







目录
1.1 使用selenium防爬虫方法爬取懂车帝数据.. 2
1 实验目的
爬取懂车帝上近一年销售量前109的所有车型车辆,再爬取近一年销售量前109的“新能源”车辆(用于判断所有车辆中哪些是新能源),爬取到数据后需要处理数据,将数据分解与形式转换与处理缺失值。随后将数据存入本地文件与数据库。最后将数据一多种形式可视化,并分析。
1.1 使用selenium防爬虫方法爬取懂车帝数据
由于懂车帝页面数据是通过下滑页面动态生成的,通过JavaScript动态加载数据,这是常见的放爬虫技术,因此使用传统的“requests”方法只能爬取当前页面展示的一点数据,不能展示所有的数据,因此直接爬取页面html无法得到动态加载的数据。
需要模拟浏览器运行的库来应对,这里使用“Selenium”库,该库能够模拟真人访问页面,设置“下滑”操作加载数据,并且能够直接获取当前页面内容的代码。
1.2 数据预处理
爬取了数据之后需要进行一定的预处理操作,例如:爬取的既有品牌又有车型的数据,例如“特斯拉/紧凑型SUV”,需要转化为两个数据;价格区间数据需要分成最大价格和最低价格,例如“10.58-20.68万”需要转换为两个数据并且转换为“float”类型;车辆销量数据需要去掉中间的逗号且转换为int形式,例如“425,726”需要转换为int型的4257226。另外还需要将数据中的缺失值进行处理,例如有些车没有车型仅有品牌数据“上汽通用别克”,则需要进行处理。且爬取到的数据并没有排名,因此需要按照爬取顺序添加排名。
1.3 爬虫数据保存到数据库与本地
将爬取的数据上传到数据库与本地。
1.4 可视化分析
