







最近在扫荡《推荐系统实践》,顺便把书中的代码实实在在的实现一遍,也是为了更好的理解算法,为了进一步深入
推荐系统打好基础。
下面是我最近实现的基于图的推荐算法,Java的。原理自己去看书。代码参考了http://blog.csdn.net/pi9nc/article/details/27483249
代码还有许多需要改进的地方,因忙没时间进行优化了。。。注释也没加多少。。。
另外代码中的排序部分,用的是堆排序,从一大堆无序数据中选出最大的前10个、或者前20个,堆排序是效率最高的,首选堆排序(在学《数据结构》书的时候,记得有这么一道选择题来着)。堆排序代码稍后上传。
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Random;
import java.util.Set;
public class PersonalRank {
HashMap<Integer,Set<Integer>> trainset=new HashMap<Integer,Set<Integer>>();
HashMap<Integer,Set<Integer>> testset=new HashMap<Integer,Set<Integer>>();
HashMap<Integer,Set<Integer>> inverse_table=new HashMap<Integer,Set<Integer>>();
HashMap<Integer,Integer> movie_popular=new HashMap<Integer,Integer>();
int i=0;
int trainset_length;
int testset_length;
int user_sim_mat[][];
double user_simlarity[][];
int movie_count=0;
List<Rank> recommendedMoviesList=null;
List<Ralated_user> ralatedUsersList=null;
int k=0;
int n=10;
Random random=new Random(0);
public void generate_dataset(int pivot) throws IOException{
File file=new File("E:\\workspace\\ml-1m\\ratings.dat");
if(!file.exists()||file.isDirectory())
throw new FileNotFoundException();
BufferedReader br=new BufferedReader(new FileReader(file));
String temp=null;
while ((temp=br.readLine())!=null) {
String[] content=temp.replaceAll("\n\t", "").split("::");
if(random.nextInt(8)==pivot){
if(testset.containsKey(Integer.parseInt(content[0]))){
HashSet<Integer> set =(HashSet<Integer>) testset.get(Integer.parseInt(content[0]));
set.add(Integer.parseInt(content[1]));
testset.put(Integer.parseInt(content[0]),set);
}else{
Set<Integer> set=new HashSet<Integer>();
set.add(Integer.parseInt(content[1]));
testset.put(Integer.parseInt(content[0]),set);
}
testset_length++;
}else{
if(trainset.containsKey(Integer.parseInt(content[0]))){
HashSet<Integer> set =(HashSet<Integer>) trainset.get(Integer.parseInt(content[0]));
set.add(Integer.parseInt(content[1]));
trainset.put(Integer.parseInt(content[0]),set);
}else{
Set<Integer> set=new HashSet<Integer>();
set.add(Integer.parseInt(content[1]));
trainset.put(Integer.parseInt(content[0]),set);
}
trainset_length++;
}
i++;
if (i%100000 == 0)
