







什么是位移
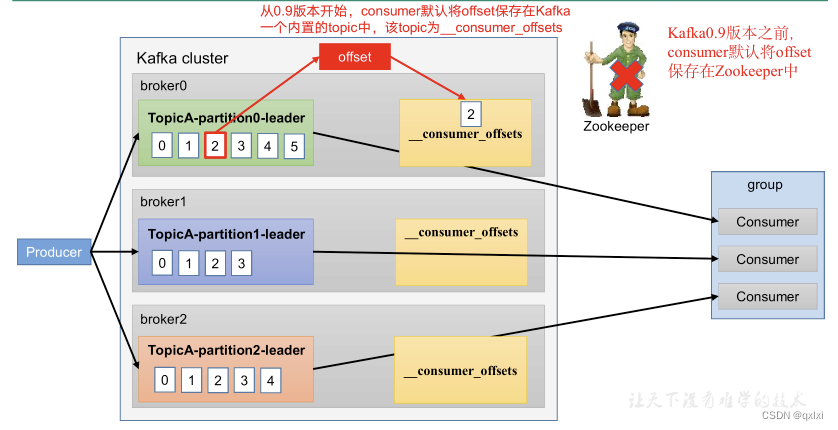
位移说白了就是消费者消费对应的Topic的分区的消费位置,之前存储到ZK中,后来转移到Kafka默认的Topic中。结构是采用key+value形势存储的,key是groupId+topic+分区号,value是offset的值。
而上述的存储就在_consumer_offsets,即位移主题。
为什么Kafka从ZK转移到Kafka内部呢?
我们知道针对位移这种操作是一个频繁的写操作,而ZK本身不支持高频的写操作。并且由于Kafka本身提供高持久性和高频的写操作,所以将位移管理移交给Kafka就是水到渠成的事情。
Kafak的位移主题和普通的主题有什么区别嘛?
其实位移主题和普通的主题没有区别,只不过是专门存储位移相关的数据。但是一般不建议程序员对位移主题进行写入和消费。Kafka Consumer API会自动完成这件事情。
位移主题的格式是什么样子呢?
如何让我们来设计的话,那么如何标记消费者所在的位移,而GroupId就是唯一值,不仅仅对于一个消费者适用,对于多个消费者也是适用的。而消费者消费的是分区级别的数据,所以就是<GroupId、Topic、分区>,这就是Key的形式,但是具体的Value呢,除了保存基本的位移数据外,还保存了Consumer Group的信息以及删除Group的信息。
位移主题如何创建的?
- Kafka集群的第一个消费者程序启动的时候,自动创建位移主题。默认是50个分区,offsets.topic.num.partitions 进行设置。副本数默认是3,offsets.topic.replication.factor。
位移的提交方式
上面我们说了位移是什么,以及具体格式,创建时机,但是什么时候提交位移,Kafka有两种方式,一种是自动提交,另一种是手动提交,可以通过参数来进行设置。enable.auto.commit,默认是true。自动提交。
从用户的角度来说分为手动提交和自动提交,从Consumer端的角度来说,位移提交分为同步提交和异步提交
自动提交
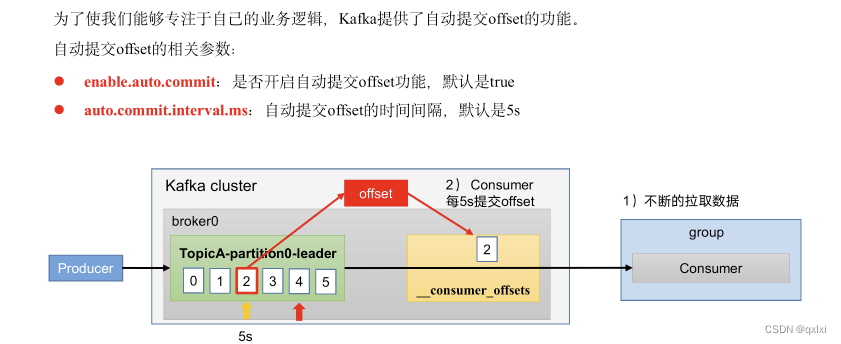
自动提交位移是默认机制,但是存在一个问题,就是会无限制的向位移主题写入消息。
假设生产者写入一条消息,位移为1,消费者消费了1,生产者之后没有写入,那么消费者会一直给位移主题不停写入位移=1的消息,其实本身值保留一条就可以,时间久了对于磁盘会撑满。
Compact策略
既然提交会有磁盘爆满的风险,那么kafka是如何处理的呢,其实Kafka会有整理的过程,适用Compact策略,说白了就是如果K1的提交时刻早于K2,那么K1其实就没有必要保存,删除K1就可以。以下是Kafka官网的Compact的过程。因为K1的V1版本早于K1的V4版本,所以值保存一份。同理别的数据也是一样的。
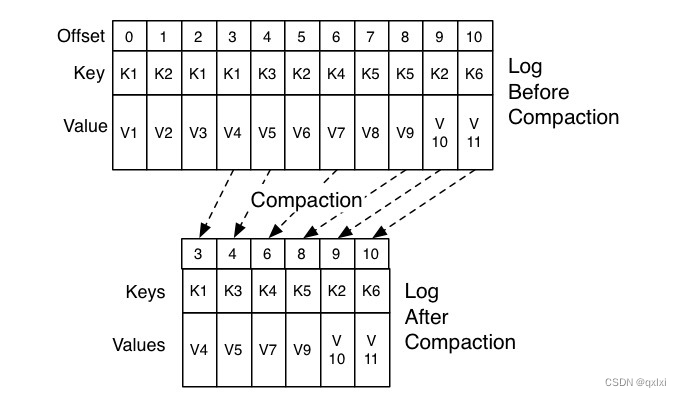
对于专门处理Compact策略,有一个后台线程即 Log Cleaner。
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test1");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"2000");
KafkaConsumer<String,String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
kafkaConsumer.subscribe(Arrays.asList("test1"));
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> c : consumerRecords) {
System.out.printf("offset = %d, key = %s, values = %s%n",c.offset(),c.key(),c.value());
}
}
以上就是自动提交位移,Kafka Consumer API会每5秒自动提交一次位移。
手动提交
手动提交 enable.auto.commit 设置为false, 只是告诉Kafka ConsumerAPI不要自动提交位移,但是需要调用相应的API手动提交位移。
同步提交
同步提交的方式是通过consumer.commitSync(),这个方法会一直等待位移提交结果,除非出现一次,被catch住。
但是我们知道,只有当从poll中获取消息处理完毕业务逻辑之后,才进行位移提交。如果过早的提交位移,那么可能出现消费数据丢失。
