







最近要做一个数字车间的物联网项目,数据存储成了首先要解决的问题,整个车间一共104台数控机床,1s钟采集1次数据,360024365*104=3,279,744,000 ,一年要产生32亿条记录,这个数据量用常见的关系型数据库肯定是不行的,所以数据库选型成了第一要考虑的问题。
最近几年随着物联网的兴起,时序数据库也开始流行起来,时序数据是随时间不断产生的一系列数据,简单来说,就是带时间戳的数据。时序数据库 (Time Series Database,TSDB) 是优化用于摄取、处理和存储时间戳数据的数据库。此类数据可能包括来自服务器和应用程序的指标、来自物联网传感器的读数、网站或应用程序上的用户交互或金融市场上的交易活动。
时序数据的主要数据属性如下:
每个数据点都包含用于索引、聚合和采样的时间戳。该数据也可以是多维的和相关的;
写多读少,需要支持秒级和毫秒级甚至纳秒级高频写入;查询通常是多维聚合查询,对查询的延迟要求比较高
数据的汇总视图(例如,下采样或聚合视图、趋势线)可能比单个数据点提供更多的洞察力。例如,考虑到网络不可靠性或传感器读数异常,我们可能会在一段时间内的某个平均值超过阈值时设置警报,而不是在单个数据点上这样做;
分析数据通常需要在一段时间内访问它(例如,给我过去一周的点击率数据);
虽然其他数据库也可以在数据规模较小时一定程度上处理时间序列数据,但 TSDB可以更有效地处理随时间推移的数据摄取、压缩和聚合。以车联网场景为例,20000辆车,每个车60个指标,假设每秒采集一次,那么每秒将上报20000 * 60 = 1200000指标值,即120W数据指标值每秒,每个指标值为16字节(假设仅包括8字节时间戳和8字节的浮点数),则每小时将产生64G左右的数据。而实际上每个指标值还会附带标签等额外数据,实际需要存储空间会更大。
简而言之,时序数据库是专门用于存储和处理时间序列数据的数据库,支持时序数据高效读写、高压缩存储、插值和聚合等功能。
db-engines最新的时序数据库排名情况:
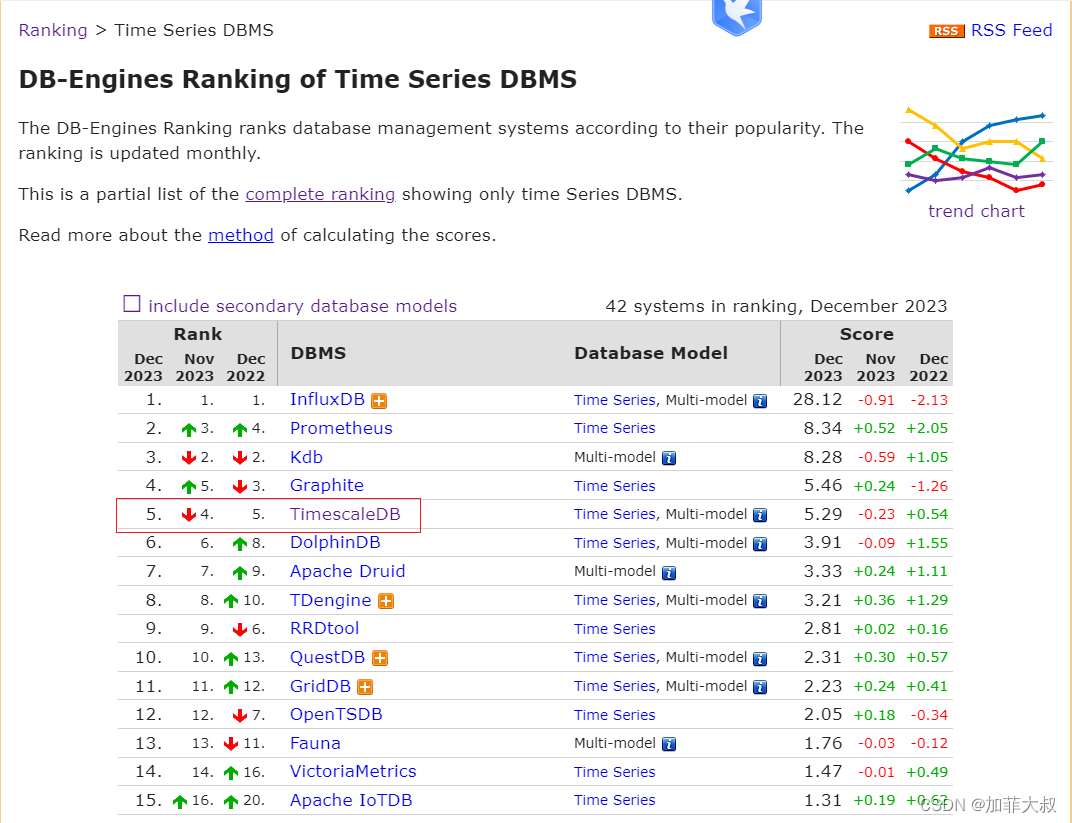
InfluxDB遥遥领先,不过为了降低学习成本和开发成本,我选择了排名第5的TimescaleDB, 原因很简单,这是在postgresql的基础上开发的时序数据库,可以跟postgresql无缝集成,对sql的支持也是最好的,而这个项目选用的web开发框架是Odoo,Odoo用的数据库也是Postgresql, 选用TimescaleDB无论是开发成本还是后期的维护成本都比较低。















 4043
4043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