System.out.println("已装载"+i+"文件");
}
System.out.println("测试集和训练集分割完成,测试集长度:"+testset_length+",训练集长度:"+trainset_length);
}
// build inverse table for item-users
// key=movieID, value=list of userIDs who have seen this movie
public void calc_user_sim(){
for(int obj : trainset.keySet()){
Set<Integer> value = trainset.get(obj );
Iterator<Integer> it=value.iterator();
while(it.hasNext())
{
int o=it.next();
if(inverse_table.containsKey(o)){
Set<Integer> set=inverse_table.get(o);
set.add(obj);
inverse_table.put(o,set);
}else {
Set<Integer> set=new HashSet<Integer>();
set.add(obj);
inverse_table.put(o,set);
}
// count item popularity at the same time
if(!movie_popular.containsKey(o)){
movie_popular.put(o,1);
}else {
movie_popular.put(o,movie_popular.get(o)+1);
}
}
}
System.out.println("inverse——table创建成功");
//建立反转表的目的是方便建立co-rated movies 矩阵
movie_count=inverse_table.size();
System.out.println("movie number is"+movie_count);
}
double alpah=0.6;
public void personalRank(int root,int max_step){
double rank1[]=new double[trainset.size()+1];
double rank2[]=new double[3953];
double temp1[]=new double[trainset.size()+1];
double temp2[]=new double[3953];
rank1[root]=1;
for(int k=0;k<max_step;k++){ //遍历trainSet
for(int i=0;i<temp1.length;i++) temp1[i]=0.0;
for(int j=0;j<temp2.length;j++) temp2[j]=0.0;
Iterator<Integer> u=trainset.keySet().iterator();
while(u.hasNext()){
int uu=u.next();
Set<Integer> movies=trainset.get(uu);
Iterator<Integer> it=movies.iterator();
while(it.hasNext()){
temp2[it.next()]+=alpah*rank1[uu]/movies.size();
}
}
Iterator<Integer> m=inverse_table.keySet().iterator();
while(m.hasNext()){
int mm=m.next();
Set<Integer> us=inverse_table.get(mm);
Iterator<Integer> it=us.iterator();
while(it.hasNext()){
temp1[it.next()]+=alpah*rank2[mm]/us.size();
}
}
temp1[root]+=1-alpah;
for(int i=0;i<temp1.length;i++)
rank1[i]=temp1[i];
for(int i=0;i<temp2.length;i++)
rank2[i]=temp2[i];
}
recommendedMoviesList=new ArrayList<Rank>();
Set<Integer> watched_movies=trainset.get(root);
for(int i=0;i<rank2.length;i++){
if(watched_movies.contains(i)||rank2[i]==0.0)
continue;
Rank r=new Rank();
r.setMovie(i);
