







全球数据爬取的解决方案-国外数据爬取
引言
随着经济的持续低迷和对外贸易的需求扩大,各个公司为了更好的了解海外客户情况,最简单直接的办法就是从全球收集公共的网络数据。
无论是海外电商用户的消费习惯还是训练自己的通用人工智能chatgpt,都是需要海量和多种类型数据的支持。自然而然也就需要爬取各个网站的数据。
而现如今数据爬取的难度越来越大,各个网站都会有限制IP请求、防机器判断、限流等各种反爬虫技术。因此这不仅需要用户对爬取网站的程序频繁更新,也需要程序猿的技术手段多种多样。
而像限制IP这种从访问来源上就拒绝的网站,就需要购买代理IP来实现反向代理匿名访问。
国内的代理IP服务商有很多,但大多数都是中国或者亚洲区域内的IP地址,如果你的公司做的是全球业务,则大概率需要访问境外的一些网站数据,而境外的网站有些会限制亚洲IP访问,那针对这种情况就需要能提供全球IP代理的服务商。
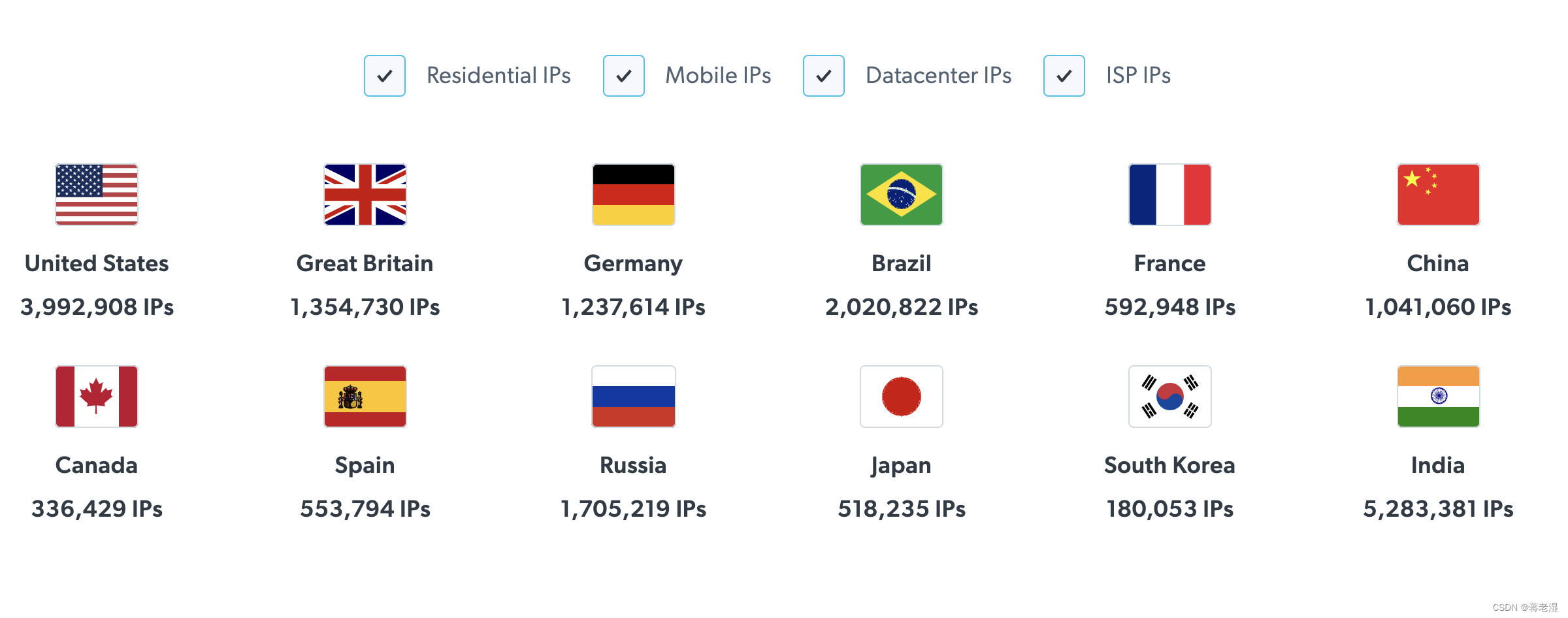
来自近195个国家的ip代理地址,有住宅IP,手机IP,数据中心IP,互联网服务供应商 IP
什么是bright data(亮数据)
bright data是一家在以色列的互联网公司,他们的主要产品是互联网数据服务,不少世界500强公司和欧美名校都是他们的客户,其实就是数据采集(爬虫),但是做到了很牛的程度。能提供各种已有收集到的互联网数据集
