







在Python中处理文本数据是使用str对象,也称为字符串。
字符串是由Unicode码位构成的不可变序列。字符串字面值有多种不同的写法:
•单引号:‘允许包含有"双"引号’
•双引号:“允许包含有’单’引号”。
•三重引号:’’‘三重单引号’’’,""“三重双引号”""使用三重引号的字符串可以跨越多行——其中所有的空白字符都将包含在该字符串字面值中。
'a'
In [2]: print('"a"')
"a"
In [3]: print("""a""")
a
In [4]: print("""a
...: b
...: c""")
a
b
c
作为单一表达式组成部分,之间只由空格分隔的多个字符串字面值会被隐式地转换为单个字符串字面值。
也就是说,("spam " “eggs”) == “spam eggs”。
In [5]: a=("a" "b")
In [6]: a
Out[6]: 'ab'
In [7]: a=("a " "b")
In [8]: a
Out[8]: 'a b'
In [9]: a="a b"
In [10]: a
Out[10]: 'a b'请参阅strings有解有关不同字符串字面值的更多信息,包括所支持的转义序列,以及使用r(”raw”)前缀来禁用大多数转义序列的处理。
In [16]: print(r"a\nb")
a\nb
In [17]: print("a\nb")
a
b字符串也可以通过使用str构造器从其他对象创建。
由于不存在单独的“字符”类型,对字符串做索引操作将产生一个长度为1的字符串。也就是说,对于一个非空字符串s,s[0] == s[0:1]。
不存在可变的字符串类型,但是str.join()或io.StringIO可以被被用来根据多个片段高效率地构建字符串。
在3.3版更改:为了与Python 2系列的向下兼容,再次允许字符串字面值使用u前缀。它对字符串字面值的含义没有影响,并且不能与r前缀同时出现。
u是指该字符串是使用unicode编码,而python3默认就使用unicode编码,所以u就没意义了!
class str(object=”)
class str(object=b”,encoding=’utf-8’,errors=’strict’)
返回object的字符串版本。如果未提供object则返回空字符串。在其他情况下str()的行为取决于encoding或errors是否有给出,具体见下。
如果encoding或errors均未给出,str(object)返回object.__str__(),这是object的“非正式”或格式良好的字符串表示。对于字符串对象,这是该字符串本身。如果object没有__str__()方法,则str()将回退为返回repr(object)。
如果encoding或errors至少给出其中之一,则object应该是一个bytes-like object(例如bytes或bytearray)。在此情况下,如果object是一个bytes(或bytearray)对象,则str(bytes,encoding, errors)等价于bytes.decode(encoding, errors)。否则的话,会在调用bytes.decode()之前获取缓冲区对象下层的bytes对象。请参阅二进制序列类型— bytes,bytearray, memoryview与bufferobjects了解有关缓冲区对象的信息。
将一个bytes对象传入str()而不给出encoding或errors参数的操作属于第一种情况,将返回非正式的字符串表示(另请参阅Python的-b命令行选项)。例如:
>>>str(b'Zoot!')
"b'Zoot!'"有关str类及其方法的更多信息,请参阅下面的文本序列类型— str和字符串的方法小节。要输出格式化字符串,请参阅f-strings和格式字符串语法小节。此外还可以参阅文本处理服务小节。
注:因为编码的原因,以上情况很难列举出来,例如即便在unicode环境下,定义一个gbk的字符串,但系统是知道他的意思的,所以当使用他时,仍能够正确的显示。而b’’,他之能带ascii字符。
字符串的方法
字符串实现了所有一般序列的操作,还额外提供了以下列出的一些附加方法。字符串还支持两种字符串格式化样式,一种提供了很大程度的灵活性和可定制性(参阅str.format(),格式字符串语法和自定义字符串格式化)而另一种是基于Cprintf样式的格式化,它可处理的类型范围较窄,并且更难以正确使用,但对于它可处理的情况往往会更为快速(printf风格的字符串格式化)。标准库的文本处理服务部分涵盖了许多其他模块,提供各种文本相关工具(例如包含于re模块中的正则表达式支持)。
In [5]: "{0} {0} {1}".format(1,2)
Out[5]: '1 1 2'
In [6]: "%d"%1
Out[6]: '1'
In [10]: "%d %s"%(1,"wa")
Out[10]: '1 wa'
In [15]: "%(国)s %(君)s"%{
"国":"魏","君":"曹"}
Out[15]: '魏 曹'str.capitalize()
返回原字符串的副本,其首个字符大写,其余为小写。在3.8版更改:第一个字符现在被放入了titlecase而不是uppercase。这意味着复合字母类字符将只有首个字母改为大写,而再不是全部字符大写。
·none 不改变文本的大写小写。
·capitalize、titlecase 元素中毎个单词的第一个字母用大写。
·uppercase 将所有文本设置为大写。
capitalize:使资本化;以大写字母写;
InIn [16]: "wang".capitalize()
Out[16]: 'Wang'str.casefold()
返回原字符串消除大小写的副本。消除大小写的字符串可用于忽略大小写的匹配。消除大小写类似于转为小写,但是更加彻底一些,因为它会移除字符串中的所有大小写变化形式。例如,德语小写字母’ß’相当于"ss"。由于它已经是小写了,lower()不会对’ß’做任何改变;而casefold()则会将其转换为"ss"。消除大小写算法的描述请参见Unicode标准的3.13节。3.3新版功能
