






一、ASCII和GBK字符集
计算机存储一个英文字符需要一个字节。
ASCII字符集,包括128(0000000B~1111111B)个数据,存储英文字母和字符,对于欧美国家够用。
例如,存储字符’a’,查询ASCII得到为97,二进制为1100001B,计算机进行编码,ASCII编码规则为“前面补0,补齐8位”,所以’a’存储位01100001B。
当从硬盘上读取’a’时,读到01100001B,解码时直接将二进制转化为十进制,再通过查询ACII得出结果。

GB2312-80:中华人民共和国国家标准信息交换用汉字编码字符集基本集。GB表示标准,2312是版本号,80表示年份1980年,只有简体汉字。
GBK中的K是扩的首字母.GBK字符集包括繁体汉字。GBK是对GB2312的扩展,不仅支持简体中文,还支持繁体中文。然而,虽然GBK支持繁体汉字,但并不是所有的繁体汉字都被GBK收录。对于需要处理大量繁体汉字的场景,可能需要考虑使用更全面的字符集,如Unicode等。
windows系统简体中文版默认使用的就是GBK。

有时在文件中会看见编码方式为ANSI,表示使用平台默认的字符集和编码方式,windows简体中文使用GBK。
后来,美国国家标准协会提出了国际标准字符集Unicode(万国码),它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息交换。
GBK的存储规则:
(1)英文也是使用一个字节进行存储,完全兼容ASCII。
(2)汉字用两个字节存储。高位字节二进制一定以1开头(为了与英文区分开,英文的字符开头位0 ),转成十进制之后是一个负数。
GBK读取字节流时,遇到以0开头的字节则表示英文的一个字符,遇到以1开头的字节,则表示这个字节与后面的一个字节组合起来表示一个汉字。
二、Unicode
Unicode
UTF-16编码规则:用2-4个字节保存。英文转为16位。其他文字可能更长。
UTF表示Unicode Transfer Format,即Unicode字符集转换模式。16表示转为16个比特位。
UTF-32编码规则,固定使用四个字节保存。
UTF-8编码规则:用1~4个字节保存。不同国家长度不同,只需记住ASCII码用一个字节(第一位为0),简体中文用3个字节(第一个字节前4为固定为1110,第二个字节前两位固定为10,第三个字节前两位固定为10)。
注意:UTF-8不是字符集,是编码规则(Unicode字符集的编码规则)。ASCII、GRK、Unicode是字符集。
例如:
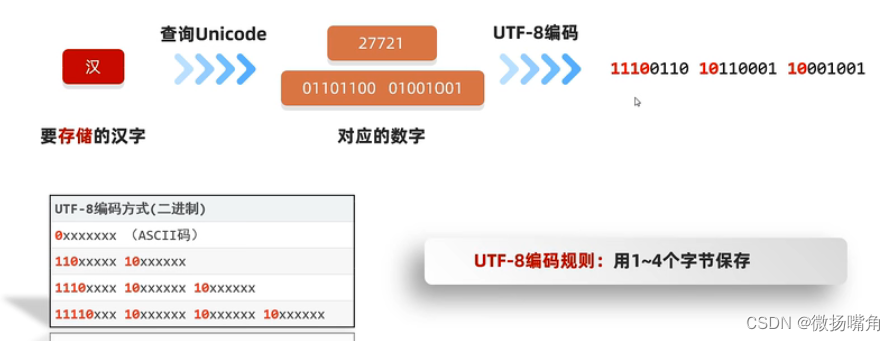
注意:字符集除了对不同字符进行编码,存储之前还有一个编码的过程。查询Unicode找到指定字符的编码,转为二进制数后,使用UTF-8编码规则进行编码,固定位不变,其他位用得到的二进制数进行填充。
三、乱码原因
原因1:读取数据时未读完整个汉字。


