







 本文介绍了在Ubuntu环境下,使用Maven和Eclipse创建Hadoop项目,并解决配置过程中遇到的问题,包括Maven工程创建、WordCount程序编写、Jps无Namenode问题、文件上传及权限问题,最终成功运行WordCount示例。
本文介绍了在Ubuntu环境下,使用Maven和Eclipse创建Hadoop项目,并解决配置过程中遇到的问题,包括Maven工程创建、WordCount程序编写、Jps无Namenode问题、文件上传及权限问题,最终成功运行WordCount示例。
之前一直都是在windows下的Eclipse写hadoop,这次打算在Ubuntu下写一次,采用Maven来创建和管理工程。
Maven是一种挺方便的工程管理插件吧,通过写依赖项属性便可以自动加入需要的各个依赖库文件,也让Hadoop程序能够直接在Console这里运行,不需要导出jar包到命令行中去,方便调试代码啦!
首先记录一下Maven工程的创建
Eclipse本身是内嵌了Maven,如果想使用命令行方式创建工程,强力推荐
http://www.cnblogs.com/yjmyzz/p/3495762.html写得非常详细用心哦。
我记录一下用Eclipse直接创建的过程。
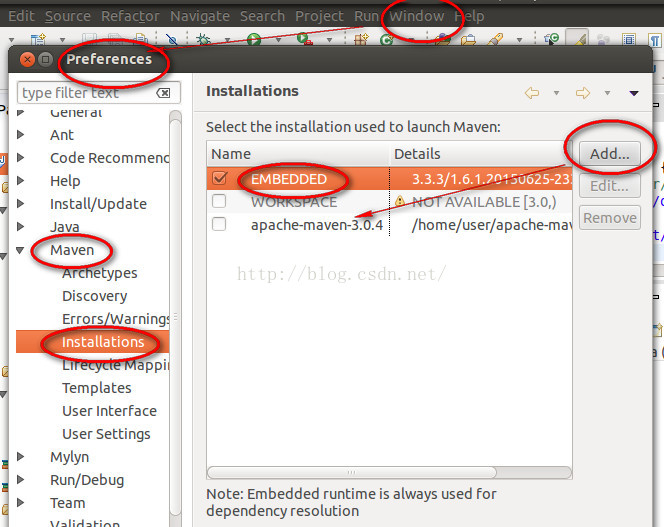
首先是Eclipse的Maven插件,如下图所示,在Windows->Preferences->maven->Installations里边。
Eclipse里边已经有一个Embedded的版本,当然也可以自己添加自己想要的maven版本,选择右边的Add添加即可。
接着便是新建一个Maven项目
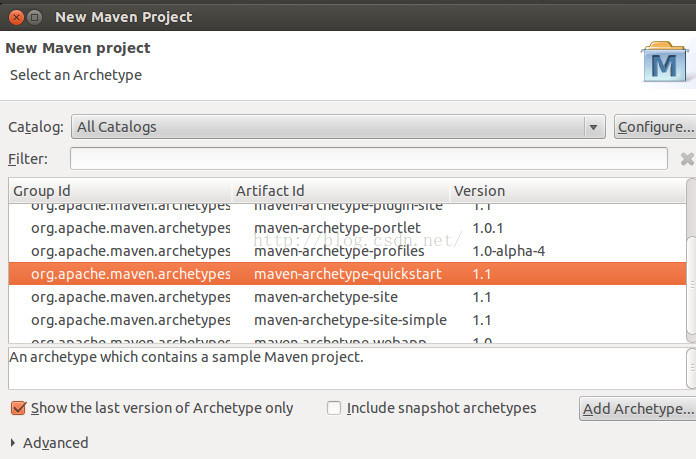
