







 NELL是一种模仿人类学习多样性和积累能力的模型,它不断学习和改进,通过自我监督学习新知识并避免学习瓶颈。该模型涉及多个任务,如类别分类、关系识别等,通过实时学习和反馈机制来提升其性能。实证评估显示,NELL的准确性和阅读能力随时间逐步提高,但也存在自我反思不足、可塑性受限以及推理能力有限等问题。
NELL是一种模仿人类学习多样性和积累能力的模型,它不断学习和改进,通过自我监督学习新知识并避免学习瓶颈。该模型涉及多个任务,如类别分类、关系识别等,通过实时学习和反馈机制来提升其性能。实证评估显示,NELL的准确性和阅读能力随时间逐步提高,但也存在自我反思不足、可塑性受限以及推理能力有限等问题。
文章目录
#信息抽取(Nell框架论文)
标签(空格分隔): 自然语言处理
Never-Ending Learning
Abstract
Introduction
机器学习作为AI的一个重要分支,被广泛应用于垃圾邮件过滤到语音识别、从信用卡诈骗检测到人脸识别。尽管如此、和人类学习的方式相比,电脑学习的方法依然非常狭窄。本文提出了了一种更接近人类学习的多样性、能力和积累能力的一种模型。我们叫他NELL。
上述的问题中,人们都说用一个单独的方法去解决一个单独的任务问题,经常是人们标注好的输入和输出的模型。我们这个方法不是上面提到的在短时间内在组织好的规律数据上的模型,人类学习东西也是一个依赖于丰富经验的和丰富背景知识长期工程。
这篇论文的主题是:
-
学习许多不同的模型和知识
-
多年的自我监督学习
-
用一种分阶段的形式,以前学到的知识可以用来学习更多的新的知识
-
具有自我反思和制订新特征和新学习任务的方式使得模型可以避免停滞和学习瓶颈的出现
Related Work
之前的研究考虑设计长时间持续学习系统的问题,比如:终身学习和并学习学习,然而能在实践中证明自己的系统很少。一般问题的架构已经被引用与多个领域,但是没人用可持续学习的方法。
除了对体系的研究,人们对系统的子问题也进行了研究。
Nerer-Ending-Learning
我们设计了一种永不停止的模型,像人类一样,学习很多类型的知识,已经具有自我监督的经验,然后利用学到的知识改善后续学习,并通过充分的自我反思来避免学习中的平台期。
我们的任务包括两个:
-
有一个问题集合L = {Li}, 其中每一个任务都是 Li =
<Ti,Pi,Ei> , 通过T和E来预测P -
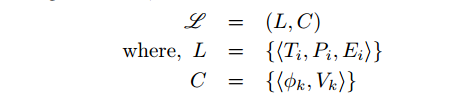
-
每个人物都有一个最好的函数f
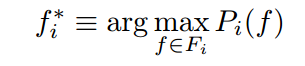
这个任务的特点
-
学习许多不同的任务
-
主要是自我学习出来的
-
顺序关系的,下一个问题
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