注:只读了三分之一的中文,查不到对应字符,有的系统显示?,有的显示方框。
原因2:编码与解码方式不统一。
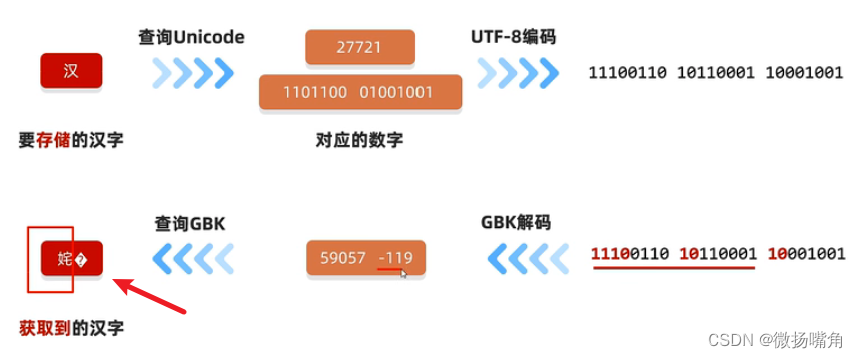
59057转化为二进制数为1110 0110 1011 0001。
如何不产生乱码:
(1)不要用字节流读取文本文件;
(2)编码解码时使用同一个码表,同一个编码方式。
四、java中的编码与解码

