






该项目的详细github地址如下:
https://github.com/zcswdt/Color_OCR_image_generator
文字图片合成
在训练文字识别模型时,需要大批量的训练数据,然而当人工进行文字标注时,会花费大量的成本,所以为了解决训练集不足的问题,本文提出了一种文字合成的方法。
语料准备
选择好字典文件,然后可以去网上下载几本小说进行语料集,使用如下代码进行对小说中没有出现在字典文件的文字进行过滤。切换不同模式,当mode = 'filter’时,对语料集进行过滤,当model= 'split’时,对语料集进行切分。
"coding = utf-8"
# 删除语料中的生僻字
import codecs
import progressbar
import numpy as np
# import mycrnn_pc.config.cfg as cfg
import re,string
punctuation = """!,。?。"#$%&'()*+-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏"""
#np.random.seed(0)
dictfile = "dict5990.txt"
corpus_file = "jingji.txt"
output = "filted_jian_sentences.txt"
filiter_txt="fileter.txt"
dict = []
max_row_len = 20
#mode = 'split'
mode = 'filter'
if mode == 'filter':
with codecs.open(dictfile, mode='r', encoding='utf-8') as f:
# 按行读取字典
for line in f:
# 当前行单词去除结尾,为了正常读取空格,第一行两个空格
word = line.strip('\r\n')
# 只要没超出上限就继续添加单词
dict.append(word)
corpus = []
with codecs.open(corpus_file, mode='r', encoding='utf-8') as f:
# 按行读取语料
print('正在读取语料...')
for line in f:
corpus.append(line)
with codecs.open(output, mode='w', encoding='utf-8') as output:
widgets = ["正在过滤语料: ", progressbar.Percentage(), " ", progressbar.Bar(), " ", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval=len(corpus), widgets=widgets).start()
np.random.shuffle(corpus)
f = codecs.open(filiter_txt, mode='w', encoding='utf-8')
for i, line in enumerate(corpus):
line = line.strip().replace(" ", "") # 去除空格
sentence = ''
for each in line:
# 去除生僻字
try:
dict.index(each)
sentence += each
except:
pass
print('i',i)
#print("字典不包含{}, 忽略".format(each,i))
print('a={0} b={1}'.format(each,i))
f.write(each+"\t"+str(i+1)+"\n")
if sentence != '\n' and sentence != ' ' and sentence!='': # 不写空行
output.write(sentence+'\n')
pbar.update(i)
pbar.finish()
elif mode == 'split':
corpus = []
with codecs.open(output, mode='r', encoding='utf-8') as f:
# 按行读取语料
print('正在读取语料...')
for line in f:
corpus.append(line)
with codecs.open('split_sentences.txt', mode='w', encoding='utf-8') as output:
widgets = ["正在分行语料: ", progressbar.Percentage(), " ", progressbar.Bar(), " ", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval=len(corpus), widgets=widgets).start()
for i, line in enumerate(corpus):
row = line
# if np.random.randint(0, 1000) < 2: # 0.2%的概率加空白行
# output.write('\n')
# 对大于max_row_len的句子进行分行,直到最后小于max_row_len
while len(row) > max_row_len:
# 长句子分行
# 偶尔出现单字
spliter = np.random.random_integers(1, max_row_len-1)
output.write(row[0:spliter] + '\n')
# if np.random.randint(0, 1000) < 2: # 0.2%的概率加空白行
# output.write('\n')
row = row[spliter:]
#每行会含有一个换行符,去掉换行符
if len(row)>=6:
re_punctuation = "[{}]+".format(punctuation)
row = re.sub(re_punctuation, "", row)
if len(row)>=6:
output.write(row)
pbar.update(i)
pbar.finish()
字体文件准备
在生成文字图片时候,需要选择生成在图片上的字体,我整理了如下近700种字体,百度云链接如下:
here1. Extraction code:8kzt. here2. Extraction code:s58p
背景图片的选择
选择生成文字图片的背景,将其放入到背景图片文件夹中
文字生成
准备工作完毕,接下来就是字体生成了,该代码能生成水平和竖直的文字,并且能够对生成的图片进行不同的处理,例如:引入噪声,上下运动模糊,左右运动模糊。
|  |
| 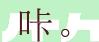 |
|
| |
| |
|
|  |
|  |
|
# -*- coding: utf-8 -*-
"""
-*- coding: utf-8 -*-
@author: zcswdt
@email: jhsignal@126.com
@file: Color_OCR_image_generator.py
@time: 2020/06/24
"""
import cv2
import numpy as np
import pickle
import random
from PIL import Image,ImageDraw,ImageFont
import os