case:情况 fold:折叠、合拢 casefold:返回所有字符为小写 收束 回归最原始唯一的状态
In [19]: "Wangß".casefold()
Out[19]: 'wangss'str.center(width[,fillchar])
返回长度为width的字符串,原字符串在其正中。使用指定的fillchar填充两边的空位(默认使用ASCII空格符)。如果width小于等于len(s)则返回原字符串的副本。
In [21]: "魏国".center(8)
Out[21]: ' 魏国 '
InIn [23]: "魏国".center(8,"⑦")
Out[23]: '⑦⑦⑦魏国⑦⑦⑦'
In In [27]: "魏国".center(1,"⑦")
Out[27]: '魏国'str.count(sub[,start[,end]])
反回子字符串sub在[start,end]范围内非重叠出现的次数。可选参数start与end会被解读为切片表示法。
In [28]: "daskjkldsjklfaf20312asd0fds123af".count("s")
Out[28]: 4str.encode(encoding=”utf-8”,errors=”strict”)
返回原字符串编码为字节串对象的版本。默认编码为’utf-8’。可以给出errors来设置不同的错误处理方案。errors的默认值为’strict’,表示编码错误会引发UnicodeError。其他可用的值为’ignore’,‘replace’,‘xmlcharrefreplace’,'backslashreplace’以及任何其他通过codecs.register_error()注册的值,请参阅错误处理方案小节。要查看可用的编码列表,请参阅标准编码小节。
在3.1版更改:加入了对关键字参数的支持。
print("香".encode())
print("香".encode(encoding="unicode_escape"))
input()b'\xe9\xa6\x99'
b'\\u9999'
File "C:/Users/jhsxy2005/PycharmProjects/untitled/20200705encode1.py", line 1
SyntaxError: Non-UTF-8 code starting with '\xfe' in file C:/Users/jhsxy2005/PycharmProjects/untitled/20200705encode1.py on line 1, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details同样的代码,在两个文件中两个效果!
 原因是我用的pycharm在某个注释coding过程中,他以unicode进行了保存,而且之后再怎么改,也不会改变保存文件的编码!只能利用记事本等工具!
原因是我用的pycharm在某个注释coding过程中,他以unicode进行了保存,而且之后再怎么改,也不会改变保存文件的编码!只能利用记事本等工具!
而以FEFF的Unicode编码、FFFE开头的Unicode big endian,python是识别不出的。而以EFBBBF开头的GBK编码却可以识别。
结论,pycharm会将文件依照注释的coding进行保存,UTF-8、GBK可以正常运行。而Unicode,pycharm确实将.py以Unicode保存了,但是python却无法读取Unicode的文件。
而我尝试用atom这样写,atom都是默认用UTF-8进行保存的。这样会看到另一种报错!
SyntaxError: encoding problem: Unicode
SyntaxError: encoding problem: GBK with BOM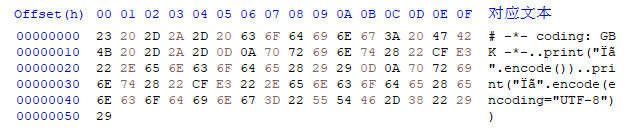
而以UTF-8编码保存的文件都是干货,没有任何前缀。
str.endswith(suffix[,start[,end]])
如果字符串以指定的suffix结束返回True,否则返回False。suffix也可以为由多个供查找的后缀构成的元组。如果有可选项start,将从所指定位置开始检查。如果有可选项end,将在所指定位置停止比较。
In [3]: "12v31231cvx".endswith("vx")
Out[3]: True
In [4]: "12v31231cvx".endswith("31",2,5)
Out[4]: True
In [6]: "12v31231cvx".endswith("31",4,5)
Out[6]: Falseendswith:ends with end swith 以某些字符结束
str.expandtabs(tabsize=8)
返回字符串的副本,其中所有的制表符会由一个或多个空格替换,具体取决于当前列位置和给定的制表符宽度。每tabsize个字符设为一个制表位(默认值8时设定的制表位在列0, 8, 16依次类推)。要展开字符串,当前列将被设为零并逐一检查字符串中的每个字符。如果字符为制表符(\t),则会在结果中插入一个或多个空格符,直到当前列等于下一个制表位。(制表符本身不会被复制。)如果字符为换行符(\n)或回车符(\r),它会被复制并将当前列重设为零。任何其他字符会被不加修改地复制并将当前列加一,不论该字符在被打印时会如何显示。
In [7]: '01\t012\t0123\t01234'.expandtabs()
Out[7]: '01 012 0123 01234'
In [8]: '01\t012\t0123\t01234'.expandtabs(4)
Out[8]: '01 012 0123 01234'
In [10]: '01\t012\t01\n23\t01234'.expandtabs(4)
Out[10]: '01 012 01\n23 01234'
In [11]: print('01\t012\t01\n23\t01234'.expandtabs(4 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









