







独占
原先的实现方式是arch_spin_lock,使用 ldaxr 和 stxr 指令实现锁变量的修改。这两个指令暗含独占监视器的功能。

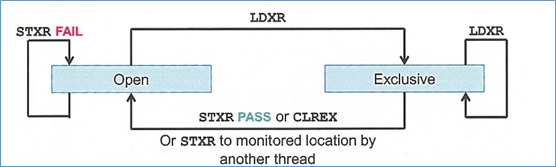
ldxr 和 stxr 是成对使用的。L = local;G = global
对于一个内存地址,没被任何 cpu 访问的话是开放的,任何 cpu 都可以去占有这段地址,只要 cpu执行 ldxr 就会标记此内存已被占有(L)。
关键点在 stxr。当 cpu 1 用 stxr 修改了独占的内存,表示该内存使用结束,重新回归开放状态(G),这里的开放所有 cpu 都看得到。
cpu 2 想去执行 stxr,发现已经不是独占(L)了,则无法修改,必须重新回归 ldxr 操作重新标记独占(L)。这个状态机保证了串行操作。
qspinlock加锁流程
用 kernel/locking/qspinlock.c 的代码注释图来理解。
qspinlock 的优化是分类优化思想:
当争用 cpu < 2 的时候,采取 ticket spinlock 机制,用 4 字节就可以处理,减少内存占用;
当争用 cpu ≥ 3 的时候,采取 MCS node 机制(增加 (N-2)个 MCS node),避免使用 ticket spinlock 机制造成多个 CPU 的 cache line 无谓刷新的问题;

293 /**
294 * queued_spin_lock_slowpath - acquire the queued spinlock
295 * @lock: Pointer to queued spinlock structure
296 * @val: Current value of the queued spinlock 32-bit word
297 *
298 * (queue tail, pending bit, lock value)
299 *
300 * fast : slow : unlock
301 * : :
302 * uncontended (0,0,0) -:--> (0,0,1) ------------------------------:--> (*,*,0)
303 * : | ^--------.------. / :
304 * : v \ \ | :
305 * pending : (0,1,1) +--> (0,1,0) \ | :
306 * : | ^--' | | :
307 * : v | | :
308 * uncontended : (n,x,y) +--> (n,0,0) --' | :
309 * queue : | ^--' | :
310 * : v | :
311 * contended : (*,x,y) +--> (*,0,0) ---> (*,0,1) -' :
312 * queue : ^--' :
313 */
存在一个拿锁对象
uncontended,无争议的情况,如果没有 cpu 持有锁,cpu A 会立即获取锁,将 locked =1。
(0,0,0) -> (0,0,1)


存在两个拿锁对象
pending,如果该锁被 cpu A 持有,cpu B 也有获取锁。
- 首先 cpu B 要设置 pending =1
- cpu B 不断 spin 等待 cpu A 释放锁,如果读到 locked =0,代表 cpu A 已经释放锁,cpu B 可以获取
- cpu B 清除自己设置的 pending = 0,然后获取锁,设置 locked =1
(0,0,1) -> (0,1,1) -> (0,1,0) -> (0,0,1)


存在三个拿锁对象
uncontended queue,这是挂在队列头部等待的情况,先处理完的锁拥有者和 pending 的锁,第三个争夺者就能获取锁。
- 如果 cpu A 持有锁,cpu B 也在等待,此时来了 cpu C 也来获取锁,这时会将 cpu C 加入 MCS 锁队列,设置 tail 值来记录 C
- cpu C 不断 spin 等待锁被释放,如果读到 locked 位和 pending 位为0,表示 cpu A 和 cpu B 都已经用完了锁,锁可以被获取
- 获取锁,将 locked 置位,清除 tail 位(队列只有 cpu C,是一个非竞争队列)
(n,x,y) -> (n,0,0) -> (0,0,1)


存在四个拿锁对象
contended queue,这是锁拥有者、pending、队列前面等待的锁处理全部完成,并成为锁拥有者同时在队列中等待而不是头部的情况。
- 如果 cpu A 持有锁,cpu B 在等待,cpu C 也在 MCS 等待队列中,cpu D 此时也要来获取锁,更新 tail 值为 D,然后把 D 挂在 C 的后面,形成一个 MCS 队列
- 当 cpu C 拿到锁前,cpu D 是基于自己的 node locked 进行 spin 等待
- 当 cpu D node 的 locked=1 时,表示 cpu D 要结束 MCS 等待队列的 spin 了,然后进入上面 cpu C 的 等待,即会同时等待 spin qspinlock 的 pending & locked 两位,当 pending=0 && locked=0 立即获取锁,而无须再进入 pending 流程
(,x,y) -> (,0,0) -> (0,0,1)
下图展示了在请求第 n 个锁获取者如何加入 MCS 队列,qspinlock tail 表示最后一个进入 MCS 队列的 CPU。

下图展示了头节点(cpu C)获取锁并退出时使下一个节点成为头节点的过程。
cpu C 将下一个节点 cpu D node 的 locked 值设置为1,同时 cpu D spin qspinlock 的 pending&locked

下图显示了在 MCS 队列中等待的 CPU 获取自旋锁的顺序。
第一个进入并在 MCS 队列中等待的 cpu 监视 val->pending 和 val->locked 变为 0 以获得自旋锁。


综上
- 对于持有 pending 位的第二个 cpu B,是 ticket 的第一继承人,在 spin 等待 qspinlock locked 位
- 对于 MCS 等待队列的队首的第三个 cpu C,是第二继承人,在 spin 等待 qspinlock locked位 && pending位
- 对于 MCS 等待队列的非队首节点,在自己的 node 副本 spin 等待 node->locked 位。
参考:
http://jake.dothome.co.kr/spinlock/
https://blog.csdn.net/m0_37797953/article/details/118223251















 909
909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