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import time
import hashlib
from fontTools.ttLib import TTCollection, TTFont
import argparse
class FontColor(object):
def __init__(self, col_file):
with open(col_file, 'rb') as f:
u = pickle._Unpickler(f)
u.encoding = 'latin1'
self.colorsRGB = u.load()
self.ncol = self.colorsRGB.shape[0]
# convert color-means from RGB to LAB for better nearest neighbour
# computations:
self.colorsRGB = np.r_[self.colorsRGB[:, 0:3], self.colorsRGB[:, 6:9]].astype('uint8')
self.colorsLAB = np.squeeze(cv2.cvtColor(self.colorsRGB[None, :, :], cv2.COLOR_RGB2Lab))
def Lab2RGB(c):
if type(c) == list:
return cv2.cvtColor(np.array([c], dtype=np.uint8)[None,:],cv2.COLOR_Lab2RGB)
else:
return cv2.cvtColor(c[None, :, :],cv2.COLOR_Lab2RGB)
def RGB2Lab(rgb):
import numpy as np
if type(rgb) == list:
return(cv2.cvtColor(np.asarray([rgb],dtype=np.uint8)[None,:],cv2.COLOR_RGB2Lab))
else:
return cv2.cvtColor(rgb, cv2.COLOR_RGB2Lab)
def get_char_lines(txt_root_path):
txt_files = os.listdir(txt_root_path)
char_lines = []
for txt in txt_files:
f = open(os.path.join(txt_root_path,txt),mode='r', encoding='utf-8')
lines = f.readlines()
f.close()
for line in lines:
char_lines.append(line.strip().replace('\xef\xbb\xbf', '').replace('\ufeff', ''))
return char_lines
# 获取chars
def get_chars(char_lines):
while True:
char_line = random.choice(char_lines)
if len(char_line)>0:
break
line_len = len(char_line)
char_len = random.randint(1,20) # 4
if line_len<=char_len:
return char_line
char_start = random.randint(0,line_len-char_len)
chars = char_line[char_start:(char_start+char_len)]
return chars
# 选择字体
def chose_font(fonts,font_sizes):
f_size = random.choice(font_sizes) # 不满就取最大字号吧
font = random.choice(fonts[f_size])
return font
# 分析图片,获取最适宜的字体颜色
def get_bestcolor(color_lib, crop_lab):
if crop_lab.size > 4800:
crop_lab = cv2.resize(crop_lab,(100,16)) #将图像转成100*16大小的图片
labs = np.reshape(np.asarray(crop_lab), (-1, 3)) #len(labs)长度为160
clf = KMeans(n_clusters=8)
clf.fit(labs)
#clf.labels_是每个聚类中心的数据(假设有八个类,则每个数据标签属于每个类的数据格式就是从0-8),clf.cluster_centers_是每个聚类中心
total = [0] * 8
for i in clf.labels_:
total[i] = total[i] + 1 #计算每个类中总共有多少个数据
clus_result = [[i, j] for i, j in zip(clf.cluster_centers_, total)] #聚类中心,是一个长度为8的数组
clus_result.sort(key=lambda x: x[1], reverse=True) #八个类似这样的数组,第一个数组表示类中心,第二个数字表示属于该类中心的一共有多少数据[[array([242.55732946, 128.1509434 , 122.29608128]), 689], [array([245.03461538, 128.59230769, 125.88846154]), 260],,,,]
color_sample = random.sample(range(color_lib.colorsLAB.shape[0]), 500) # 范围是(0,9882),随机从这些数字里面选取500个
def caculate_distance(color_lab, clus_result):
weight = [1, 0.8, 0.6, 0.4, 0.2, 0.1, 0.05, 0.01]
d = 0
for c, w in zip(clus_result, weight):
#计算八个聚类中心和当前所选取颜色距离的标准差之和,每个随机选取的颜色当前聚类中心的差值
d = d + np.linalg.norm(c[0] - color_lab)
return d
color_dis = list(map(lambda x: [caculate_distance(color_lib.colorsLAB[x], clus_result), x], color_sample)) #将color_sample中的每个参数当成x传入函数内,color_lib.colorsLAB[x]是一个元组(r,g,b)也就是字体库里面的颜色
#color_dis 是一个长度为500的列表[[x,y],[],,,,,],其中[x,y]其中x表示背景色和当前颜色的距离,y表示该颜色的色号
color_dis.sort(key=lambda x: x[0], reverse=True)
color_num = color_dis[0:200]
color_l = random.choice(color_num)[1]
#print('color_dis',color_l)
#color_num=random.choice(color_dis[0:300])
#print('color_dis[0][1]',color_dis[0][1])