将数据可视化,并分析。例如:绘制不同品牌车的销量,分析出进一年什么品牌销售量最高,从而得出什么品牌在我国最受欢迎;绘制不同车型的销量数据,分析出什么车型销量最高,从而得出目前什么车型受大众欢迎;绘制出各个车辆的销量,并且用不同颜色表明是否是新能源车,并在图中标上最高价格和最低价格,分析销量、是否是新能源车、价格区间之间的关系,从而得出目前新能源的市场份额以及什么新能源车辆目前最受欢迎,以及销量与价格之间的关系。
2.操作平台
(1)操作系统:windows11;
(2)MySQL版本:8.0;
(3)python版本:3.8。
3.实验步骤
3.1 数据爬虫
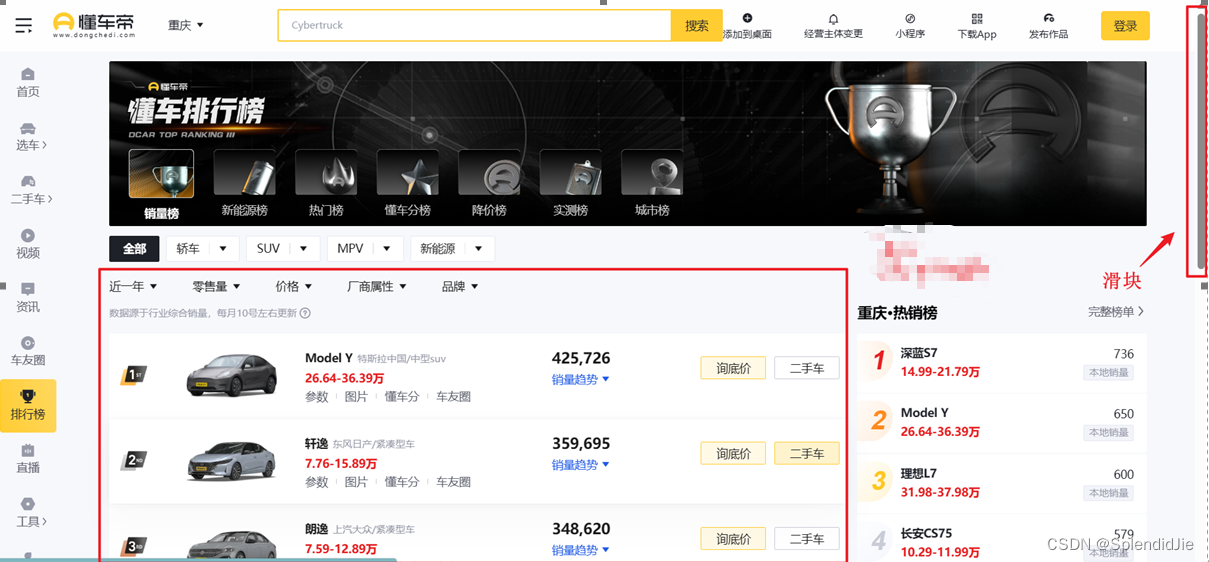
下图是懂车帝上近一年所有车型销量排行榜,可以看到这个界面是滑块控制向下滑动的,滑动之后会动态加载数据,因此直接爬取这个网址只能获得当前展示的数据。
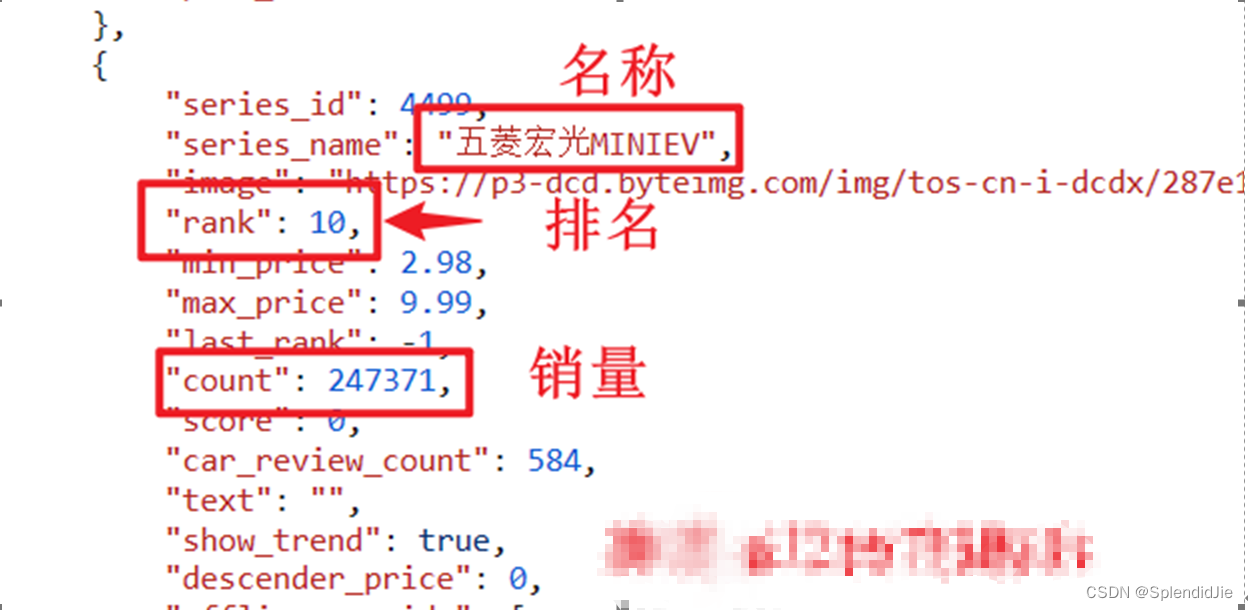
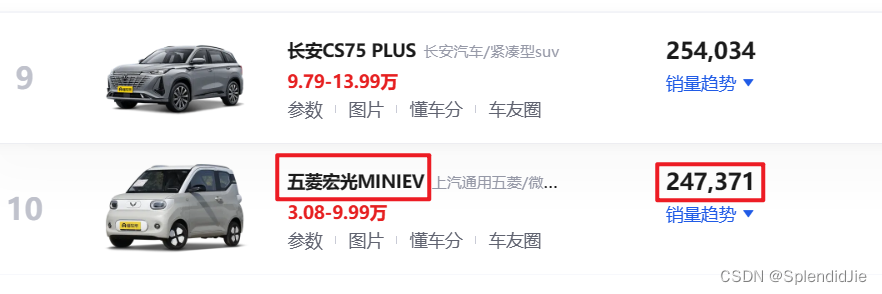
我们查看“开发者工具”的源码如下,发现网页源码只展示到了第10位的“五菱宏光MINIEV”车辆,后续的数据并没有展示。如果先手动滑动,让数据加载后再打开开发者工具查看源码,还是不会加载出数据来。
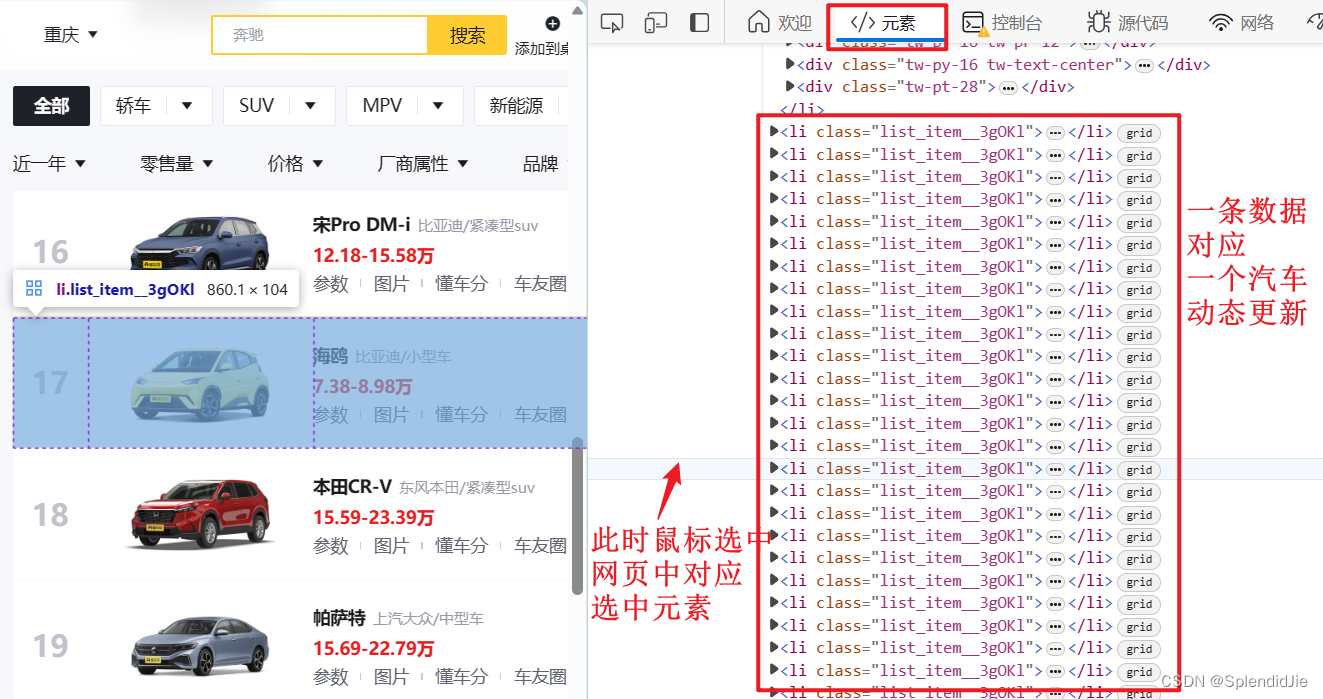
此时就得出动态更新的数据是通过XHR请求,以JavaScript的形式发送的。打开开发者工具中的“元素”查看,发现了动态加载的数据,因此以传统的“requests”方法爬虫只能爬到网页源码中展示的10辆车数据,动态加载的数据并不能爬取到,动态加载数据如下图:
3.1.1 浏览器驱动器下载与配置
