







https://zhuanlan.zhihu.com/p/363082639
文章目录
和标准的预测方法不同,由于”反事实“的存在,并没有真实的uplift标签,因此uplift模型无法在样本维度上进行评估。但如果有随机试验采集的数据,则可以用平均水平来评估uplift模型的效果。
本文将分为线上评估和离线评估两部分介绍,其中线上评估主要是AB策略;离线评估是AUUC、Qini等。
线上评估方法
最好的验证模型或策略效果的方法就是做线上的AB实验。在设计AB实验对比时,要小心处理目标的数据范围,在什么节点进行分流。
如果我们想知道的是全局的策略效果,则要在一开始就分流;而如果想知道策略生效部分的效果,则要在策略判定之后,对判定生效的部分进行分流,其中A桶原样返回,B桶生效返回。
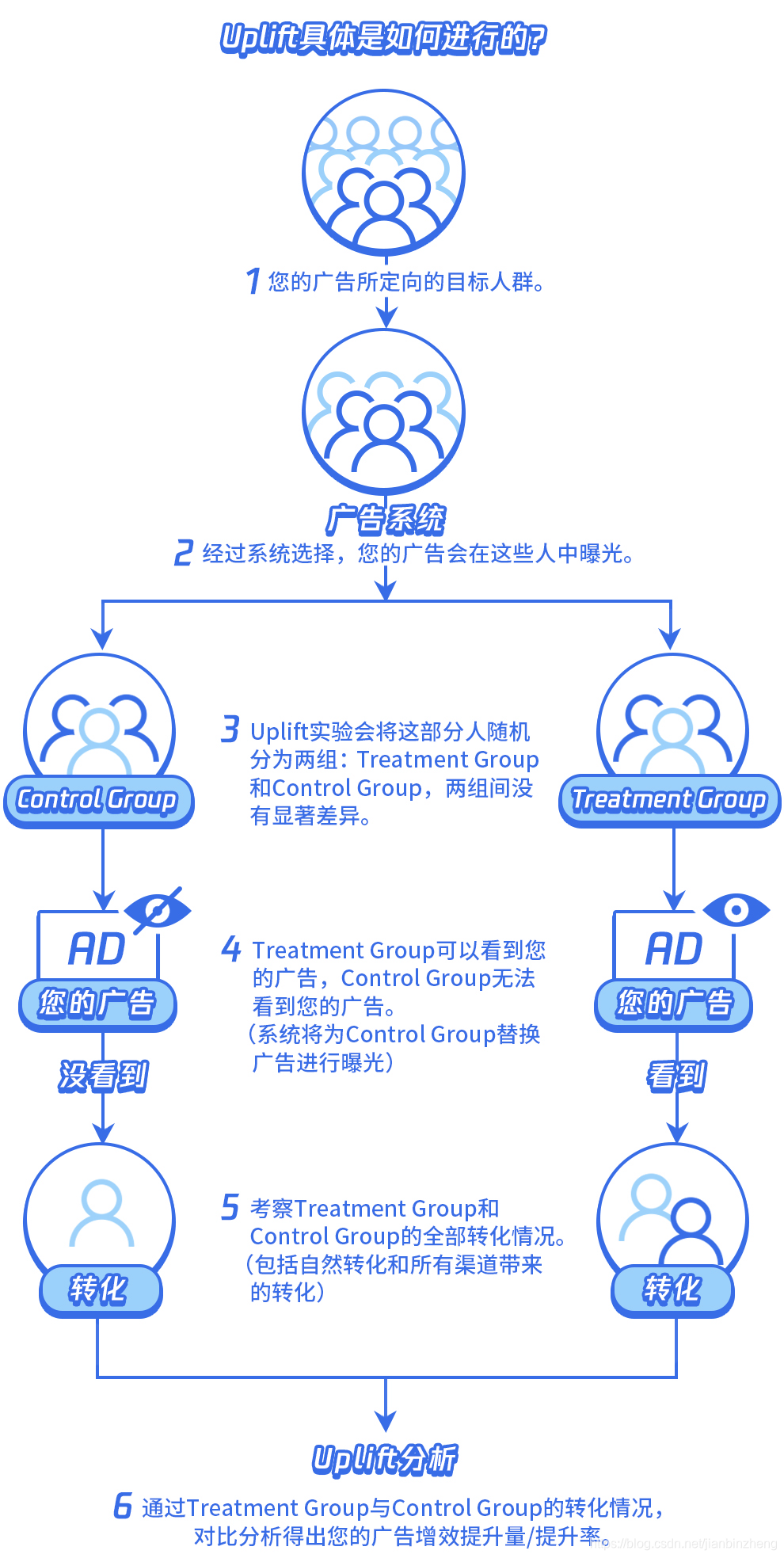
下面是腾讯广告做uplift分析的流程图示例,通过线上AB试验的方式给出增量效果。
离线评估方法
线上评估虽然准确,但我们也需要具备离线评估的能力,避免浪费线上流量。与线上评估看整体的增量不同,离线评估需要能支持模型的效果对比。
离线评估方法有很多种,都需要对数据做分组(或累积)。将所有样本按照模型给出的uplift得分降序排列,按照等比分为K组(bins),后续的效果评估则通过对比相应组内Treatment组和Control组的得分差异实现。
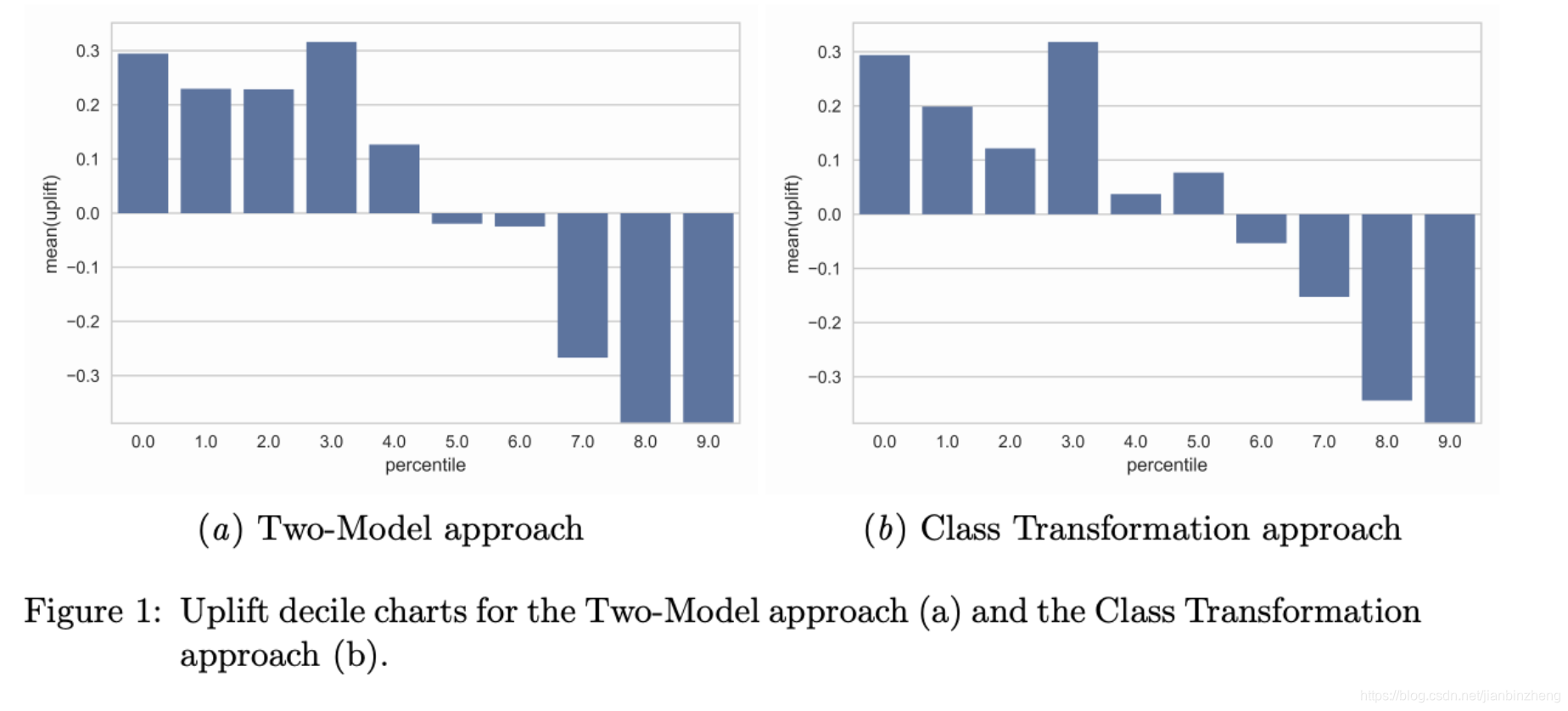
Uplift decile charts
用第k组内Treatment和Control样本的 y ˉ \bar{y} yˉ之差表示,如下图表示按照uplift得分降序排列后,前50%的样本Treatment是正效果的,而后50%是负效果。
该方法虽然直观,但很难用于进行模型间的对比,如难以说明下面两个模型的优劣。
Cumulative uplift/gain
Cumulative uplift:通过计算topK组内Treatment和Control组的 y ˉ \bar{y} yˉ差值,可以表达在topK组得分的数据内,增量效果如何。如左图。
Cumulative gain:一些场景中,我们需要的不只是按照”uplift“选中部分的效果,而需要的是根据”uplift“来决策是Treat还是Control之后,能够带来的增量绝对量有多少。如右图,此时选择最高点即为最佳效果,再往后的实际是Control组优于Treatment组的部分。
公式如下, Y Y Y表示分组正例数量, N N N表示分组总量, ⋅ T \cdot^T ⋅T表示Treatment组, ⋅ C \cdot^C ⋅C表示Control组。
( Y T N T − Y C N C ) ( N T + N C ) \left(\frac{Y^{T}}{N^{T}}-\frac{Y^{C}}{N^{C}}\right)\left(N^{T}+N^{C}\right) (NTYT−N
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









