







 本文介绍了如何使用Python通过12306API抓取列车信息,包括理解查询接口来源,提取查询结果中的关键字段,以及设置命令行参数查询的方式。示例代码演示了查询过程,提到了需要改进的地方,如支持更多日期格式和精确站名匹配。
本文介绍了如何使用Python通过12306API抓取列车信息,包括理解查询接口来源,提取查询结果中的关键字段,以及设置命令行参数查询的方式。示例代码演示了查询过程,提到了需要改进的地方,如支持更多日期格式和精确站名匹配。
PS:本文为学习参考实例。代码与上述大体相同。
首先了解这些查询接口是怎么来的
chrome是个好东西,特别是它的控制台能看到很多细节。
12306网站通过chrome可以看到查询票的api
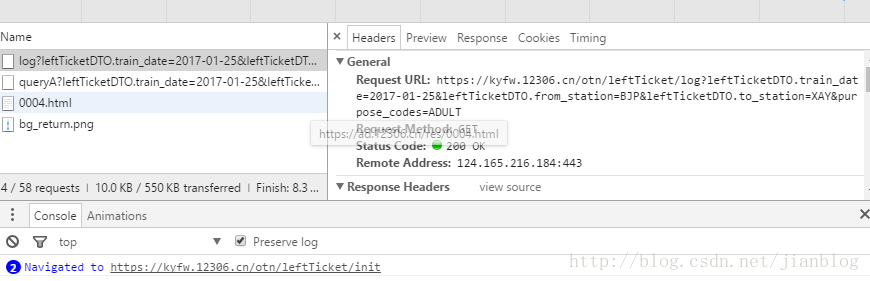
其中有log? 和 queryA?两种开头的接口,网上介绍log是判断服务是否正常,用queryA进行查询
#在python控制台测试
> import requests
> url = 'https://kyfw.12306.cn/otn/leftTicket/log?leftTicketDTO.train_date=2017-01-11&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=XAY&purpose_codes=ADULT'
# 这里传入了三个变量,
train_date
from_station
to_station
站名为缩写标准,获得方法见后面介绍
r = requests.get(url, verify = False)
#chrome可以看到它用的是get方法, verify为忽略https
解析结果r.text为字典形式的字符串,通过r.json()得到解析后结果,
ticks = r.json()
分析结构, ticks['data']保存所有车次的信息。G653车次的查询结果表示为
g653 = ticks['data'][1]['queryLeftNewDTO']
从结果中提取需要的字段展示
12306查询结果列表的表头包含如下字段:
车次 出发站/到达站 出发时间/达到时间 历时 商务座 特等座 一等座 二等座 高级软卧 软卧 硬卧 软座 硬座 无座 其他 备注
分析g653对应的key分别为:
station_train_code from_station_name/to_station_name start_time/arrive_time lishi/day_difference swz_num tz_num zy_num ze_num gr_num rw_num yw_num rz_num yz_num wz_num qt_num
车次类型分(G,D,Z,T,K)首位不是字母的是普快。
如下代码根据以上通过接口查询的结果,并根据指定列车类型过滤
#代码与参考中大体相同
#coding=utf-8
from prettytable import PrettyTable
class TrainCollection(object):
"""
解析列车信息
"""
header = '序号 车次 出发站/到达站 出发时间/达到时间 历时 商务座 特等座  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6254
6254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









