







LDA
LDA(Latent Dirichlet Allocation,隐含狄利克雷分布)是一种降维算法,适用于文本建模。
一篇新闻文本可能会有一个诸如“体育”或“教育”等的主题,也可能有多个主题。使用 LDA 可以将文本中的单词作为输入,为其分配多个主题。
概述
LDA 是一种用于自然语言处理等的算法。该算法可以根据文本中的单词找出潜在的主题,并描述每个文本是由什么主题组成的,还可以用于说明一个文本不只有一个主题,而是有多个主题。例如,一篇真实的新闻文本可能包含多个主题,如“体育”和“教育”等,使用 LDA 就可以很好地描述这种新闻文本。
为了便于理解,我们来思考几个具体的例子。对以下 5 个例句应用 LDA,结果会是什么样呢?假设这些例句中的主题数为 2。
We go to school on weekdays.
I like playing sports.
They enjoyed playing sports in school.
Did she go there after school?
He read the sports columns yesterday.
我们可以将主题看作单词的概率分布。推测出的主题 A 和主题 B 的单词的概率分布如图 3-15 所示,school 是主题 A 的代表性单词,sports 是主题 B 的代表性单词。此外,也可以推测文本中包含的主题的比例,从而以主题的概率分布(主题分布)描述各文本。
如图 3-15 所示,LDA 可以利用主题分布和单词分布创建文本数据。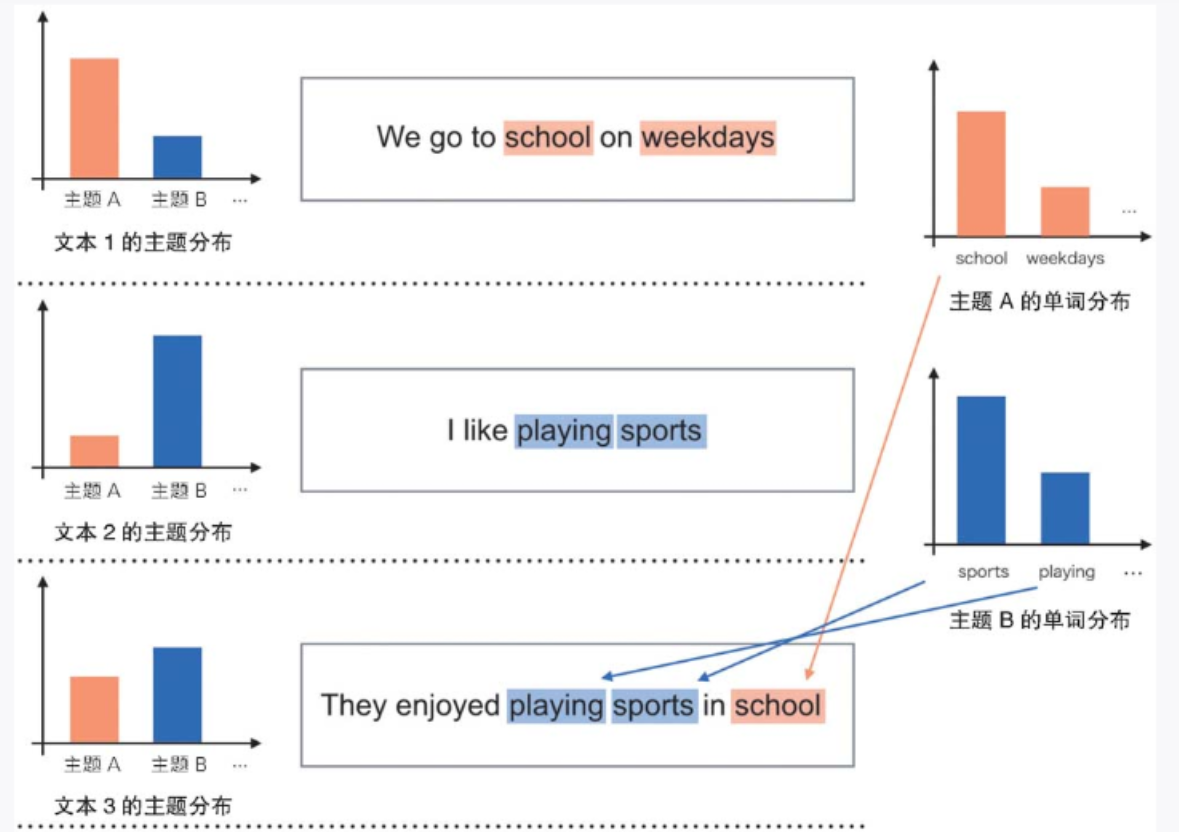
▲图 3-15 基于每个文本的主题分布和每个主题的单词分布创建文本
具体做法是基于文本的主题分布选择主题,之后基于主题的单词分布选择文本中的单词。重复这一操作,就能得到生成文本的模型。下面的“算法说明”部分将介绍如何根据输入数据计算主题分布和单词分布。
- 基于文本的主题分布为单词分配主题。
- 基于分配的主题的单词分布确定单词。
- 对所有文本中包含的单词执行步骤 1 和步骤 2 的操作。
算法说明
LDA 通过以下步骤计算主题分布和单词分布。
- 为各文本的单词随机分配主题。
- 基于为单词分配的主题,计算每个文本的主题概率。
- 基于为单词分配的主题,计算每个主题的单词概率。
