 经典文本匹配算法详解:从Jaccard到BM25
经典文本匹配算法详解:从Jaccard到BM25








文本匹配主要是将两段文本进行相似度计算,以选择最匹配的内容,如搜索场景下选择相似的内容、问答场景下在问题库中匹配最相近的问题并返回对应的回答等。也可延伸用于序列形式的匹配,如地址匹配、路径序列等。
本文主要整理一下经典的文本匹配/相似度计算算法,包括Jaccard相似度、Levenshtein编辑距离、Simhash、TF-IDF、BM25。
Jaccard相似度
参考链接:https://en.wikipedia.org/wiki/Jaccard_index
Jaccard相似度,是用于比较有限样本集合的相似性的统计量,定义为两个集合的交集与并集的比例。
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ = ∣ A ∩ B ∣ ∣ A ∣ + ∣ B ∣ − ∣ A ∩ B ∣ 0 ≤ J ( A , B ) ≤ 1 J(A,B)={
{|A\cap B|} \over {|A\cup B|}}={
{|A\cap B|} \over {|A|+|B|-|A\cap B|}}\\ 0 \le J(A,B) \le 1 J(A,B)=∣A∪B∣∣A∩B∣=∣A∣+∣B∣−∣A∩B∣∣A∩B∣0≤J(A,B)≤1
对应的Jaccard距离为:
d J ( A , B ) = 1 − J ( A , B ) = ∣ A ∪ B ∣ − ∣ A ∩ B ∣ ∣ A ∪ B ∣ d_{J}(A,B)=1-J(A,B)={
{|A\cup B|-|A\cap B|} \over |A\cup B|} dJ(A,B)=1−J(A,B)=∣A∪B∣∣A∪B∣−∣A∩B∣

Levenshtein编辑距离
参考链接:
https://zh.wikipedia.org/wiki/%E8%90%8A%E6%96%87%E6%96%AF%E5%9D%A6%E8%B7%9D%E9%9B%A2
https://zhuanlan.zhihu.com/p/43009353
Levenshtein距离,是编辑距离的一种,指两个字符串之间,由一个转换成另一个所需的最少编辑次数。其中编辑操作包括:插入、删除、替换。编辑操作可以有不同权重,这里以等权为例。求解算法通常为动态规划。
定义a、b两个字符串,则其编辑距离如下:
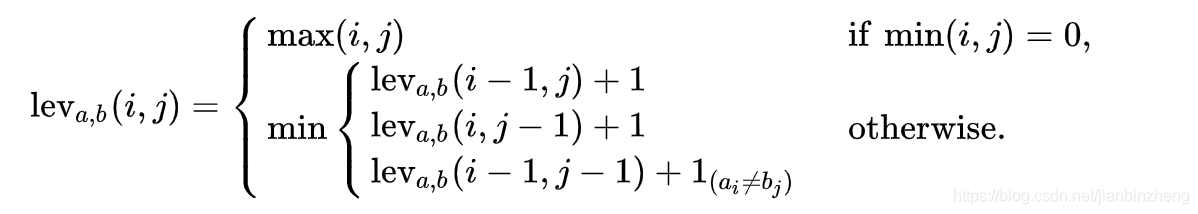
其中, lev a , b ( i , j ) \text{lev}_{a,b}(i,j) <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









