







【Kaggle竞赛树叶分类1】https://www.kaggle.com/c/classify-leaves
任务是预测叶子图像的类别。该数据集包含 176 个类别、18353 张训练图像、8800 张测试图像。每个类别至少有 50 张图像用于训练。测试集平均分为公共和私人排行榜。本次比赛的评估指标是分类准确度。本章的内容是介绍Baseline。下一章将介绍提升分类准确度的tricks和模型
环境:将使用google colab pro作为代码运行和云服务器平台。
#先分配GPU
!nvidia-smi
from google.colab import drive
drive.mount('/content/drive/')
首先,将数据导入colab云端硬盘中,其中有一个images文件夹,一个train表格,test表格,和1个上交预测结果的表格。
可以看到Images文件夹中有很多形状不同的叶子。
1.Baseline(简单的resnet)
感谢Neko Kiku提供的Baseline,来自https://www.kaggle.com/nekokiku/simple-resnet-baseline
首先导入需要的包
# 首先导入包
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
import matplotlib.pyplot as plt
import torchvision.models as models
# This is for the progress bar.
from tqdm import tqdm
import seaborn as sns
使用pd.read_csv将训练集表格读入,然后看看label文件长啥样,image栏是图片的名称,label是图片的分类标签。
labels_dataframe = pd.read_csv('/content/drive/MyDrive/classify-leaves/train.csv')
labels_dataframe.head(5)

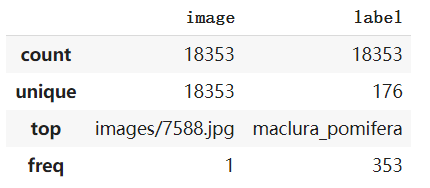
使用pd.describe()函数生成描述性统计数据,统计数据集的集中趋势,分散和行列的分布情况,不包括 NaN值。可以看到训练集总共有18353张图片,标签有176类。
labels_dataframe.describe()
用条形图可视化176类图片的分布(数目)。
#function to show bar length
def barw(ax):
for p in ax.patches:
val = p.get_width() #height of the bar
x = p.get_x()+ p.get_width() # x- position
y = p.get_y() + p.get_height()/2 #y-position
ax.annotate(round(val,2),(x,y))
#finding top leaves
plt.figure(figsize = (15,30))
#类别特征的频数条形图(x轴是count数,y轴是类别。)
ax0 =sns.countplot(y=labels_dataframe['label'],order=labels_dataframe['label'].value_counts().index)
barw(ax0)
plt.show()

把label标签按字母排个序,这里仅显示前10个。
#把label文件排个序
leaves_labels = sorted(list(set(labels_dataframe['label'])))
n_classes = len(leaves_labels)
print(n_classes)
leaves_labels[:10]
176
[‘abies_concolor’,
‘abies_nordmanniana’,
‘acer_campestre’,
‘acer_ginnala’,
‘acer_griseum’,
‘acer_negundo’,
‘acer_palmatum’,
‘acer_pensylvanicum’,
‘acer_platanoides’,
‘acer_pseudoplatanus’]
把label和176类zip一下再字典,把label转成对应的数字。
把label转成对应的数字
class_to_num = dict(zip(leaves_labels, range(n_classes)))
class_to_num
{‘abies_concolor’: 0,
‘abies_nordmanniana’: 1,
‘acer_campestre’: 2,
‘acer_ginnala’: 3,
‘acer_griseum’: 4,
‘acer_negundo’: 5,
‘acer_palmatum’: 6,
‘acer_pensylvanicum’: 7,
‘acer_platanoides’: 8,
‘acer_pseudoplatanus’: 9,
‘acer_rubrum’: 10,
…
‘ulmus_pumila’: 173,
‘ulmus_rubra’: 174,
‘zelkova_serrata’: 175}
再将类别数转换回label,方便最后预测的时候使用。
# 再转换回来,方便最后预测的时候使用
num_to_class = {
v : k for k, v in class_to_num.items()}
创建树叶数据集类LeavesData(Dataset),用来批量管理训练集、验证集和测试集。
1.定义__init__初始化函数
其中,csv_path是csv文件路径,file_path是图像文件所在路径,valid_ratio是验证集比例为0.2,resize_height和resize_width是调整后的照片尺寸256×256,mode参数最重要,这里决定是“训练数据集”还是“验证数据集”还是“测试数据集”:(train/val/test_dataset = LeavesData(train_path, img_path, mode='train/valid/test')。
用pandas读取csv文件,self.data_info = pd.read_csv(csv_path, header=None) 去掉表头部分。(注意test的cvs路径是不一样的)
然后计算数据集的长度,例如读取data的长度乘上(1-0.2)就是训练集数据的长度self.train_len。
当mode==“train”:
使用np.asarray(self.data_info.iloc[1:self.train_len, 0])读取第1列(图片名称列),从第2行开始读到self.train_len是训练集的图像名称。
使用np.asarray(self.data_info.iloc[1:self.train_len, 1])读取第2列(图片标签列),从第2行开始读到self.train_len是训练集的图像标签。
当mode==“valid”:
使用np.asarray(self.data_info.iloc[self.train_len:, 0])读取第1列(图片名称列),从第self.train_len行开始读完是验证集的图像名称。
使用np.asarray(self.data_info.iloc[self.train_len:, 1])读取第2列(图片标签列),从第self.train_len行开始读完是验证集的图像标签。
当mode==“test”:
test的cvs路径不同,有一个另外的test.csv,使用np.asarray(self.data_info.iloc[1:, 0])读取测试集图像名称列的所有名称。
2.定义__getitem__函数, 示例对象p可以通过p[key]取值,这里返回每一个index对应的图片数据和对应的标签。
single_image_name = self.image_arr[index]从image_arr中得到index对应的文件名,然后使用img_as_img = Image.open(self.file_path + single_image_name)读取图像文件。
对训练集的图片,定义一系列的transform。包括resize到224×224,0.5的概率随机水平翻转,ToTensor等。(这个Baseline其实只做了随机水平翻转的图像增强,没有其他操作,有改进余地)
对验证集和测试集的图片,transform里不做数据增强,仅resize后ToTensor。
保存transform后的图像img_as_img = transform(img_as_img)
对于训练集和验证集,通过label = self.label_arr[index]返回图像的string label和 number_label = class_to_num[label]返回number label。而测试集,直接返回img_as_img。
# 继承pytorch的dataset,创建自己的
class LeavesData(Dataset):
def __init__(self, csv_path, file_path, mode='train', valid_ratio=0.2, resize_height=256, resize_width=256):
"""
Args:
csv_path (string): csv 文件路径
img_path (string): 图像文件所在路径
mode (string): 训练模式还是测试模式
valid_ratio (float): 验证集比例
"""
# 需要调整后的照片尺寸,我这里每张图片的大小尺寸不一致#
self.resize_height = resize_height
self.resize_width = resize_width
self.file_path = file_path
self.mode = mode
# 读取 csv 文件
# 利用pandas读取csv文件
self.data_info = pd.read_csv(csv_path, header=None) #header=None是去掉表头部分
# 计算 length
self.data_len =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2183
2183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