- 计算步骤 2 和步骤 3 中的概率的乘积,基于得到的概率,再次为各文本的单词分配主题。
- 重复步骤 2 ~步骤 4 的计算,直到收敛。
根据步骤 4 中计算得到的概率,为各文本的单词分配主题。由于步骤 2 中确定了文本的主题概率,所以在同一个文本内,某些主题被选中的可能性较大。另外,同一个文本中的单词往往被选为同一主题。通过重复这样的计算,文本分配到特定主题的概率就会增加。同时,由于与每个主题相关联的单词更容易被选中,所以单词作为代表主题的词的概率也会增加。
示例代码
下面使用 scikit-learn 实现基于 LDA 的主题模型的创建。我们使用一个名为 20 Newsgroups 的数据集,这个数据集是 20 个主题的新闻组文本的集合,每个文本属于一个主题。
▼示例代码
# 这个数据集是一个用于分类任务的常用数据集,包含了各种主题的新闻组文档。
from sklearn.datasets import fetch_20newsgroups
# 用于将文本数据转换为数值特征的工具。它可以将文本转换为词频矩阵,用于文本分类和聚类等任务。
from sklearn.feature_extraction.text import CountVectorizer
# 是用于进行潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)主题建模的工具。LDA是一种用于从文本数据中提取主题的无监督学习算法。
from sklearn.decomposition import LatentDirichletAllocation
# fetch_20newsgroups函数加载20新闻组数据集。参数remove=('headers', 'footers', 'quotes')表示移除每个文档中的头部、尾部和引用部分,以减少噪声和干扰。
data = fetch_20newsgroups(remove=('headers', 'footers', 'quotes'))
# 只选择频率最高的1000个特征词作为特征。这样做是为了降低特征空间的维度并提高计算效率。
max_features = 1000