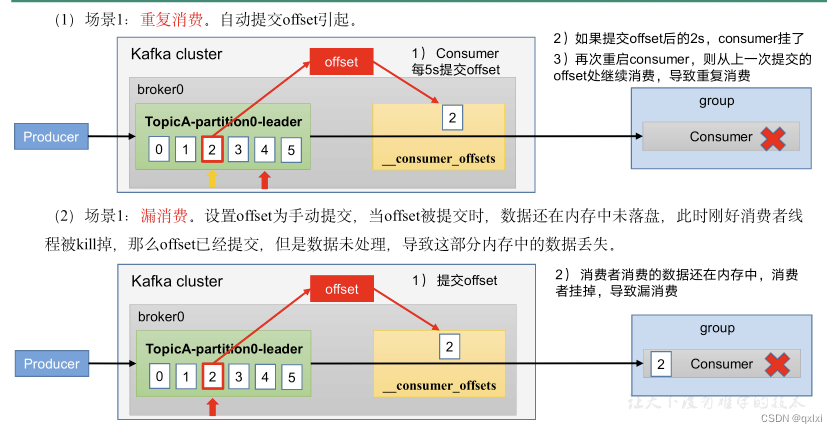
自动提交 存在重复消费 而针对自动位移提交来说,虽然可以保证从顺序上消息按照批次进行消费,不会出现消息的丢失,但是可能存在消息重复消费的问题,这也就是一般消费者需要有幂等机制进行限制。
比如默认是5S提交一次位移,但是当提交位移之后的3S发生了rebalance,那么下次消费者消费的位移会从3S之前的位移开始消费,也就是说可能3S前的数据重新消费一次。
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
//处理消息
try {
kafkaConsumer.commitSync();
} catch (Exception e) {
//处理异常
e.printStackTrace();
} finally {
kafkaConsumer.close();
}
}
同步提交其实虽然可以很灵活的控制提交时间和频率,但是因为需要同步等待,必须等待Broker返回结果流程才能执行下去,而这种是非常影响系统的TPS,因为非资源限制而导致的阻塞是系统的瓶颈。如果拉长提交时间,那么可能consumer重启之后,重新消费的消息更多。所以也就引出了异步提交的方式。
异步提交
同步的问题是影响系统的TPS,而异步不会,会通过回调函数来进行结果的通知,成功的情况是是没有问题,但是失败的情况下,如果重试的话,因为是异步的方式,所以可能A消息因为各种原因导致消费失败,但是此时已经执行了B、C消息,如果重试的话,那么A小时可能已经过期或者不是最新值。所以异步提交的方式重试没有意义。
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
//处理消息
try {
kafkaConsumer.commitAsync((offsets, exception) -> {
if (Objects.nonNull(exception)) {
//处理异常
}
});
} finally {
kafkaConsumer.close();
}
}
一般来说我们更加推荐在实际的生产环境中使用同步+异步的方式提交,这样即避免了因同步带来的无效等待,也可以保证位移可以准确提交。
try {
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
process(records); // 处理消息
commitAysnc(); // 使用异步提交规避阻塞
}
} catch (Exception e) {
handle(e); // 处理异常
} finally {
try {
consumer.commitSync(); // 最后一次提交使用同步阻塞式提交
} finally {
consumer.close();
}
}
精细化的提交
需要注意的是Kafka默认每次提交位移都是按照消费位移的最大值提交,比如消费者从Broker拉取了100条消息,那么位移如何原来是0的话,当kafka消费完这批次的数据,位移提交会提交100。这样就存在一个问题那就是我们可能不想每次都消费完100在提交,如果在这个过程中出现不可控异常,那么需要全部重新消费一次,我们可以通过配置比如消费50个消费就提交。
其实以上的思想就是将大事务切分成小事务,这样即使出现异常情况,也只需要从已经提交的位移处开始消费,具体的方式就是通过 commitSync(Map<TopicPartition, OffsetAndMetadata>) 和 commitAsync(Map<TopicPartition, OffsetAndMetadata>) 具体大家可以自行Google。这里就不细说了。
生产经验
漏消息和重复消费
重复消费:已经消费了,但是offset没有提交
漏消息:提交了offset但是没有消费
小结
本篇文章主要描述了位移以及相关位移提交的方式。
首先针对位移这是消费者消费位置通过在Broker进行持久化数据的过程,位移有相应的位移主题,以及位移提交方式,自动提交和手动提交。自动提交中可能存在消息重复提交的情况,通过compact策略来解决,而手动提交的方式有同步和异步方式,显然两者都存在一定的优缺点,所以需要两种方式结合,也可以根据不同的业务来进行精细化的提交。其实可以从代码层面看,不同的方式有不同的优缺点,而提高的更高纬度的架构,也是一种trade-off,这可能就是架构与代码设计的艺术吧。















 205
205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











