









最近因为参与项目的关系,对淘宝,京东,苏宁易购三家网站系统构架做了肤浅的研究,做了几张图,放在下面,给需要的同学。
因为资料的不完整,有些可能不准确或是错误的,肯请各位指正。
这三家代表了三种流派,淘宝走的是开源路线,个人也比较推崇这种方式,但对技术人员的要求较高,比较少有公司勇于走这种路线,可能只有马云这种对技术不懂的,才能放手让技术人员自由发展。
京东的刘强东自己懂开发,从一开始就构架在.Net上面,现在已经是尾大不掉,随着发展已经开展痛苦的转型中。
苏宁易购因为内部ERP,CRM已有大量的应用,所以选用了底层、业务层比较成熟的商用套件IBM WCS,在业务构架方面还是有可取之处,但苦于技术、开发层面熟悉电商的高水平顾问缺乏,苏宁目前通过招聘Java开发人员,准备加强自身的开发能力。
下面是几张不涉及到项目机密可以拿出来讨论的图,欢迎大家讨论指正,邮件可发至我的邮箱:fengqiang # gmail.com
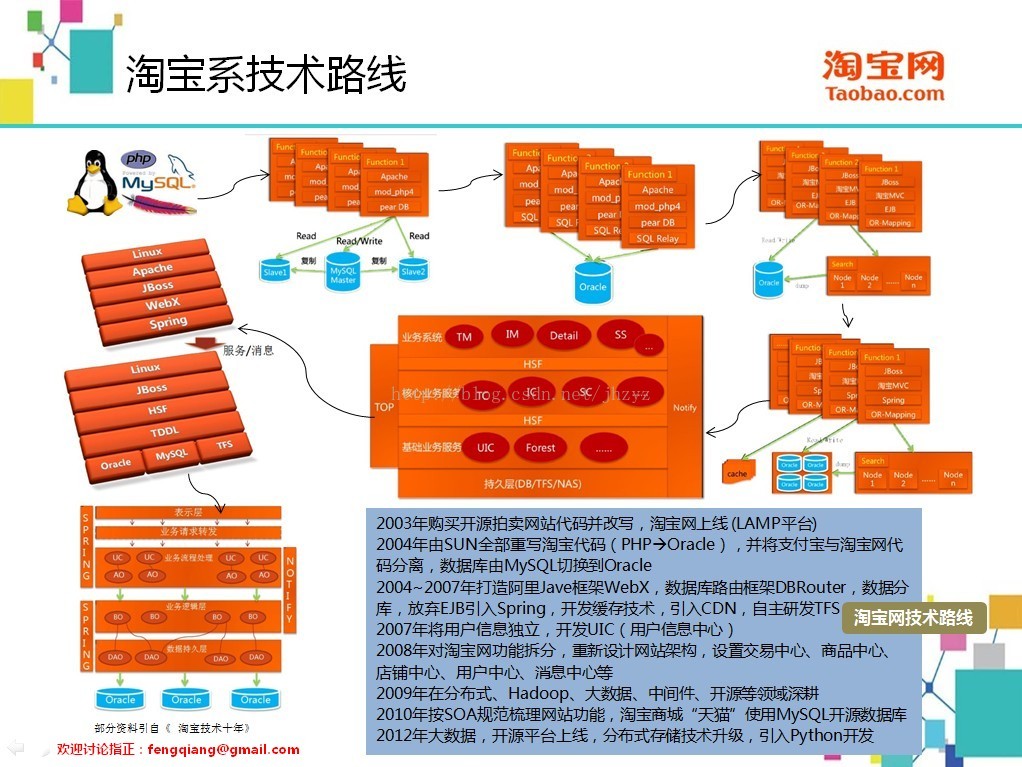