注:使用默认方式可以通过看软件的指定位置。
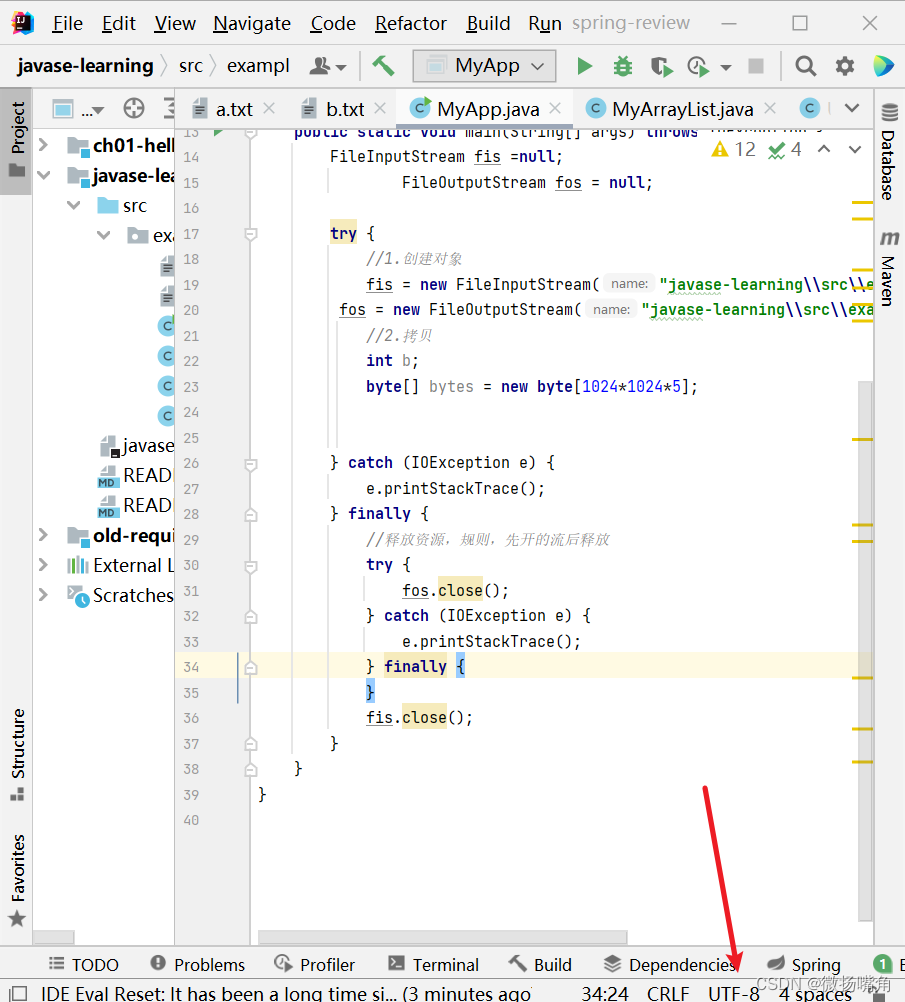
可以看出上图中显示idea默认使用UTF-8编码。
例如:
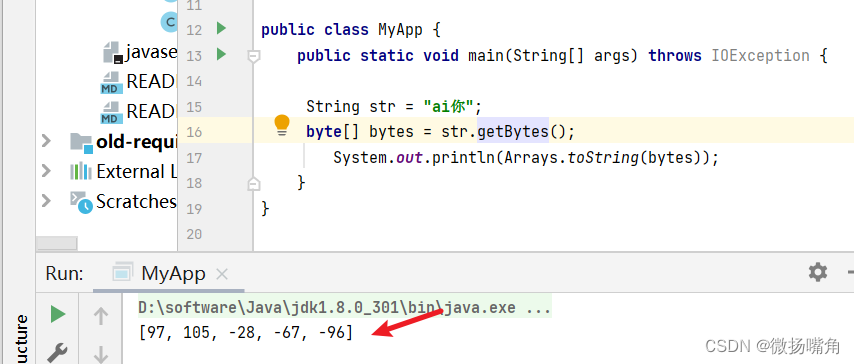
字符串"ai你"通过UTF-8编码,'a’和’i’为一个字节,'你’三个字节。
再例如:
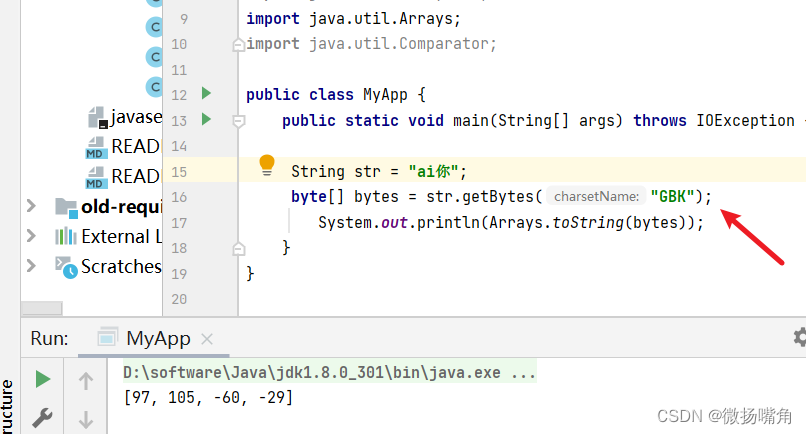
指定使用GBK编码方式,'a’与’i’为一个字节,'你’为两个字节。
解码的例子:
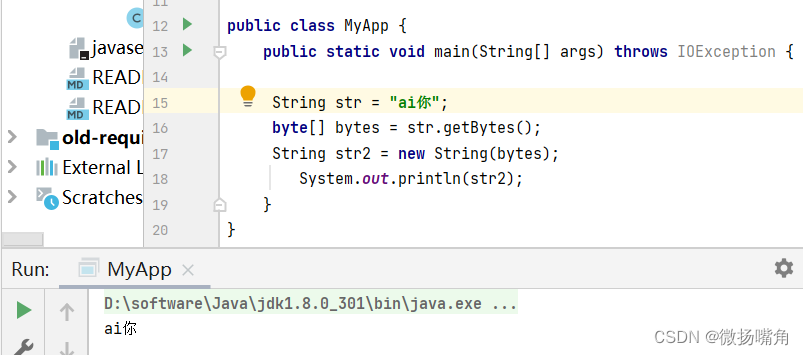
使用默认解码方式UTF-8:
再例如,指定GBK的解码方式:
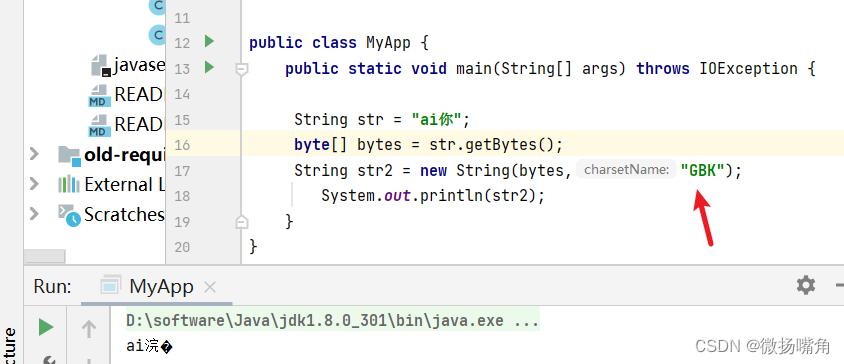
因为编码默认为UTF-8,而解码使用GBK,造成乱码现象。















10-05
 1156
1156
1156
10-27
2716
2716
04-11
440
440
05-30
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