诸如Shoppee、Google、TikTok等电商、社交媒体、搜索引擎结果。
还有各种的基础设施服务,用来给有定制开发能力公司提供获取开放数据解决方案。
本文主要从业务场景的编码实战角度来体验一下bright data的IP代理服务,针对该平台的其他如网络解锁器,低代码数据集定制、浏览器等爬虫工具文末会简单介绍一下
代理IP服务的使用
在使用该平台IP代理之前,先需要了解以下4种IP代理网络的区别:
- 机房代理:机房代理是机房服务器分配的IP,流量通过机房代理路由,以帮助您访问世界各地的IP和位置。由于行程更短,架构简化,机房代理是最快最具成本效益的代理类型。
- ISP代理:从互联网服务提供商处购买或租用的住宅IP构建而成,用于商业用途,不供私人住宅使用。即使ISP虽然托管在服务器上,但因为目标站点将ISP IP归类为与住宅IP类似,这也是ISP代理网络较机房代理网络更低成本的优势。
- 动态住宅:拥有海量真人原生住宅IP,这些真实的IP主人自愿加入并组成IP共享社区。可以使用该类IP定位复杂、难以访问的网站,像真人一样查看或采集相关数据。
- 移动代理:由世界各地的真人移动IP组成。这些真实的IP主人自愿加入的移动网络并共享IP。这些移动住宅IP由互联网服务提供商分发,用于移动设备。
考虑到各个公司的成本控制,比较经济适用的选择方式是 ISP代理>机房代理>动态住宅>移动代理
快速开始