return tuple(color_lib.colorsRGB[color_l])
#return tuple(color_lib.colorsRGB[color_dis[0][1]])
def word_in_font(word,unsupport_chars,font_path):
#print('1',word)
#sprint('2',unsupport_chars)
for c in word:
#print('c',c)
if c in unsupport_chars:
print('Retry pick_font(), \'%s\' contains chars \'%s\' not supported by font %s' % (word, c, font_path))
return True
else:
continue
# 获得水平文本图片
def get_horizontal_text_picture(image_file,color_lib,char_lines,fonts_list,font_unsupport_chars,cf):
retry = 0
img = Image.open(image_file)
#print('image_file',image_file)
if img.mode != 'RGB':
img = img.convert('RGB')
w, h = img.size
#print('w',w)
#print('h',h)
#随机加入空格
rd = random.random()
#print('rd',rd)
if rd < 0.3:
while True:
width = 0
height = 0
chars_size = []
y_offset = 10 ** 5
#随机获得不定长的文字
chars = get_chars(char_lines)
#随机选择一种字体
font_path = random.choice(fonts_list)
font_size = random.randint(cf.font_min_size,cf.font_max_size)
#获得字体,及其大小
font = ImageFont.truetype(font_path, font_size)
#不支持的字体文字,按照字体路径在该字典里索引即可
unsupport_chars = font_unsupport_chars[font_path]
for c in chars:
size = font.getsize(c)
chars_size.append(size)
width += size[0]
# set max char height as word height
if size[1] > height:
height = size[1]
# Min chars y offset as word y offset
# Assume only y offset
c_offset = font.getoffset(c)
if c_offset[1] < y_offset:
y_offset = c_offset[1]
char_space_width = int(height * np.random.uniform(-0.1, 0.3))
width += (char_space_width * (len(chars) - 1))
f_w, f_h = width,height
if f_w < w:
# 完美分割时应该取的
x1 = random.randint(0, w - f_w)
y1 = random.randint(0, h - f_h)
x2 = x1 + f_w
y2 = y1 + f_h
#加一点偏移
if cf.random_offset:
print('cf.random_offset',cf.random_offset)
# 随机加一点偏移,且随机偏移的概率占30%
rd = random.random()
if rd < 0.3: # 设定偏移的概率
crop_y1 = y1 - random.random() / 5 * f_h
crop_x1 = x1 - random.random() / 2 * f_h
crop_y2 = y2 + random.random() / 5 * f_h
crop_x2 = x2 + random.random() / 2 * f_h
crop_y1 = int(max(0, crop_y1))
crop_x1 = int(max(0, crop_x1))
crop_y2 = int(min(h, crop_y2))
crop_x2 = int(min(w, crop_x2))
else:
crop_y1 = y1
crop_x1 = x1
crop_y2 = y2
crop_x2 = x2
else:
crop_y1 = y1
crop_x1 = x1
crop_y2 = y2
crop_x2 = x2
crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
crop_lab = cv2.cvtColor(np.asarray(crop_img), cv2.COLOR_RGB2Lab)
#print('crop_lab.size',crop_lab.size)
all_in_fonts=word_in_font(chars,unsupport_chars,font_path)
#print('all_in_fonts',all_in_fonts)
# kk=np.linalg.norm(np.reshape(np.asarray(crop_lab),(-1,3)).std(axis=0))
# print('kk',kk)
if (np.linalg.norm(np.reshape(np.asarray(crop_lab),(-1,3)).std(axis=0))>55 or all_in_fonts) and retry<30: # 颜色标准差阈值,颜色太丰富就不要了
retry = retry+1
#print('retry',retry)
continue
if not cf.customize_color:
best_color = get_bestcolor(color_lib, crop_lab)
else:
r = random.choice([7,9,11,14,13,15,17,20,22,50,100])
g = random.choice([8,10,12,14,21,22,24,23,50,100])
b = random.choice([6,8,9,10,11,30,21,34,56,100])
best_color = (r,g,b)
#print('best_color',best_color)
break
else:
pass
#print('chars1',chars)
draw = ImageDraw.Draw(img)
for i, c in enumerate(chars):
# self.draw_text_wrapper(draw, c, c_x, c_y - y_offset, font, word_color, force_text_border)
#draw.text((x1, y1-y_offset), c, best_color, font=font)
draw.text((x1, y1), c, best_color, font=font)
x1 += (chars_size[i][0] + char_space_width)
crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
return crop_img,chars
else:
while True:
#随机获得不定长的文字
chars = get_chars(char_lines)
#随机选择一种字体
font_path = random.choice(fonts_list)
font_size = random.randint(cf.font_min_size,cf.font_max_size)
#获得字体,及其大小
font = ImageFont.truetype(font_path, font_size)
#不支持的字体文字,按照字体路径在该字典里索引即可
unsupport_chars = font_unsupport_chars[font_path]
f_w, f_h = font.getsize(chars)
#print('chars',chars)
#print('f_w',f_w)
#print('f_h',f_h)
if f_w < w:
# 完美分割时应该取的
x1 = random.randint(0, w - f_w)
y1 = random.randint(0, h - f_h)
x2 = x1 + f_w
y2 = y1 + f_h
#加一点偏移
if cf.random_offset:
# 随机加一点偏移,且随机偏移的概率占30%
rd = random.random()
if rd < 0.3: # 设定偏移的概率
crop_y1 = y1 - random.random() / 10 * f_h
crop_x1 = x1 - random.random() / 8 * f_h
crop_y2 = y2 + random.random() / 10 * f_h
crop_x2 = x2 + random.random() / 8 * f_h
crop_y1 = int(max(0, crop_y1))
crop_x1 = int(max(0, crop_x1))
crop_y2 = int(min(h, crop_y2))
crop_x2 = int(min(w, crop_x2))
else:
crop_y1 = y1
crop_x1 = x1
crop_y2 = y2
crop_x2 = x2
else:
crop_y1 = y1
crop_x1 = x1
crop_y2 = y2
crop_x2 = x2
crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
crop_lab = cv2.cvtColor(np.asarray(crop_img), cv2.COLOR_RGB2Lab)
#print('crop_lab.size',crop_lab.size)
#判断语料中每个字是否在字体文件中
all_in_fonts=word_in_font(chars,unsupport_chars,font_path)
#print('all_in_fonts',all_in_fonts)
if (np.linalg.norm(np.reshape(np.asarray(crop_lab),(-1,3)).std(axis=0))>55 or all_in_fonts) and retry<30: # 颜色标准差阈值,颜色太丰富就不要了,单词不在字体文件中不要
retry = retry+1
print('retry',retry)
continue
if not cf.customize_color:
best_color = get_bestcolor(color_lib, crop_lab)
##可以自定义字体颜色
else:
r = random.choice([7,9,11,14,13,15,17,20,22,50,100])
g = random.choice([8,10,12,14,21,22,24,23,50,100])
b = random.choice([6,8,9,10,11,30,21,34,56,100])
best_color = (r,g,b)
break
else:
pass
draw = ImageDraw.Draw(img)
draw.text((x1, y1), chars, best_color, font=font)
crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
return crop_img,chars
def get_vertical_text_picture(image_file,color_lib,char_lines,fonts_list,font_unsupport_chars,cf):
img = Image.open(image_file)
if img.mode != 'RGB':
img = img.convert('RGB')
w, h = img.size
retry = 0
while True:
#随机获得不定长的文字
chars = get_chars(char_lines)
#随机选择一种字体
font_path = random.choice(fonts_list)
font_size = random.randint(cf.font_min_size,cf.font_max_size)
#获得字体,及其大小
font = ImageFont.truetype(font_path, font_size)
#不支持的字体文字,按照字体路径在该字典里索引即可
unsupport_chars = font_unsupport_chars[font_path]
ch_w = []
ch_h = []
for ch in chars:
wt, ht = font.getsize(ch)
ch_w.append(wt)
ch_h.append(ht)
f_w = max(ch_w)
f_h = sum(ch_h)
# 完美分割时应该取的,也即文本位置
if h>f_h:
x1 = random.randint(0, w - f_w)
y1 = random.randint(0, h - f_h)
x2 = x1 + f_w
y2 = y1 + f_h
if cf.random_offset:
# 随机加一点偏移,且随机偏移的概率占30%
rd = random.random()
if rd < 0.3: # 设定偏移的概率
crop_y1 = y1 - random.random() / 10 * f_h
crop_x1 = x1 - random.random() / 8 * f_h
crop_y2 = y2 + random.random() / 10 * f_h
crop_x2 = x2 + random.random() / 8 * f_h
crop_y1 = int(max(0, crop_y1))
crop_x1 = int(max(0, crop_x1))
crop_y2 = int(min(h, crop_y2))
crop_x2 = int(min(w, crop_x2))
else:
crop_y1 = y1
crop_x1 = x1
crop_y2 = y2
crop_x2 = x2
else:
crop_y1 = y1
crop_x1 = x1
crop_y2 = y2
crop_x2 = x2
crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
