







基本概念
1.字节
无论是内存还是硬盘,计算机存储设备的最小信息单元叫“位(bit)",我们又称之为“比特位”,通常用小写的字母”b”表示。
而计算机中最小的存储单元叫“字节(byte)”,通常用大写字母”B”表示,字节是由连续的8个位组成。
例如 :01101111 这个8位二进制数就占了一个字节的存储容量。
当然除了字节,还有更大的单位,如:
1B = 8 bit
1KB = 1024B
1MB = 1024KB 等等
回顾一下基本数据类型在内存中的占用:
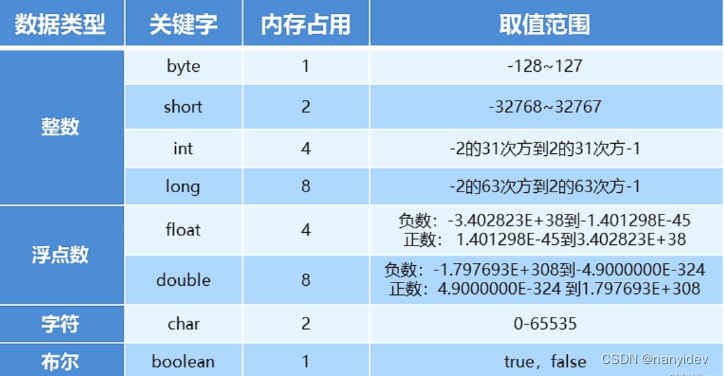
2.字符
字符的概念比较大,可以说任何一个文字或符号都可以称之为字符。但是不同的字符占用的字节不同,因为存在不同的编码方式。
例如,符号 ? 是一个字符,汉字 中国 是两个字符。在GBK编码中一个汉字占2个字节,在UTF-8编码中一个汉字占3个字节。
常见字符集
为了显示字符,国际组织就制定了编码规范,希望使用不同的二进制数来表示代表不同的字符,这样电脑就可以根据二进制数来显示其对应的字符。所以通常就称呼其为XX编码,XX字符集。
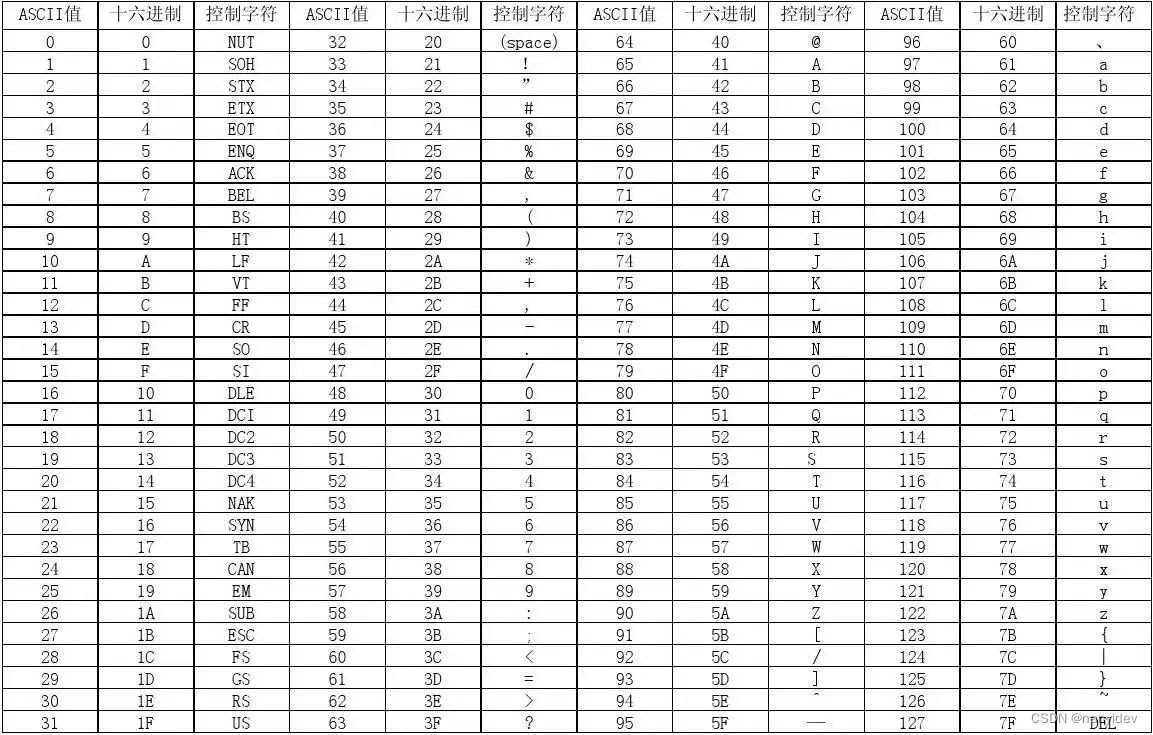
1.ASCII
- ASCII(American Standard Code for Information Interchange,美国信息交换标准代码):包括了数字、英文、符号
- ASCII使用 1个字节 存储一个字符,一个字节是8位,总共可以表示128个字符信息(对于表示英文、数字来说是够用的)
比如:
01100001 = 97 => a
01100010 = 98 => b
具体如下图:
常用链接
1.ASCII码表查询(详细说明)
2.在线ASCII编解码(方便转换)
2.GBK
- GBK(Chinese Internal Code Specification)是中国的码表,包含了几万个汉字等字符,同时也要兼容ASCII编码,
- GBK编码中一个中文字符一般以两个字节的形式存储。
3.Unicode
- 统一码,也叫万国码。是计算机科学领域里的一项业界标准。
- UTF-8 是Unicode的一种常见编码方式。(还有UTF-16,UTF-32等)
- UTF-8编码后一个中文一般以三个字节的形式存储,同时也要兼容ASCII编码表。
链接:
UTF-8编解码
4.常用字符集比较