# CountVectorizer可以将文本文档转换为令牌计数的矩阵表示。参数max_features=max_features表示提取的特征词数限制为max_features。stop_words='english'表示使用英语的常见停用词列表,这些停用词通常在文本分类任务中被认为没有实际意义。
tf_vectorizer = CountVectorizer(max_features=max_features, stop_words='english')
# 使用tf_vectorizer来提取文本数据的特征向量。这些特征向量包含了每个文档中每个特征词的词频信息。
# fit_transform方法将原始文本数据转换成特征矩阵。特征矩阵的每一行对应一个文档,每一列对应一个特征词,并统计了每个特征词在每个文档中的出现次数。
tf = tf_vectorizer.fit_transform(data.data)
# 表示要提取的主题数量
n_topics = 20
# 模型使用隐含狄利克雷分布来对文档进行建模,从而推断出每个文档隐含的主题。
model = LatentDirichletAllocation(n_components=n_topics)
# 之前提取的特征向量tf输入到模型中,进行模型的训练和拟合过程。这一过程估计了主题模型中的参数,并更新了模型的内部状态。
model.fit(tf)
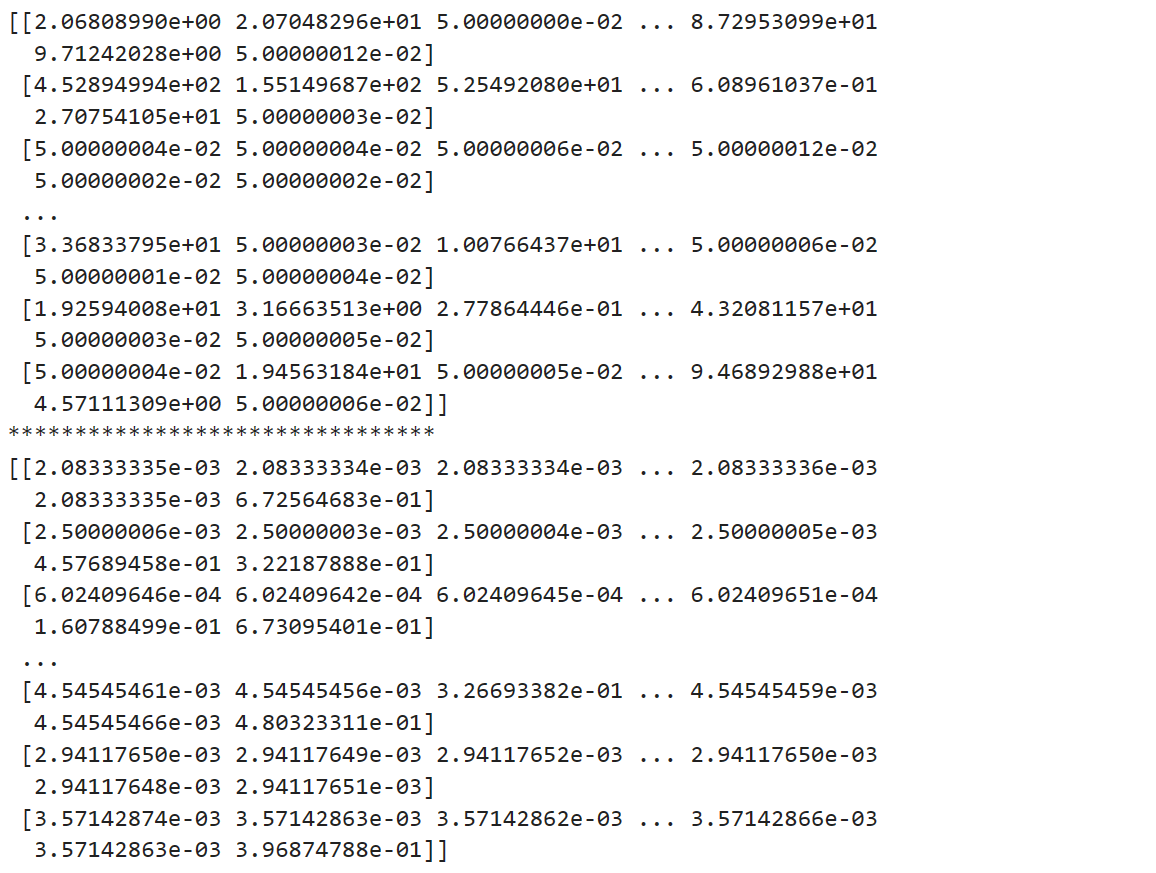
print(model.components_)
print("********************************")
print(model.transform(tf))结果:
详细说明
使用主题描述文本
下面我们仔细看一下刚刚在“算法说明”部分训练的 LDA 的结果。
下图按照概率从高到低的顺序列出了每个主题分布中的单词,由此我们可以知道哪些单词代表主题。
例如,主题 16 是关于体育的,主题 18 是关于计算机的……我们可以根据主题中包含的单词来解释主题。
- 主题16:
game team year games season play hockey players league win teams ...
- 主题18:
windows drive card scsi disk use problem bit memory dos pc using ...