crop_lab = cv2.cvtColor(np.asarray(crop_img), cv2.COLOR_RGB2Lab)
all_in_fonts=word_in_font(chars,unsupport_chars,font_path)
if (np.linalg.norm(np.reshape(np.asarray(crop_lab),(-1,3)).std(axis=0))>55 or all_in_fonts) and retry<30: # 颜色标准差阈值,颜色太丰富就不要了
retry = retry + 1
continue
if not cf.customize_color:
best_color = get_bestcolor(color_lib, crop_lab)
else:
r = random.choice([7,9,11,14,13,15,17,20,22,50,100])
g = random.choice([8,10,12,14,21,22,24,23,50,100])
b = random.choice([6,8,9,10,11,30,21,34,56,100])
best_color = (r,g,b)
break
else:
pass
draw = ImageDraw.Draw(img)
i = 0
for ch in chars:
draw.text((x1, y1), ch, best_color, font=font)
y1 = y1 + ch_h[i]
i = i + 1
crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
crop_img = crop_img.transpose(Image.ROTATE_270)
return crop_img,chars
def get_fonts(fonts_path):
font_files = os.listdir(fonts_path)
fonts_list=[]
for font_file in font_files:
font_path=os.path.join(fonts_path,font_file)
fonts_list.append(font_path)
return fonts_list
def get_unsupported_chars(fonts, chars_file):
"""
Get fonts unsupported chars by loads/saves font supported chars from cache file
:param fonts:
:param chars_file:
:return: dict
key -> font_path
value -> font unsupported chars
"""
charset = load_chars(chars_file)
charset = ''.join(charset)
fonts_chars = get_fonts_chars(fonts, chars_file)
fonts_unsupported_chars = {}
for font_path, chars in fonts_chars.items():
unsupported_chars = list(filter(lambda x: x not in chars, charset))
fonts_unsupported_chars[font_path] = unsupported_chars
return fonts_unsupported_chars
def load_chars(filepath):
if not os.path.exists(filepath):
print("Chars file not exists.")
exit(1)
ret = ''
with open(filepath, 'r', encoding='utf-8') as f:
while True:
line = f.readline()
if not line:
break
ret += line[0]
return ret
def get_fonts_chars(fonts, chars_file):
"""
loads/saves font supported chars from cache file
:param fonts: list of font path. e.g ['./data/fonts/msyh.ttc']
:param chars_file: arg from parse_args
:return: dict
key -> font_path
value -> font supported chars
"""
out = {}
cache_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), '../', '.caches'))
if not os.path.exists(cache_dir):
os.makedirs(cache_dir)
chars = load_chars(chars_file)
chars = ''.join(chars)
for font_path in fonts:
string = ''.join([font_path, chars])
file_md5 = md5(string)
cache_file_path = os.path.join(cache_dir, file_md5)
if not os.path.exists(cache_file_path):
ttf = load_font(font_path)
_, supported_chars = check_font_chars(ttf, chars)
print('Save font(%s) supported chars(%d) to cache' % (font_path, len(supported_chars)))
with open(cache_file_path, 'wb') as f:
pickle.dump(supported_chars, f, pickle.HIGHEST_PROTOCOL)
else:
with open(cache_file_path, 'rb') as f:
supported_chars = pickle.load(f)
print('Load font(%s) supported chars(%d) from cache' % (font_path, len(supported_chars)))
out[font_path] = supported_chars
return out
def load_font(font_path):
"""
Read ttc, ttf, otf font file, return a TTFont object
"""
# ttc is collection of ttf
if font_path.endswith('ttc'):
ttc = TTCollection(font_path)
# assume all ttfs in ttc file have same supported chars
return ttc.fonts[0]
if font_path.endswith('ttf') or font_path.endswith('TTF') or font_path.endswith('otf'):
ttf = TTFont(font_path, 0, allowVID=0,
ignoreDecompileErrors=True,
fontNumber=-1)