- 登陆birght data注册并登陆账号(支持个人与公司)
- 选择你需要的IP代理产品类型,这里选择的是ISP代理
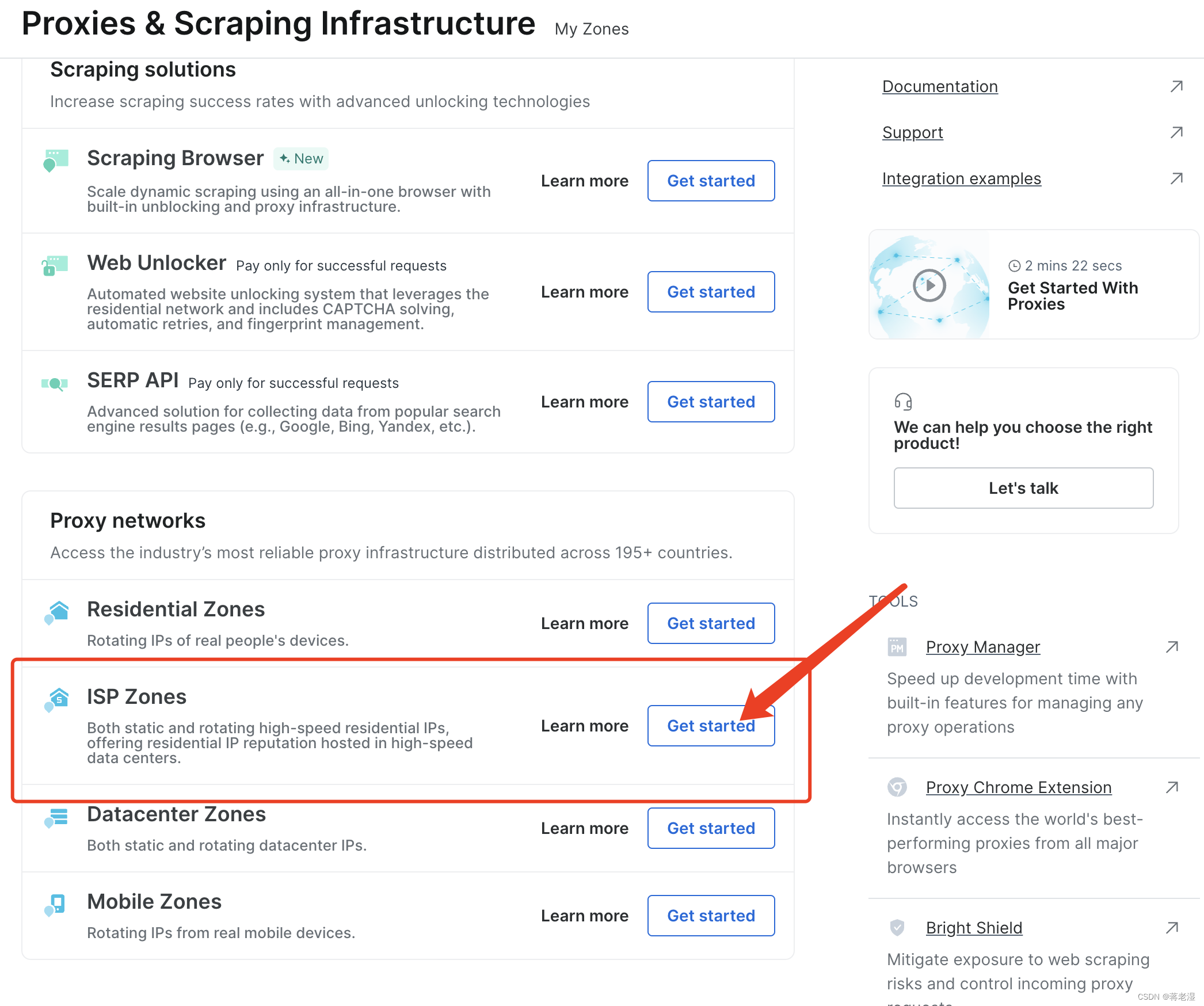
3. 设置ISP Zone代理的相关内容,如通道名称、IP类型、IP数

4. 激活代理IP通道并将本地开发机器IP加入白名单

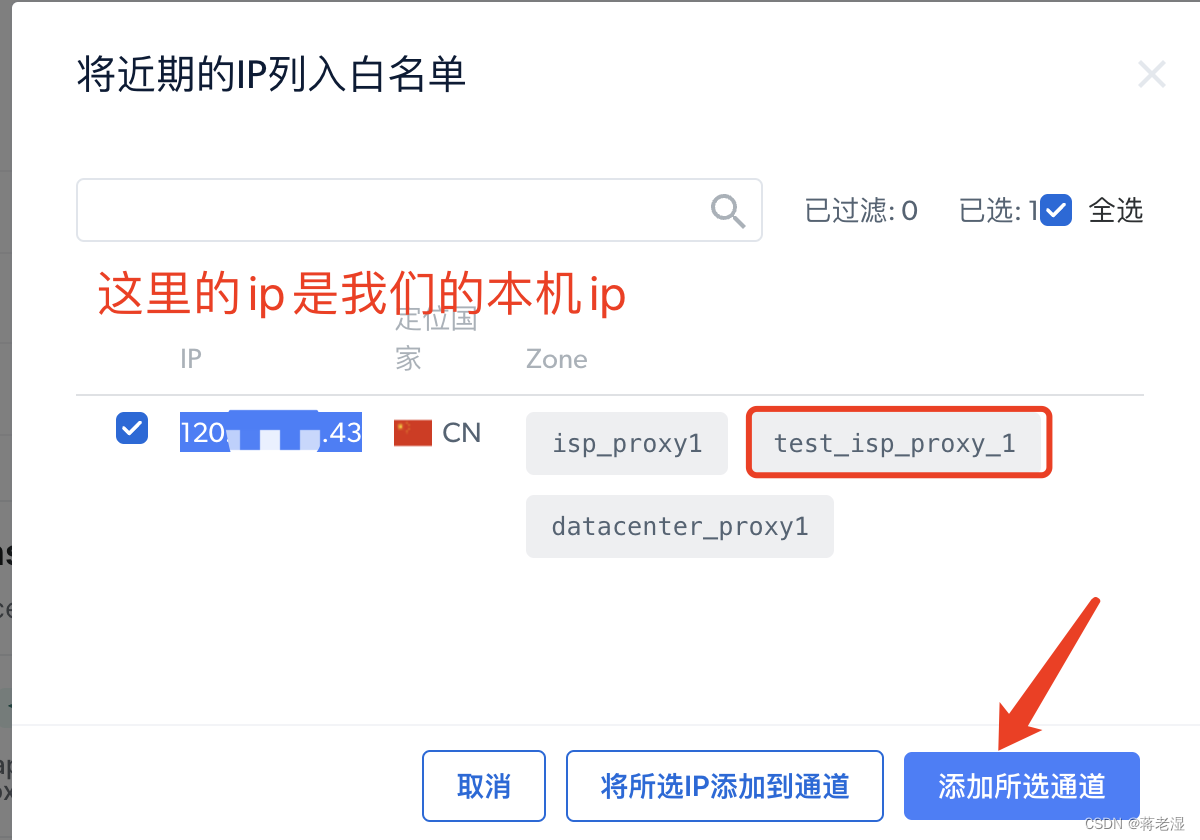
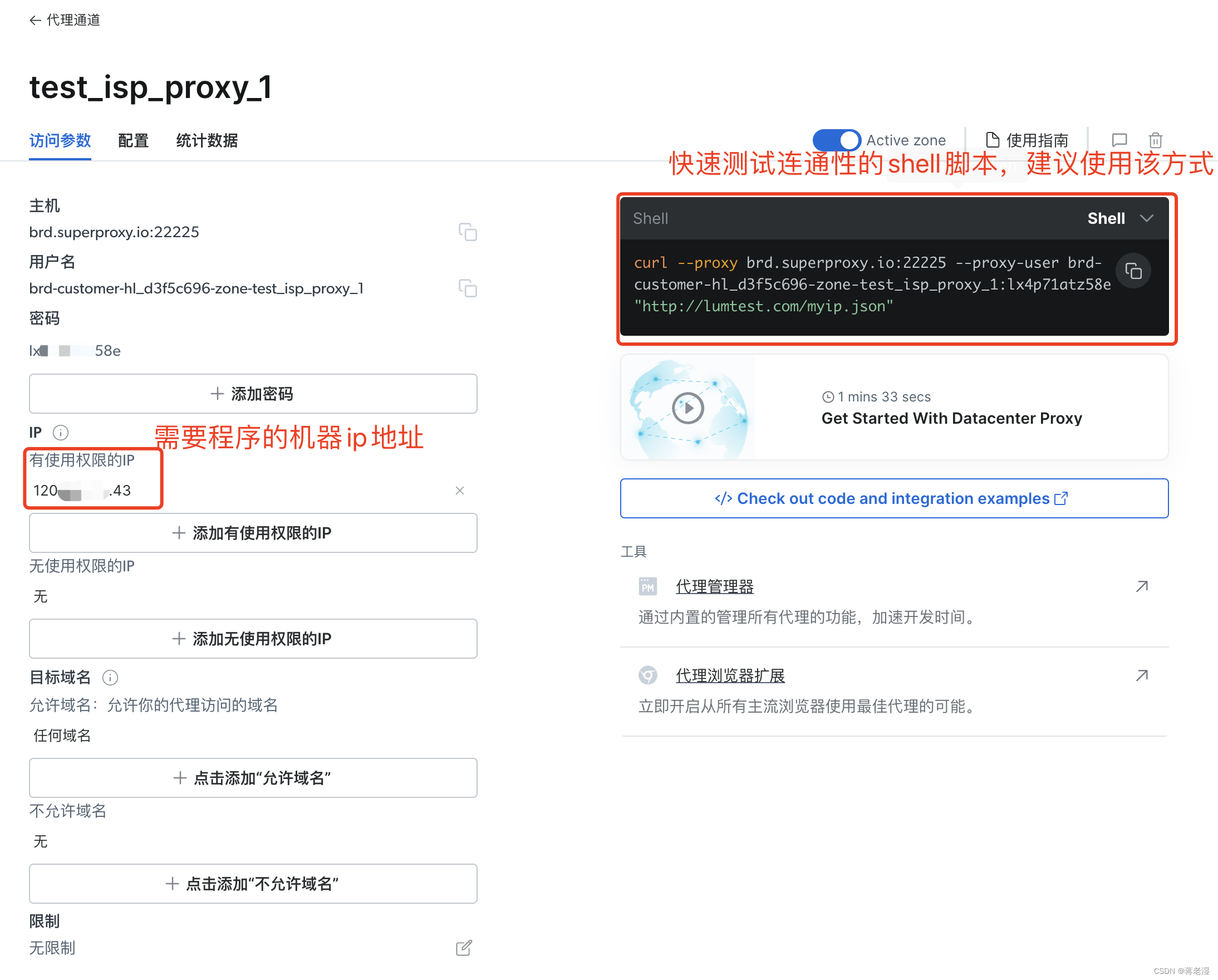
5. 测试IP代理通道连接
通过本机执行该shell脚本,既可以json的方式获取IP代理通道中已分配的IP信息
curl --proxy brd.superproxy.io:22225 --proxy-user brd-customer-hl_d3f5c696-zone-test_isp_proxy_1:lx4p71atz58e "http://lumtest.com/myip.json"
python实战-ebay电商价格跟踪
电子商务数据对于个人和公司都是很有用的信息,其中主要用途是用于价格监控、竞争对手分析、市场研究、用户消费行为分析等。
这里我们抓取ebay电商平台的数据,不同品类的网页结构不一致,这加大了抓取数据的难度。但是,每个页面都会有一些通用的信息字段,例如产品和运费。