...
另一些主题要么只包含数值,要么包含的都是一些不能表达主题的没有特指的单词,如下图所示。这些结果乍一看很难解释,下面通过停用词(为了提高精度而排除在外的单词)来对其进行改进。
- 主题4:
00 10 25 15 12 11 16 20 14 13 18 30 50 17 55 40 21 ...
- 主题6:
people said know did don didn just time went like say think told ...
接下来,我们来看一下文本的主题分布。图 3-16 所示为某文本的主题分布图。由于它包含了较多主题 18 的成分,所以可以断定这是关于计算机的文本。这个文本的实际主题是 comp.sys.mac.hardware,是关于苹果公司的 Mac 的文本。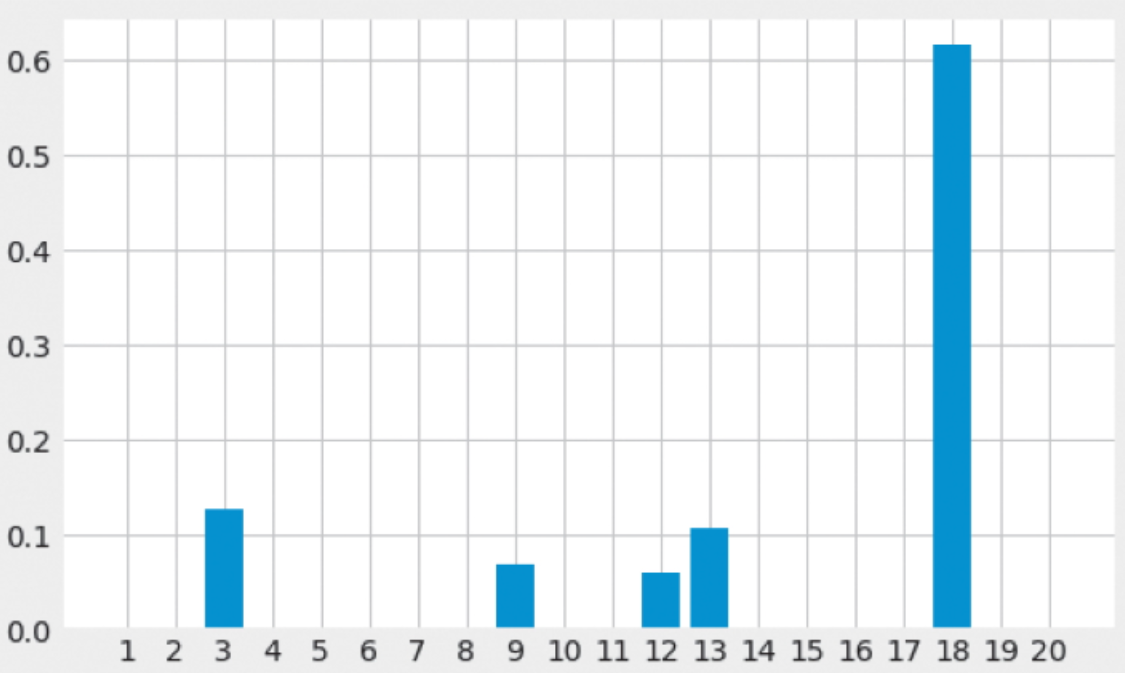
▲图 3-16 某个文本的主题分布(主题数:20 个)
如果只用单词来描述文本的特征,就很难直观地理解,但通过 LDA,我们就能够用主题来描述文本的特征。
———————————————————————————————————————————
文章来源:书籍《图解机器学习算法》
作者:秋庭伸也 杉山阿圣 寺田学
出版社:人民邮电出版社
ISBN:9787115563569
本篇文章仅用于学习和研究目的,不会用于任何商业用途。引用书籍《图解机器学习算法》的内容旨在分享知识和启发思考,尊重原著作者秋庭伸也 杉山阿圣 寺田学的知识产权。如有侵权或者版权纠纷,请及时联系作者。
———————————————————————————————————————————

















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