针对这个防爬虫技术,就需要使用到“selenium”这个工具包模拟真人浏览界面并且获取当前展示网页的元素。实现模拟真人浏览则需要下载浏览器对应版本的驱动,本人使用的是Edge浏览器,下载地址为“Microsoft Edge WebDriver |Microsoft Edge 开发人员”,需要找到对应的版本驱动,下载解压后需要将可执行文件放在python路径的Scripts文件夹下:
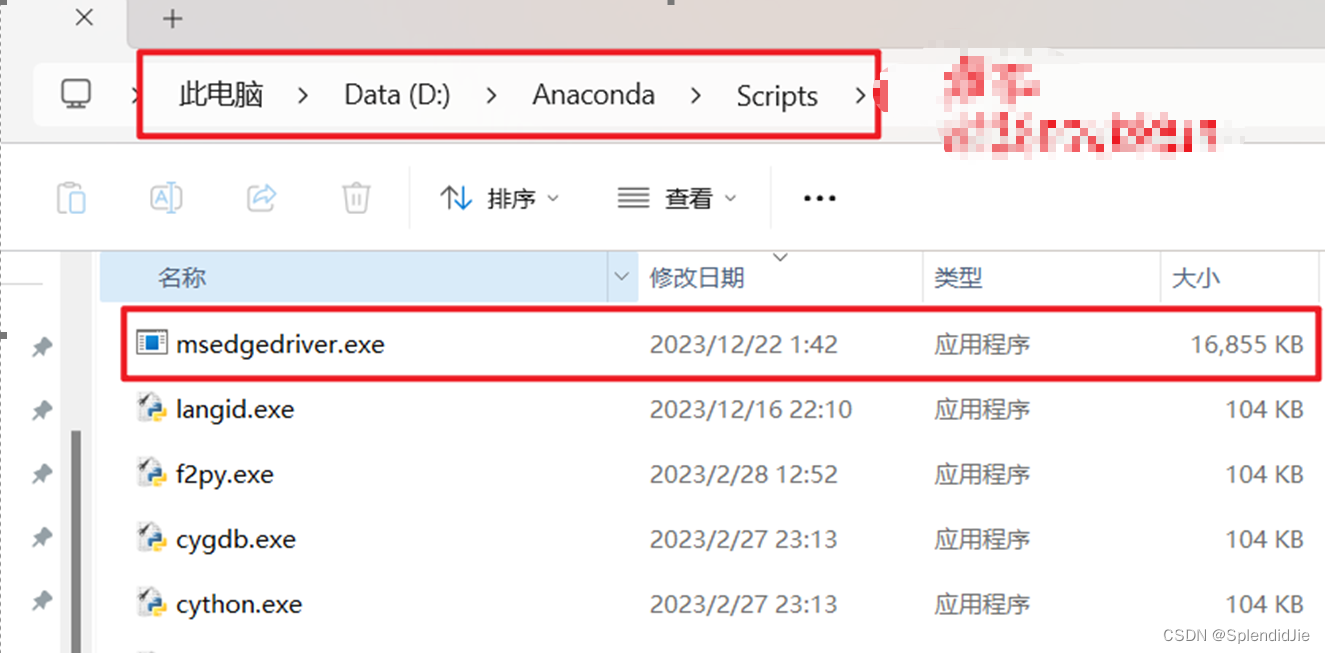
配置好驱动之后先用百度网页测试一下,编辑以下代码:
from selenium import webdriver
browser = webdriver.Edge()
data = browser.get('http://www.baidu.com') #请求页面,会打开一个窗口
text = browser.page_source #获取当前呈现页面的源码
browser.quit() #关闭浏览器
print(text) #输出 |
运行以上代码会自动弹出以下界面:
最终输出的网页代码如下,测试无误:
3.1.2 懂车帝车辆销量排行爬取
基本方法确定了,开始对懂车帝近一年所有车型销量排行榜数据进行爬取。但是有一个问题,上面对百度爬取是通过“page_source”方法获取网页代码,但是我们需要的不是整个代码,而是代码中的车辆排名信息,因此不能用这个方法,而需要用“find_elements”方法查找元素,在这之前先获取源码在word中打开,查看源码结构:

上图是排名第一的特斯拉“model Y”车辆,划红线的是我们需要爬取的数据,分别为“车辆名称”、“品牌/车型”、“价格区间”、“近一年销量”,这写元素分布在不同的类中,我们则需要通过这些类来获取元素,因此需要用到的方法为“find_elements(By.CSS_SELECTOR, value)”,即通过CCS选择器查找,“values”是查找的依据,上图可以看出分别为:
'车辆名称': 'a.tw-font-semibold'、
'品牌/车型': 'span.tw-text-color-gray-700.tw-ml-6',、
'近一年销量': 'p.tw-text-18.tw-font-semibold.tw-leading-28',、
'价格区间': 'p.tw-leading-22.tw-text-color-red-500.tw-font-semibold'
因此编写一个爬虫类如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
"""
由于懂车帝页面是JavaScript动态加载的,因此直接爬取页面html无法得到动态加载的数据
因此需要模拟浏览器运行的库来应对,这里使用Selenium库
"""
class Parsing:
def __init__(self, url):
# 设置WebDriver路径(以Edge为例)
self.browser = webdriver.Edge()
self.url = url
def parsing(self, **kwargs):
self.browser.get(self.url)
for i in range(10): # 页面滑动次数
self.browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # 滑动等待时间
for key, value in kwargs.items():
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