由于文章内容有限,所以只能列出大致的操作步骤,笔者相信各位都是有爬虫经验的程序员。
分析页面HTML元素
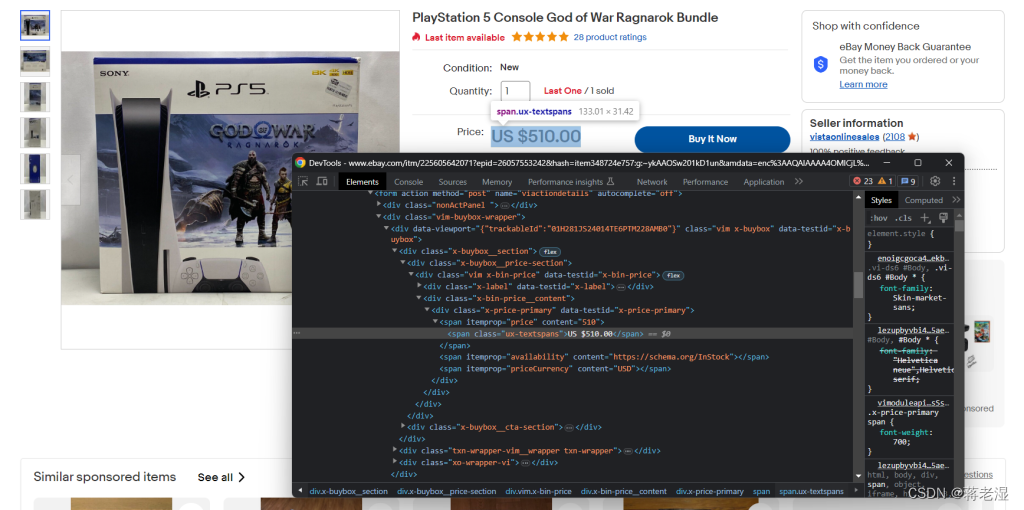
使用亮数据IP代理并解析页面数据
import requests
from bs4 import BeautifulSoup
import re
# 亮数据代理IP设置
host = 'brd.superproxy.io'
port = 22225
username = 'brd-customer-hl_d3f5c696-zone-test_isp_proxy_1'
password = 'lx4p71atz58e'
proxy_url = f'http://{username}:{password}@{host}:{port}'
proxies = {
'http': proxy_url,
'https': proxy_url
}
# 目标商品地址
url = f'https://www.ebay.com/itm/296388210331'
# 商品结果集初始化
item = {}
# 获取目标页面HTML元素
page = requests.get(url, proxies=proxies)
soup = BeautifulSoup(page.text, 'html.parser')