r.setSum_simlatrity(rank2[i]);
recommendedMoviesList.add(r);
}
Heapsort ss=new Heapsort();
ss.sort(recommendedMoviesList, n);
}
public void evaluate(){
int rec_count=0;
int test_count=0;
int hit=0;
double popularSum=0;
Set<Integer> all_rec_movies=new HashSet<Integer>();
Iterator<Integer> it=trainset.keySet().iterator();
while(it.hasNext()){
int user=it.next();
if(user%5==0)
System.out.println("已经推荐了"+user+"个用户");
Set<Integer> test_movies=testset.get(user);
personalRank(user, 20);
if(recommendedMoviesList!=null&&test_movies!=null){
if(recommendedMoviesList.size()<n) n=recommendedMoviesList.size();
for(int i=0;i<n;i++){
Rank rec_movie=recommendedMoviesList.get(i);
if(test_movies.contains(rec_movie.getMovie())){
hit++;
}
all_rec_movies.add(rec_movie.getMovie());
//all_rec_movies.add(rec_movie);
popularSum+=Math.log(1+movie_popular.get(rec_movie.getMovie()));
// rec_count+=1;
}
rec_count+=n;
//rec_count+=recommendedMoviesList.size();
test_count+=test_movies.size();
}
}
double precision=hit/(1.0*rec_count);
double recall=hit/(1.0*test_count);
double coverage=all_rec_movies.size()/(1.0*movie_count);
double popularity=popularSum/(1.0*rec_count);
System.out.println("precision=%"+precision*100+"\trecall=%"+recall*100+"\tcoverage=%"+coverage*100+"\tpopularity="+popularity);
}
public static void main(String[] args) throws IOException {
PersonalRank ss=new PersonalRank();
ss.generate_dataset(3);
ss.calc_user_sim();
Set<Integer> set=new HashSet<Integer>();
set.add(5);
set.add(10);
set.add(20);
set.add(40);
set.add(80);
set.add(160);
Iterator<Integer> it=set.iterator();
while(it.hasNext()){
ss.k=it.next();
ss.evaluate();
}
}
}
运行结果:
precision=%15.159893404397067
recall=%7.285155155715989
coverage=%2.8393726338561387
popularity=7.710734638003809

和原书中的运行结果大致相近:

我选的alpha是0.6。
运行时间很长啊,等了4个多小时才出结果,正如原书作者说的,PersonalRank算法时间复杂度非常高。
接下来是对算法时间复杂度高的解决办法:1.减少迭代次数,在收敛之前就停止,2.用矩阵的办法。
下面是我对原书中的矩阵办法的理解,请看图片中的笔记:
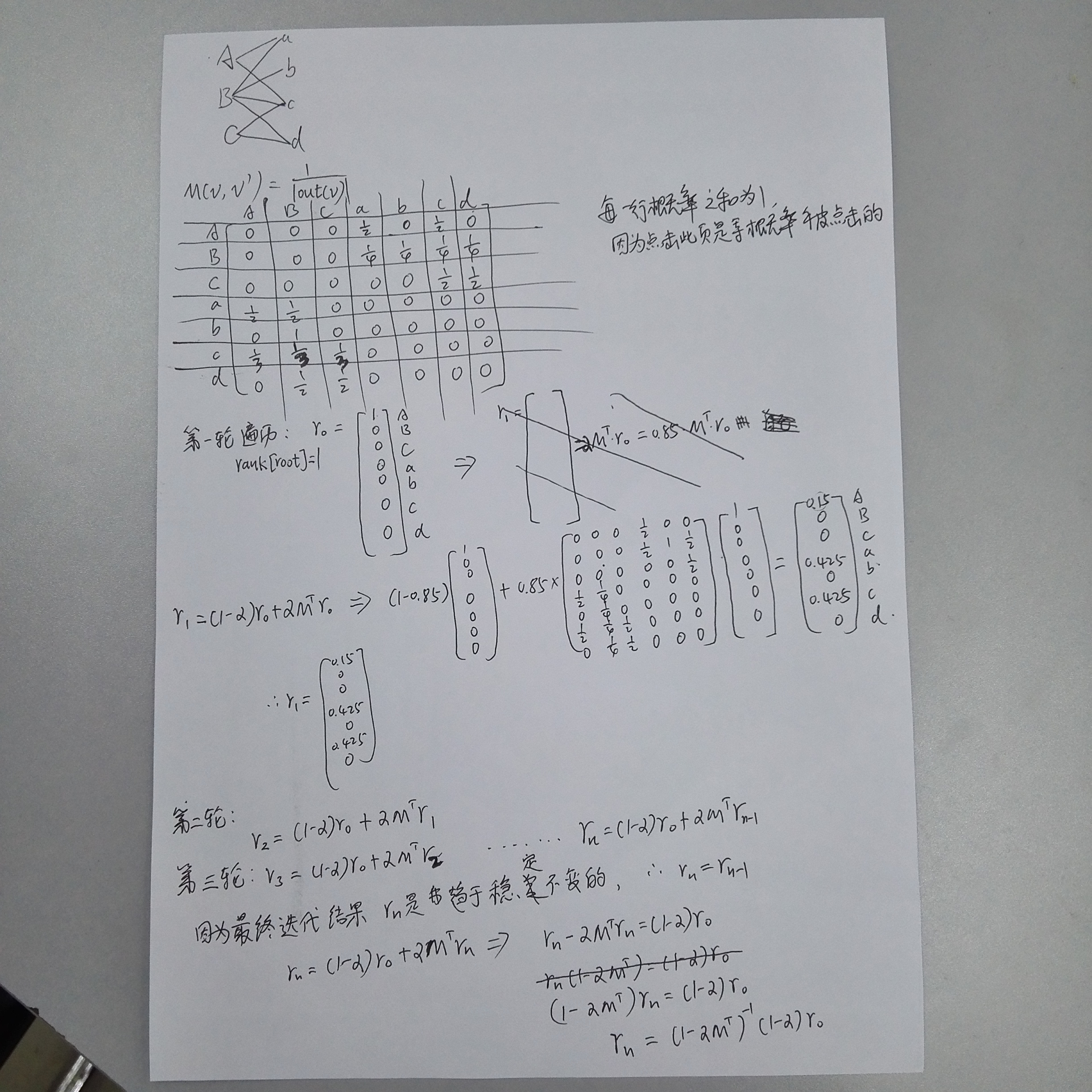
只需要计算一次逆矩阵就可以算出最后的结果。
笔记中的例子来自于《推荐系统实践》,也参考了http://blog.csdn.net/pi9nc/article/details/27483249
中最后的运行结果。















 2286
2286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









