899ec03d623e054b9d100cdb_hd.jpg" data-rawwidth="600" data-rawheight="370" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic4.zhimg.com/v2-543d8c86899ec03d623e054b9d100cdb_r.jpg">
<img src="https://pic1.zhimg.com/50/v2-d0293f59397ee7158dfc57eae6f4f477_hd.jpg" data-rawwidth="600" data-rawheight="452" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic1.zhimg.com/v2-d0293f59397ee7158dfc57eae6f4f477_r.jpg">















 8442
8442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