return ttf
def md5(string):
m = hashlib.md5()
m.update(string.encode('utf-8'))
return m.hexdigest()
def check_font_chars(ttf, charset):
"""
Get font supported chars and unsupported chars
:param ttf: TTFont ojbect
:param charset: chars
:return: unsupported_chars, supported_chars
"""
#chars = chain.from_iterable([y + (Unicode[y[0]],) for y in x.cmap.items()] for x in ttf["cmap"].tables)
chars_int=set()
for table in ttf['cmap'].tables:
for k,v in table.cmap.items():
chars_int.add(k)
unsupported_chars = []
supported_chars = []
for c in charset:
if ord(c) not in chars_int:
unsupported_chars.append(c)
else:
supported_chars.append(c)
ttf.close()
return unsupported_chars, supported_chars
def prob(percent):
"""
percent: 0 ~ 1, e.g: 如果 percent=0.1,有 10% 的可能性
"""
assert 0 <= percent <= 1
if random.uniform(0, 1) <= percent:
return True
return False
def apply_blur_on_output(img):
if prob(0.5):
return apply_gauss_blur(img, [3, 5])
else:
return apply_norm_blur(img)
def apply_gauss_blur(img, ks=None):
if ks is None:
ks = [7, 9, 11, 13]
ksize = random.choice(ks)
sigmas = [0, 1, 2, 3, 4, 5, 6, 7]
sigma = 0
if ksize <= 3:
sigma = random.choice(sigmas)
img = cv2.GaussianBlur(img, (ksize, ksize), sigma)
return img
def apply_norm_blur(img, ks=None):
# kernel == 1, the output image will be the same
if ks is None:
ks = [2, 3]
kernel = random.choice(ks)
img = cv2.blur(img, (kernel, kernel))
return img
def apply_prydown(img):
"""
模糊图像,模拟小图片放大的效果
"""
scale = random.uniform(1, 1.5)
height = img.shape[0]
width = img.shape[1]
out = cv2.resize(img, (int(width / scale), int(height / scale)), interpolation=cv2.INTER_AREA)
return cv2.resize(out, (width, height), interpolation=cv2.INTER_AREA)
def apply_lr_motion(image):
kernel_size = 5
kernel_motion_blur = np.zeros((kernel_size, kernel_size))
kernel_motion_blur[int((kernel_size - 1) / 2), :] = np.ones(kernel_size)
kernel_motion_blur = kernel_motion_blur / kernel_size
image = cv2.filter2D(image, -1, kernel_motion_blur)
return image
def apply_up_motion(image):
kernel_size = 9
kernel_motion_blur = np.zeros((kernel_size, kernel_size))
kernel_motion_blur[:, int((kernel_size - 1) / 2)] = np.ones(kernel_size)
kernel_motion_blur = kernel_motion_blur / kernel_size
image = cv2.filter2D(image, -1, kernel_motion_blur)
return image
代码实现的主程序以及控制参数详解,在该模块中控制着代码生成图片的效果。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_img', type=int, default=100, help="Number of images to generate")
parser.add_argument('--font_min_size', type=int, default=12)
parser.add_argument('--font_max_size', type=int, default=70,
help="Can help adjust the size of the generated text and the size of the picture")
parser.add_argument('--bg_path', type=str, default='./background',
help='The generated text pictures will use the pictures of this folder as the background')
parser.add_argument('--fonts_path',type=str, default='./fonts/chinse_jian',
help='The font used to generate the picture')
parser.add_argument('--corpus_path', type=str, default='./corpus',
help='The corpus used to generate the text picture')
parser.add_argument('--color_path', type=str, default='./models/colors_new.cp',
help='Color font library used to generate text')
parser.add_argument('--chars_file', type=str, default='dict5990.txt',
help='Chars allowed to be appear in generated images')