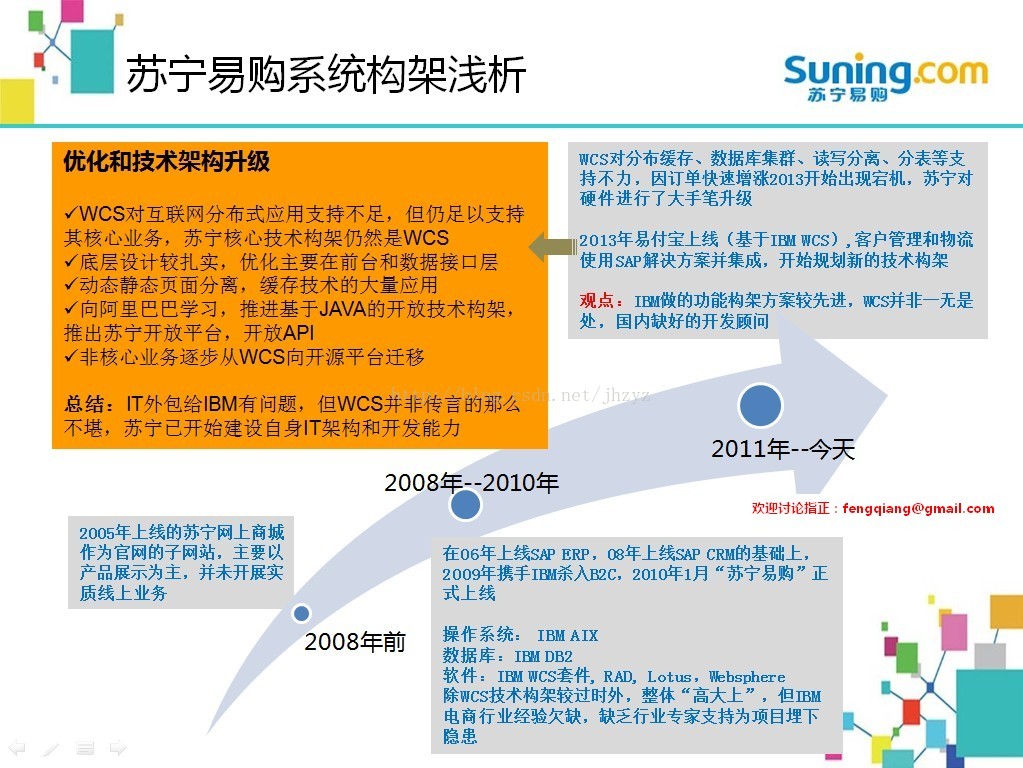
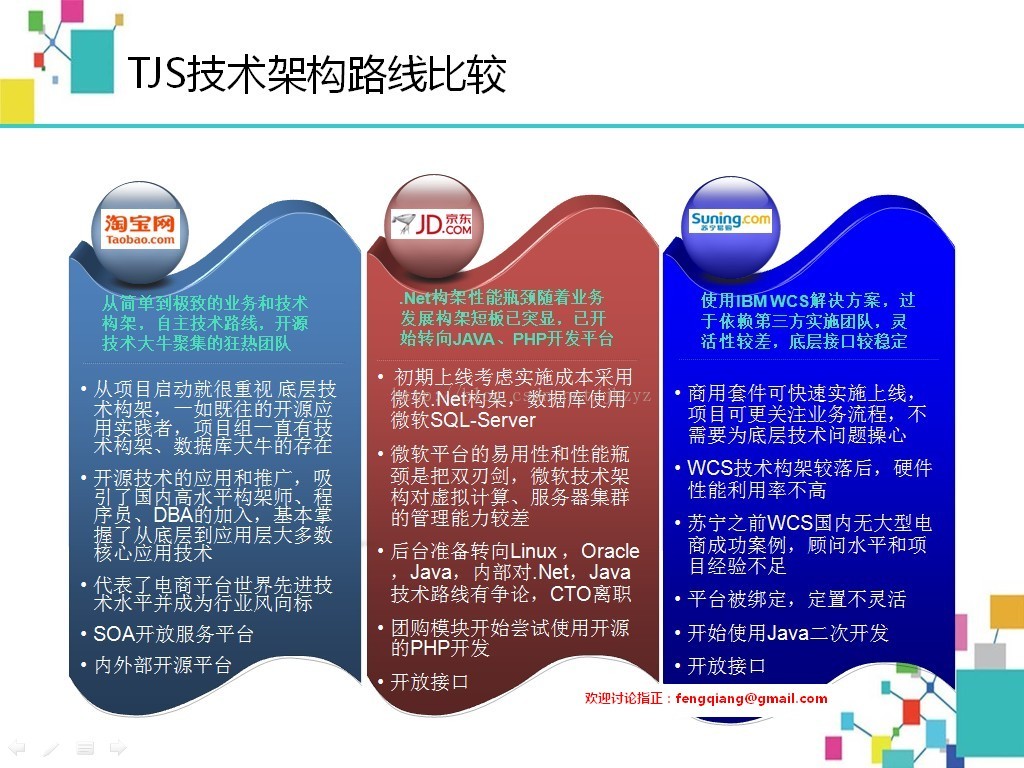















 2159
2159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