# css选择器解析页面数据
price_html_element = soup.select_one('.x-price-primary span[itemprop="price"]')
currency_html_element = soup.select_one('.x-price-primary span[itemprop="priceCurrency"]')
# 价格
price = price_html_element['content']
# 货币类型
currency = currency_html_element['content']
# 判断是否有其他费用
label_html_elements = soup.select('.ux-labels-values__labels')
for label_html_element in label_html_elements:
if 'Shipping:' in label_html_element.text:
shipping_price_html_element = label_html_element.next_sibling.select_one('.ux-textspans--BOLD')
# 如果有运费HTML元素
if shipping_price_html_element is not None:
# 取出运费数据:US $105.44
shipping_price = re.findall("\d+[.,]\d+", shipping_price_html_element.text)[0]
break
# 将收集到商品价格数据添加到item字典中
item['price'] = price
item['shipping_price'] = shipping_price
item['currency'] = currency
# {'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD'}
print(item)
这样我们就在Python中实现了ebay价格跟踪,不过eBay产品页面上还有很多其他有用的信息。所以,各位童鞋可以根据自己的业务需要去抓取不同的数据,如果碰到了无法访问的情况,亮数据IP代理都是可以通过的!
快捷的数据采集方式
Web Scraper IDE
随着互联网技术的日益增长,传统的程序开发需要依赖用户的电脑。但现在可以完全依托云上环境进行编码开发,用户无需安装配置任何软件开发包,不用在意自己的电脑性能,云上环境都给你解决了,只需要你的网络上下行速度不差即可。
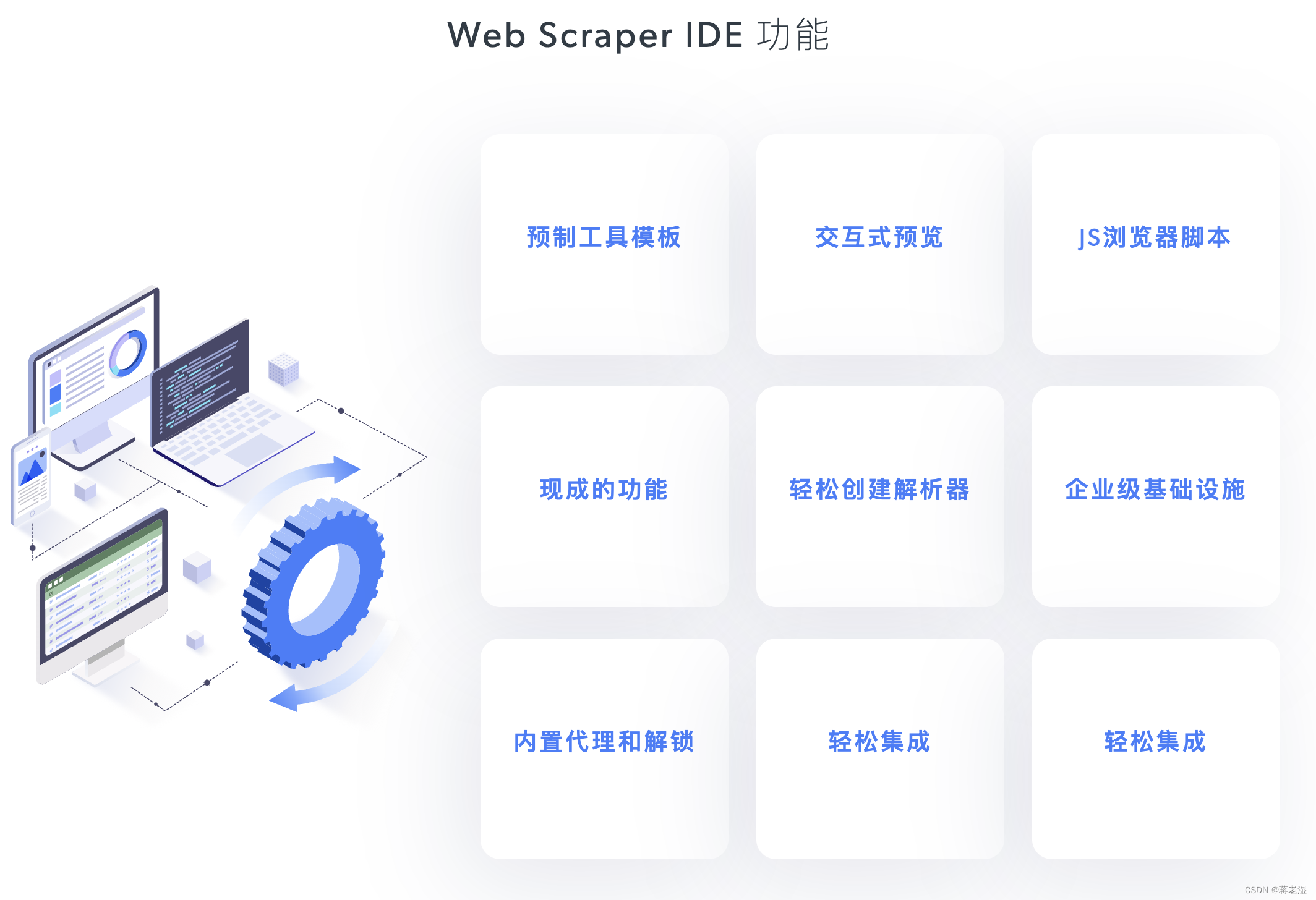
亮数据专为开发者设计的数据采集IDE,其中还内置了代理IP网络的基础组件、绕过复杂的机器人验证和验证码处理、丰富且预封装好的JavaScript函数,及大的减轻了程序员的开发与交付压力。

