







 本文介绍了使用Python爬虫分别爬取懂车帝平台上2022款科鲁泽轻混RS330T自动畅快版和2022款帝豪第4代1.5LCVT尊贵型的车主评论数据,并进行了数据清洗,提取了购车时间、地点、车价和油耗等关键信息。数据清洗后,对两款车型的油耗进行了简单分析,结果显示两者平均油耗相近,均在合理范围内。最后提到数据手动复制到Excel中进行进一步分析。
本文介绍了使用Python爬虫分别爬取懂车帝平台上2022款科鲁泽轻混RS330T自动畅快版和2022款帝豪第4代1.5LCVT尊贵型的车主评论数据,并进行了数据清洗,提取了购车时间、地点、车价和油耗等关键信息。数据清洗后,对两款车型的油耗进行了简单分析,结果显示两者平均油耗相近,均在合理范围内。最后提到数据手动复制到Excel中进行进一步分析。
一、数据爬取
(一)爬取懂车帝科鲁泽2022款轻混 RS 330T 自动畅快版汽车评论数据
1.编写数据爬取代码
爬取过程可参考代码注释,利用for循环构造翻页爬取该车型所有车主评价;由于之间爬取的数据较多,我通过if j % 2 ==1条件判断间隔获取了我想要的购车时间、购车地点、裸车价格和油耗等部分数据;然后通过with自开合讲数据存储到car_count.txt中。
#导入必要爬取包
import requests
from bs4 import BeautifulSoup
'''#测试
# i=1
# a = 'https://www.dongchedi.com/auto/series/score/3094-57238-S0-x-x-x-'+str(i+1)
# print(a)
'''
#构造排序
j = 1
#构造翻页
for i in range(8):
#获取第i页面资源
html = requests.get('https://www.dongchedi.com/auto/series/score/3094-57238-S0-x-x-x-'+str(i + 1))
#解析获取的页面资源
soup = BeautifulSoup(html.text, 'lxml')
#筛选科鲁泽22款车型页面资源
data = soup.select('article.tw-grid .tw-col-span-40')
#输出第i页资源内容
for d in data:
#输出所有数据
#print(d)
#构造for循环输出想要的部分内容
if j % 2 ==1:
print(f'第{int((j+1)/2)}位车主评价内容为:' + d.text + '\n')
with open('car_count.txt', 'a', encoding='utf8') as f:
f.write(f'第{int((j+1) / 2)}位车评:' + d.text + '\n')
else:pass
j += 1
2.爬取结果展示

(二)爬取懂车帝2022款帝豪 第4代 1.5L CVT尊贵型汽车评论数据
1.编写数据爬取代码
#导入必要爬取包
import requests
from bs4 import BeautifulSoup
'''#测试
# i=1
# a = 'https://www.dongchedi.com/auto/series/score/3094-57238-S0-x-x-x-'+str(i+1)
# print(a)
'''
#构造排序
j = 1
#构造翻页
for i in range(9):
#获取第i页面资源
html = requests.get('https://www.dongchedi.com/auto/series/score/733-54189-x-x-x-x-'+str(i + 1))
#解析获取的页面资源
soup = BeautifulSoup(html.text, 'lxml')
#筛选 2022款帝豪 第4代 1.5L CVT尊贵车型页面资源
data = soup.select('article.tw-grid .tw-col-span-40')
#输出第i页资源内容
for d in data:
#构造for循环输出想要的部分内容
if j % 2 ==1:
print(f'第{int((j+1)/2)}位车主评价内容为:' + d.text + '\n')
with open('jl_car_count.txt', 'a', encoding='utf8') as f:
f.write(f'第{int((j+1) / 2)}位车评:' + d.text + '\n')
else:pass
j += 12.爬取结果展示

二、数据清理
此处将以简单清洗科鲁泽车评数据为例,通过正则惰性匹配(.*?)表达式对爬取的数据进行解析清洗,仅提取了自个想要的数据内容:
1.数据清洗代码
'''
利用正则表达式获取爬取的科鲁泽车辆车评数据
'''
#导入正则包
import re
import csv
#读取本地txt文件,文件路径注意改为单斜杠/ 或 双反斜杠\\
with open('D:/pythonb/venv/python/car_count.txt','r', encoding='utf8') as f:
data = f.read()
# print(data)
#构造惰性匹配规则
#1.获取购车时间、地点、车价和油耗
re_com = re.compile("购买车型(.*?)油耗", re.S | re.I)
#解析内容
result = re_com.findall(data)
#输出结果
for d in result:
print(d)#输出筛选的所有结果
print(f'车辆款式:' + d[:21])
print(f'提车时间:' + d[21:28])
print(f'油耗:' + d[-5:-1])
#将提车时间存储到csv中
# with open('car.csv', 'a', encoding='utf8') as f:
# csv_d = csv.writer(f, delimiter=' ')
# csv_d.writerow(d[21:28])
#再次构造惰性匹配获取提车地点
re_location = re.compile("提车时间(.*?)购买地点")
loc = re_location.findall(d)
for l in loc:
print(f'购车地点:' + l)
#构造惰性匹配获取裸车价格
re_rice = re.compile("购买地点(.*?)裸车")
rice = re_rice.findall(d)
for r in rice:
print(f'裸车单价:' + r)
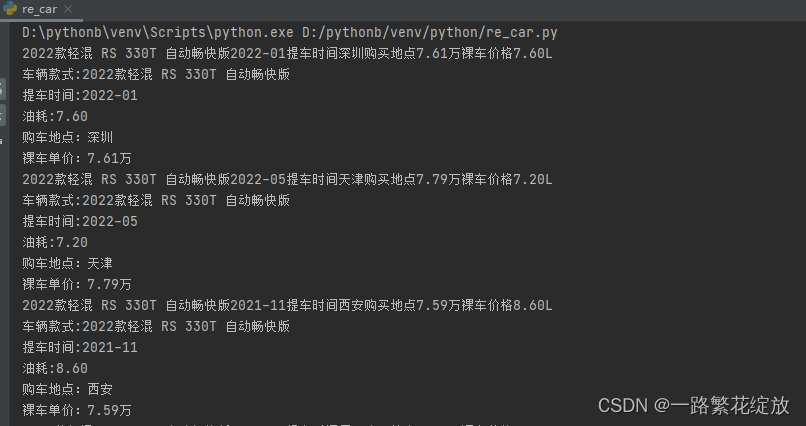
2.数据结果展示
可单独输出或保存自个想要的数据,然后根据这些数据去进行分析。
3.将数据手动复制到Excel中
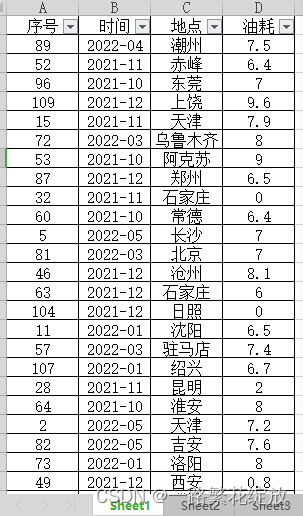
由于技术有限,目前采购手动拷贝数据存储到Excel表格的方式保存数据,然后在Excel里做简单分析。
三、简单数据分析
抛开车主驾驶习惯及行驶路段路况等一切外因,若车主在懂车帝完成上发布的数据准确,那么对2021年至2022年上半年2款车型现有车主车评数据进行简单分析。在去除小于5L和大于10L的数据后,吉利帝豪的车主平均油耗为7.8L,雪佛兰科鲁泽的车主平均油耗为7.4L,2款车型平均耗油量差距不大,且耗油相对适中。

















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









