







阿里云新建实例镜像选:modelscope:1.15.0-pytorch2.3.0tensorflow2.16.1-gpu-py310-cu121-ubuntu22.04
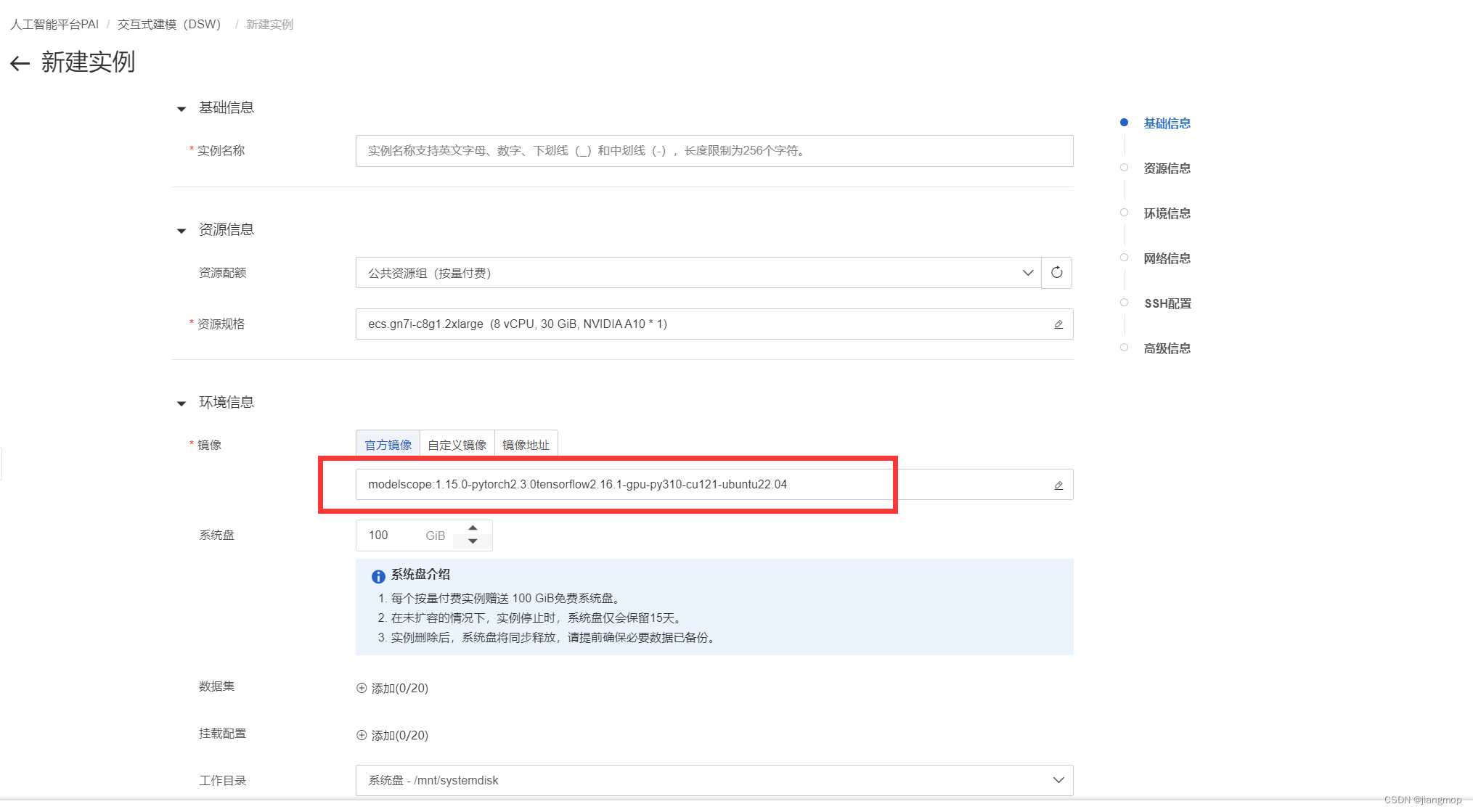
这里用 A10-24G的显卡(白嫖三个月,练练手)
1. 不是本地部署就不需要创建虚拟环境了,直接拉取项目并安装
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .2. 在 examples 文件夹中现在需要的项目,这里选择 dreambooth,安装依赖环境
cd examples/dreambooth
pip install -r requirements.txt3. accelerate 加速设置
accelerate config租的是单卡,没有分布式训练,选择混合精度训练 fp16:
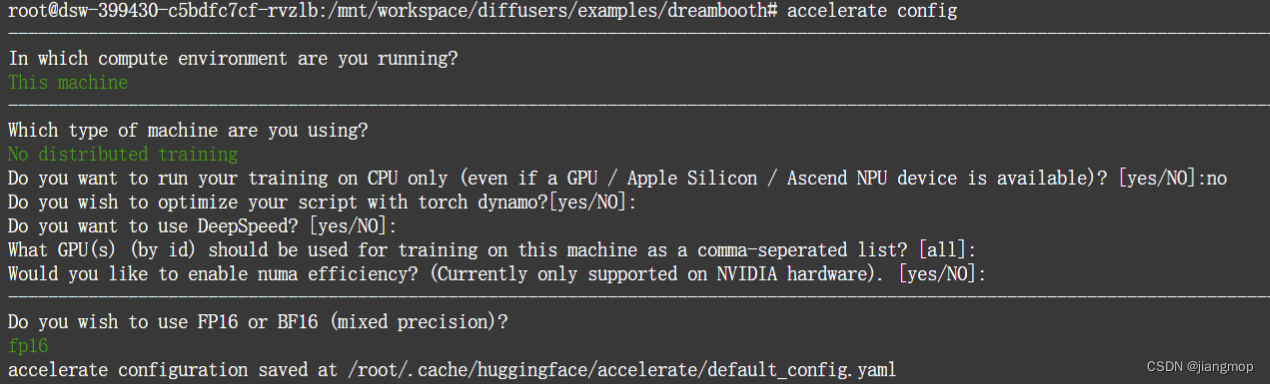
4. 以原论文中的 dog 案例学习 dreambooth 训练
4.1 上传训练照片文件
4.2 设置镜像网址、模型、训练图片、输出目录
export HF_ENDPOINT=https://hf-mirror.com
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export INSTANCE_DIR="dog"