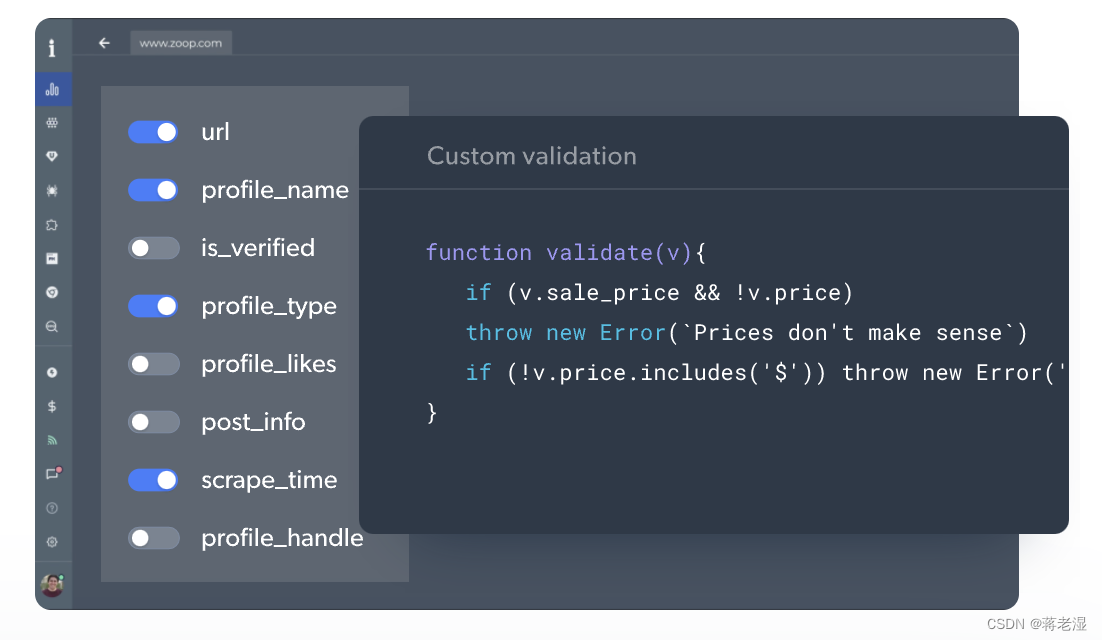
总的来说Web Scraper IDE是偏向轻快和快速试验业务可行性的开发工具
亮数据浏览器
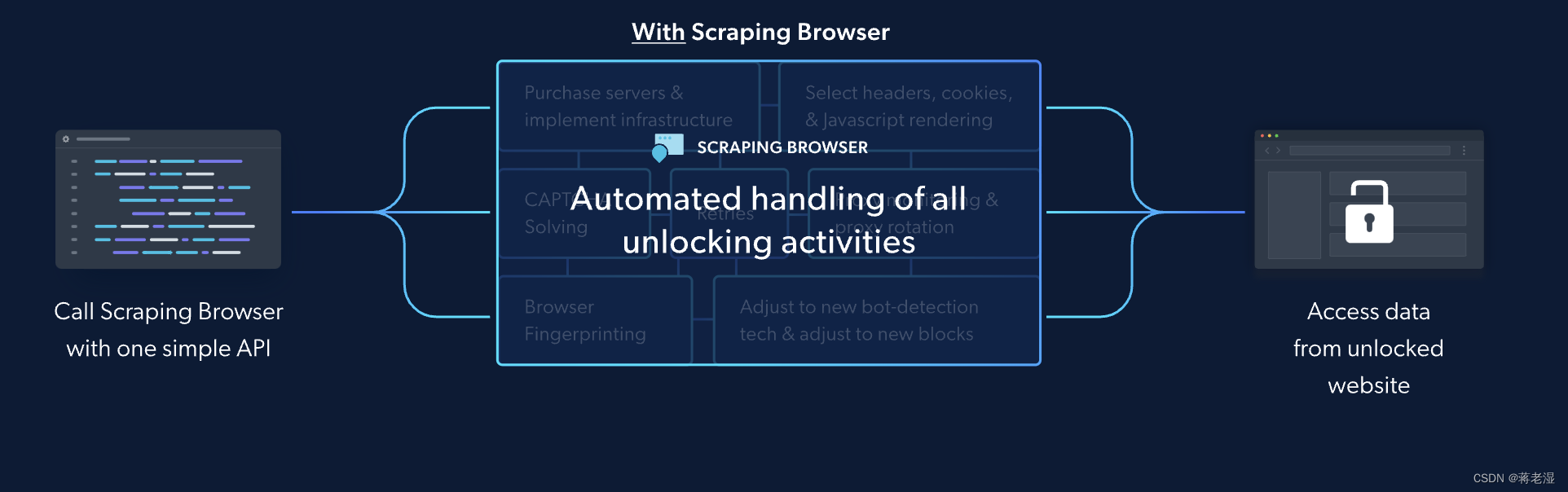
针对有些网站的数据抓取,通过纯编码的形式抓取难度大,且容易被封禁访问。为了便于该类网站的数据抓取,一般会使用Playwright 、Selenium、puppeteer这些自动化网络浏览器的框架来操作浏览器。
并且亮数据浏览器兼容Puppeteer, Playwright和Selenium,其内置代理和解锁技术,自动调整以解锁新屏蔽,解决CAPTCHA、识别指纹、自动重试等。
针对一些基础的反爬虫策略亮数据浏览器在IP代理访问层面就替你解决了,及大的节省了时间和成本。
搜索引擎采集SERP API
2024年AI大爆发,通用人工智能成了各大中小互联网公司的必争之地,而通用人工智能LLM(chatgpt)最需要的就是训练数据,openai就是从流行的搜索引擎中获取结果页面 (例如,谷歌,必应,Yandex等) 收集数据。
但随着gpt的兴起,搜索引擎各家都有各种的ip验证策略。使得程序员自己编码获取搜索引擎结果的难度变大,且需要实时维护,既不稳定又耗时耗力。
SERP相关使用场景: 关键词跟踪,品牌排名跟踪,价格比较,市场研究,版权侵权检测,广告、舆情等。
