









在看过一些基本资料之后进行的小总结
大佬绕道
1、残差的数学概念
是指估计值与实际值直接的差,如果存在一个映射f(x)=b,x=x0时,则b-f(x0)则为残差,x-x0为误差
2、残差网络
对于传统的CNN网络,简单的增加网络的深度,容易导致梯度消失和爆炸。针对梯度消失和爆炸的解决方法一般是正则初始化(normalized initialization)和中间的正则化层(intermediate normalization layers),但是这会导致另一个问题,退化问题,随着网络层数的增加,在训练集上的准确率却饱和甚至下降了。
按照常理更深层的网络结构的解空间是包括浅层的网络结构的解空间的,也就是说深层的网络结构能够得到更优的解,性能会比浅层网络更佳。但是实际上并非如此,深层网络无论从训练误差或是测试误差来看,都有可能比浅层误差更差。
就引出了退化问题,当网络层数加深,我们的训练损失会变得更大(训练集与测试集的损失都增大,所以不是过拟合的问题),既然深层网络相比于浅层网络具有退化问题,那么是就保留深层网络的深度,同时避免退化问题。就出现了残差网络
我们在网络上经常能见到下面一个图片,就是一个简单的残差块,由残差块堆叠而成的就是残差网络。
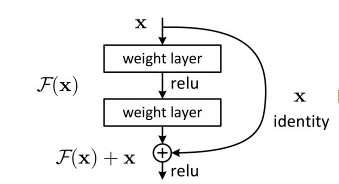
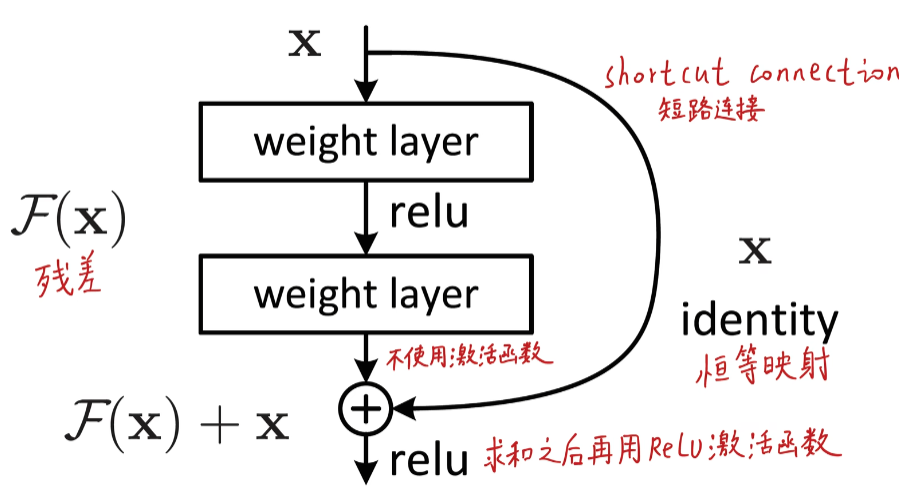
关于残差块,网上的说法有很多,我这里从自己的角度简单理解一下,我们的输入 x x x经过两层网络之后(在第二层激活层relu函数之前)的输出是 F ( x ) F(x) F(x),但我们不能保证经过这两层网络之后是否会有信息的丢失(如果层数越多可能信息损失的越多),如果层数逐渐加上,信息的损失会导致我们无法继续后面的训练,也会影响到权重的更新,所以我们直接加上输入的 x x x作为理想输出,将这个输出记为 H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x,这样就算信息有所损失,那么至少保证的理想输出。
在这种情况下,优化问题可以看做 F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x,令 F ( x ) = 0 F(x)=0 F(x)=0这样的优化较为简单,这也是残差这个叫法的由来。
也就是说,我们不需要去拟合真正的分布,我们只需要拟合在原来的输入恒等映射上修改残差 F ( x ) F(x) F(x),最坏使得 F ( x ) = 0 F(x)=0 F(x)=0,就是基本没有增益。但不至于有损失
换一种理解方式也是差不多的,就不过多赘述了,从图片上帮助理解
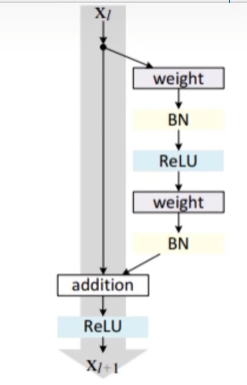
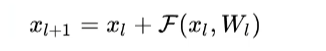
总得来说,我们一般会在深层网络中堆叠多个残差块,保证网络深的同时(更好的提升特征提取性能,但是过深也会导致过拟合问题)解决网络的退化问题。
3、残差网络解决退化问题的原因

这里可以看看最后推荐的几个链接,b站的视频讲解说的很清晰















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