export OUTPUT_DIR="path-to-save-model"4.3 输入命令进行训练:
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--instance_prompt="a photo of sks dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=400 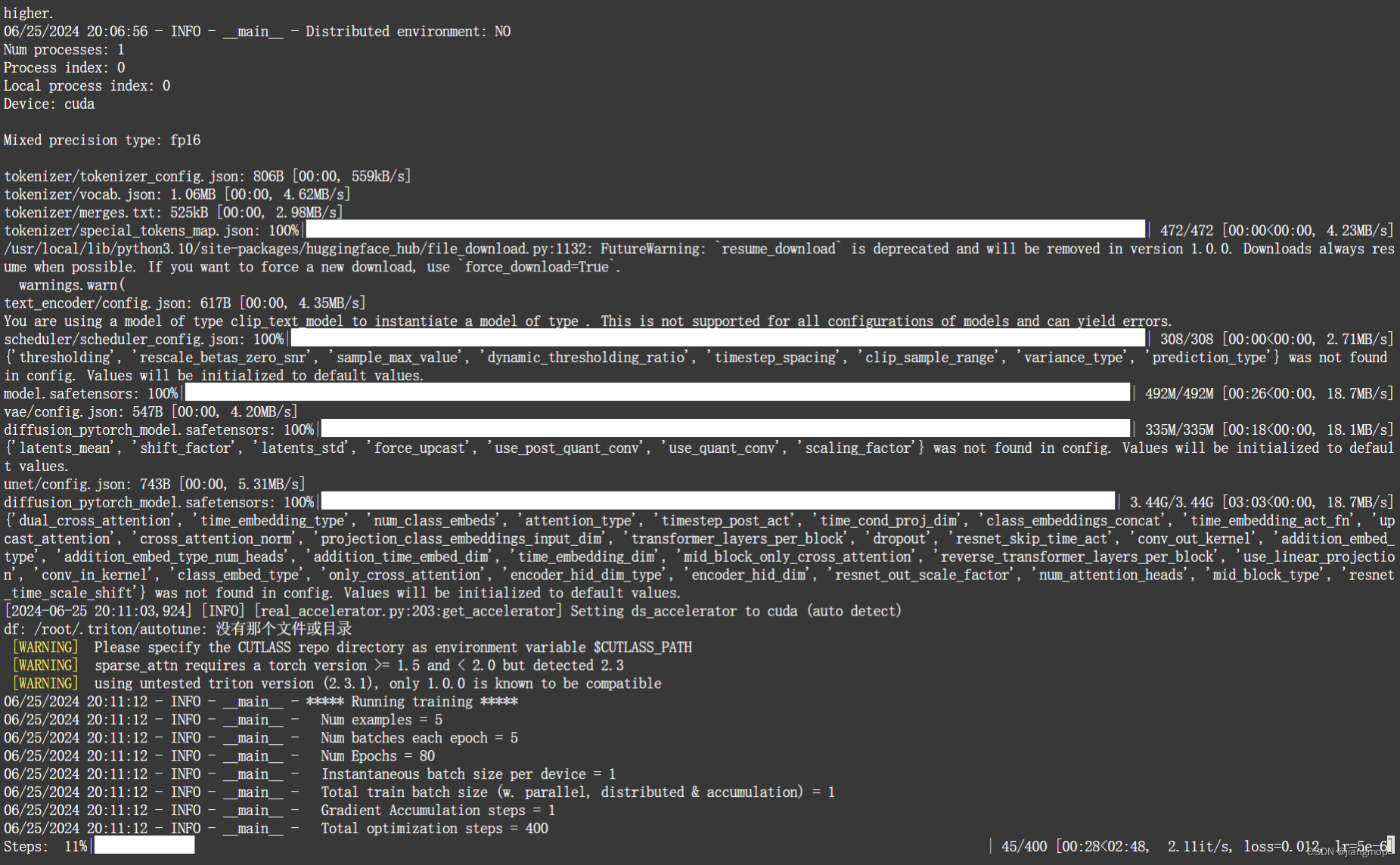
4.4 推理
新建一个 pipeline.py 文件:
from diffusers import StableDiffusionPipeline
import torch
def exp1():
model_id = "path-to-save-model"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
prompt = "A photo of sks dog in a bucket"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image.save("dog-bucket.png")
if __name__=="__main__":
exp1()终端运行:
python pipeline.py
效果:
















 1411
1411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