搜索引擎爬虫SERP API正好解决这这方面问题,由专门的开发团队维护各大搜索引擎的HTML结构化数据,根据所需参数量身定制结果集。通过开放平台的api接口即可实现对接,简单快捷

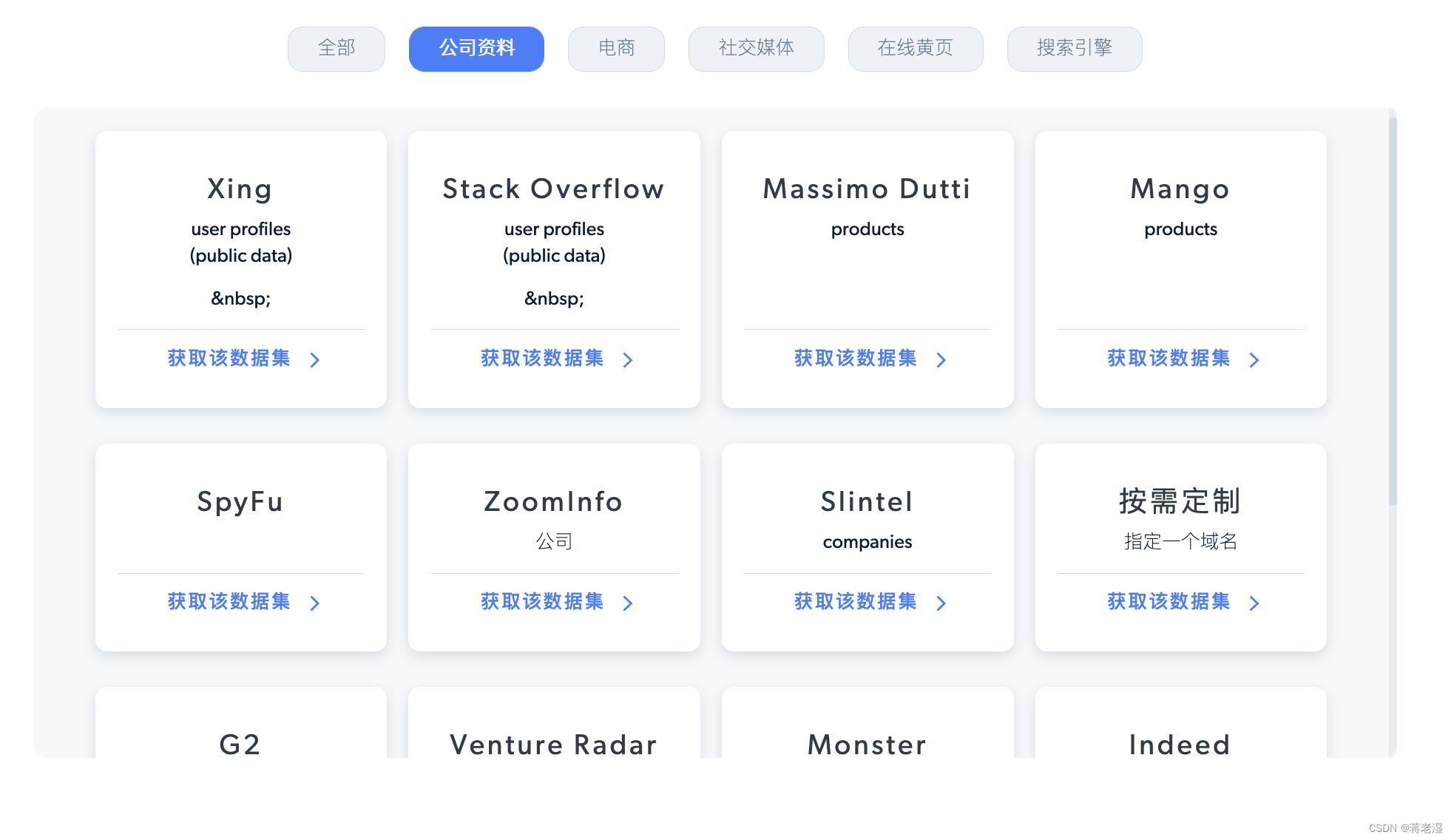
数据集
针对一些没有研发能力的公司,bright data也提供了数据采买服务,因其本身就有众多IP代理和爬虫工具,自然其本身就是一个大数据公司,可购买的数据含盖了公司资料、电商、社交媒体、在线黄页、搜索引擎等众多网站。
还可以根据个体需要自行购买或单独定制。
总结
选择商用的IP代理一是为了可靠、二是为了安全,众所周知使用了IP代理数据就会经由第三方,而Bright Data做为海外一流的数据提供商,其安全和可靠性是得到了验证的。
所以如果你或者你的公司有全球性的业务数据需求,Bright Data会是一个相对合适的选择
亮数据为粉丝提供了10美金的抵用券,成功注册账户,并登录后在用户界面里输入折扣代码即可享受抵扣!
折扣代码:jianglaoshi
访问页面:外贸电商 - Bright Data
如有问题,可以关注“Bright_Data”亮数据官微,联系后台客服。


















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