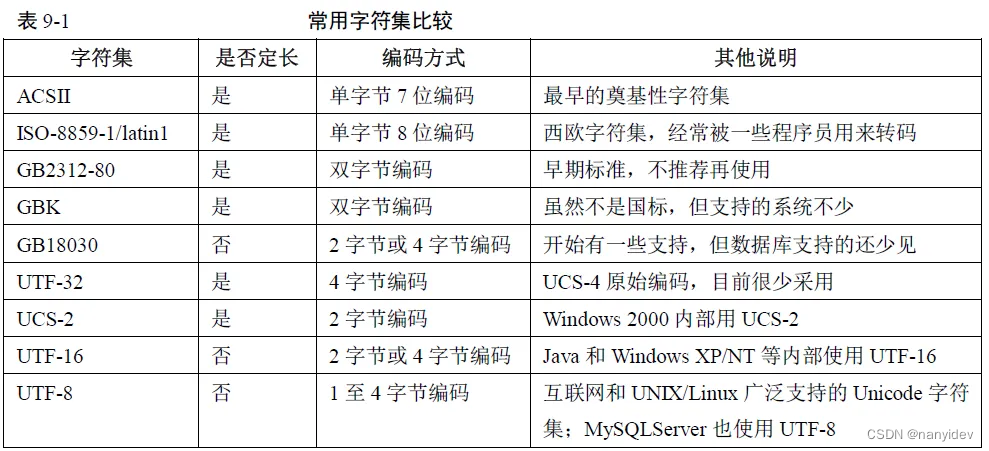
编码与解码
编解码过程:
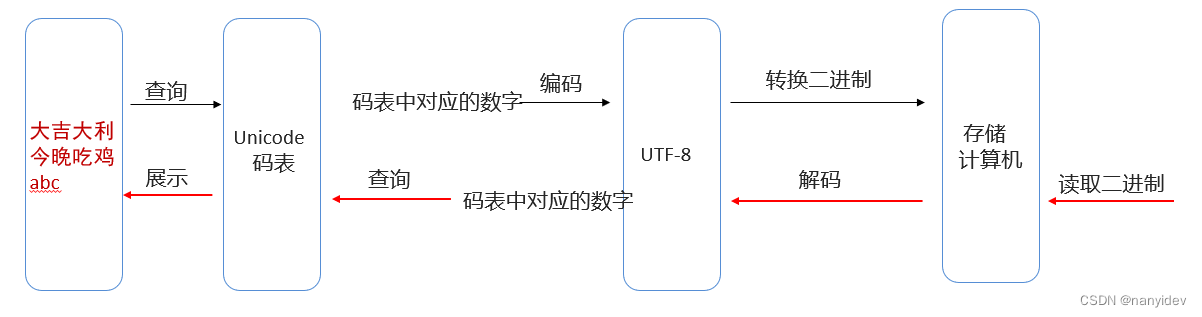
字符解码时使用的字符集和编码时使用的字符集 必须一致,否则会出现乱码。
总结一下编码的常识:
- 英文和数字等在任何国家的字符集中都占1个字节
- GBK字符中一个中文字符占2个字节
- UTF-8编码中一个中文1般占3个字节
代码实战
编码:
| 方法名称 | 含义 |
|---|---|
| byte[] getBytes() | 使用平台的默认字符集将该String编码为一系列字节,将结果存储到新的字节数组 |
| bytel getBytes(String charsetName) | 使用指定的字符集将该String编码为一系列字节,将结果存储到新的字节数组中 |
解码:
| 构造器 | 含义 |
|---|---|
| String(byte[] bytes) | 通过使用平台的默认字符集解码指定的字节数组来构造新的String |
| String(byte[] bytes,String chansetName) | 通过指定的字符集解码指定的字节数组来构造新的String |
用java演示一下:
String s = "abc国庆快乐";
byte[] bs = s.getBytes(); // 以当前代码默认编码方式编码(UTF-8)
System.out.println(bs.length); // 输出编码后的长度
for(byte b:bs)
System.out.print(b+" ");
输出:
15
97 98 99 -27 -101 -67 -27 -70 -122 -27 -65 -85 -28 -71 -112
因为是UTF-8,所以一个中文占用三个字节,所以总共的长度为15,另外,-27,-101,-67 三个字节表示汉字 国 。
然后,解码:
String newS = new String(bs);
System.out.println(newS);
输出:
abc国庆快乐
注意,如果编解码的方式不同,会造成乱码(例如用GBK编码,用UTF-8解码,因为GBK中一个汉字占两个字节,而UTF-8占三个字节,所以编解码时肯定会造成乱码)














 2233
2233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