parser.add_argument('--customize_color', action='store_true', help='Support font custom color')
parser.add_argument('--blur', action='store_true', default=False,
help="Apply gauss blur to the generated image")
parser.add_argument('--prydown', action='store_true', default=False,
help="Blurred image, simulating the effect of enlargement of small pictures")
parser.add_argument('--lr_motion', action='store_true', default=False,
help="Apply left and right motion blur")
parser.add_argument('--ud_motion', action='store_true', default=False,
help="Apply up and down motion blur")
parser.add_argument('--random_offset', action='store_true', default=True,
help="Randomly add offset")
parser.add_argument('--output_dir', type=str, default='./output/', help='Images save dir')
cf = parser.parse_args()
# 读入字体色彩库
color_lib = FontColor(cf.color_path)
# 读入字体
print('color_lib',color_lib)
fonts_path = cf.fonts_path
# 读入newsgroup
txt_root_path = cf.corpus_path
char_lines = get_char_lines(txt_root_path=txt_root_path)
#将该文件的字体以"路径+字体"的形式存放到列表中
fonts_list = get_fonts(fonts_path)
img_root_path = cf.bg_path
imnames=os.listdir(img_root_path)
# import matplotlib.pyplot as plt
labels_path = 'labels.txt'
gs = 0
if os.path.exists(labels_path): # 支持中断程序后,在生成的图片基础上继续
f = open(labels_path,'r',encoding='utf-8')
lines = list(f.readlines())
#print('lines',lines[1])
f.close()
gs = int(lines[-1].strip().split('.')[0].split('_')[1])
print('Resume generating from step %d'%gs)
print('gs',gs)
#字典文件
chars_file=cf.chars_file
'''
返回的是字典,key对应font_path,value对应字体支持的字符
'''
font_unsupport_chars = get_unsupported_chars(fonts_list, chars_file)
f = open(labels_path,'a',encoding='utf-8')
print('start generating...')
t0=time.time()
img_n=0
for i in range(gs+1,cf.num_img):
img_n+=1
print('img_n',img_n)
imname = random.choice(imnames)
img_path = os.path.join(img_root_path,imname)
rnd = random.random()
if rnd<0.8: # 设定产生水平文本的概率
gen_img, chars = get_horizontal_text_picture(img_path,color_lib,char_lines,fonts_list,font_unsupport_chars,cf)
else:
gen_img, chars = get_vertical_text_picture(img_path,color_lib,char_lines,fonts_list,font_unsupport_chars,cf)
save_img_name = 'img_3_' + str(i).zfill(7) + '.jpg'
if gen_img.mode != 'RGB':
gen_img= gen_img.convert('RGB')
#高斯模糊
if cf.blur:
image_arr = np.array(gen_img)
gen_img = apply_blur_on_output(image_arr)
gen_img = Image.fromarray(np.uint8(gen_img))
#模糊图像,模拟小图片放大的效果
if cf.prydown:
image_arr = np.array(gen_img)
gen_img = apply_prydown(image_arr)
gen_img = Image.fromarray(np.uint8(gen_img))
#左右运动模糊
if cf.lr_motion:
image_arr = np.array(gen_img)
gen_img = apply_lr_motion(image_arr)
gen_img = Image.fromarray(np.uint8(gen_img))
#上下运动模糊
if cf.ud_motion:
image_arr = np.array(gen_img)
gen_img = apply_up_motion(image_arr)
gen_img = Image.fromarray(np.uint8(gen_img))
gen_img.save(cf.output_dir+save_img_name)
f.write(save_img_name+ ' '+chars+'\n')
print('gennerating:-------'+save_img_name)
# plt.figure()
# plt.imshow(np.asanyarray(gen_img))
# plt.show()
t1=time.time()
print('all_time',t1-t0)
f.close()
注:由于在生成图片的过程中,选用生成文字的字体文件,可能不会支持自己的字典文件中所有的文字,所以如果不进行判断处理,由于字体文件中没有字典中的文字,在生成的图片上可能会出现乱码或者是缺字现象,导致图片不能够被应用到文字识别的训练集中。这一点特别重要,所以在本代码中,引入该字体文件的判断,很好的解决了这一问题。当时我在生成文字图片的时候,这个对我造成了很大的困扰。
例:

















 7392
7392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