catolog我选择的是默认的quickstart
- 关于groupId,可以看做是个包吧,左右图对照便可以看到在src/main/java和src/test/java里边都出现了yjj包。
- 关于artifactId,可以看做是工程名,也会在yjj包里边生成一个同名的包。
- 版本号默认即可,packaging则定义了打包后的jar名,这里应该会生成一个jar.jar包吧,
 ,没命名好啊。
,没命名好啊。
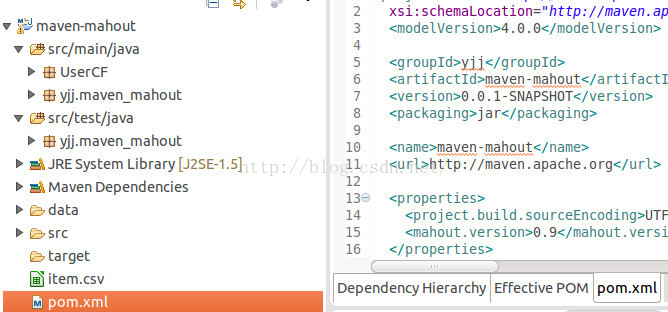
最后生成的项目结构如上图左图所示。
Maven项目有如下通用约定,
- src/main/java用于存放源代码
- src/test/java用于存放单元测试代码
- target则用于存放编译生成的class以及打包后生成的输出文件
看上图似乎多出了个src目录对吧,不需要去管它的,因为src/main/java和src/test/java其实就是在这个src里边的,我们查看下maven-mahout文件夹就可以很清楚的知道了。
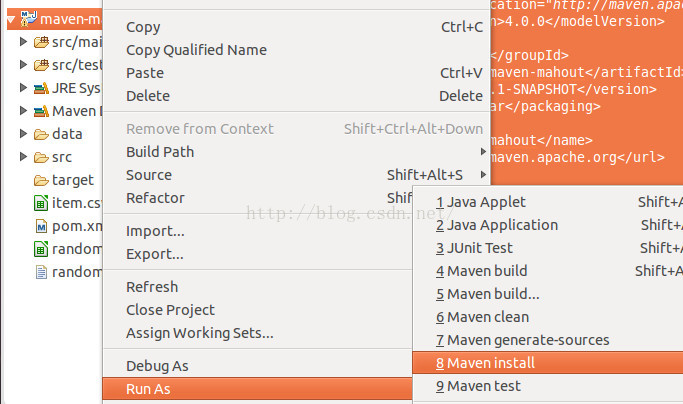
这个工程里边的main是怎样运行的呢?
如果直接右击一个含main函数的类选择run as-> java application会出现找不到这个类的情况。
那该怎么做呢?
右击项目名,然后选择
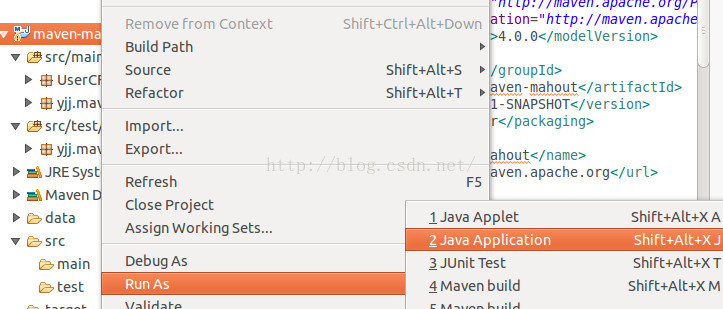
然后跳出如下界面
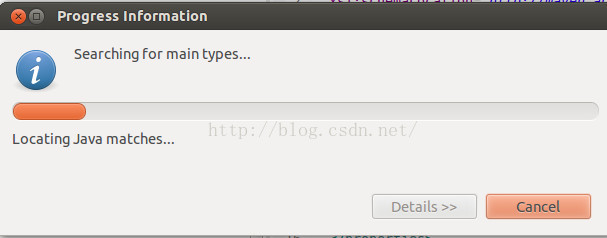
在下面选择需要运行的类,这里我选择工程自动生成的APP类。选完之后,以后再想运行这个类,便可以在Run按钮里边选择这个类来运行啦。
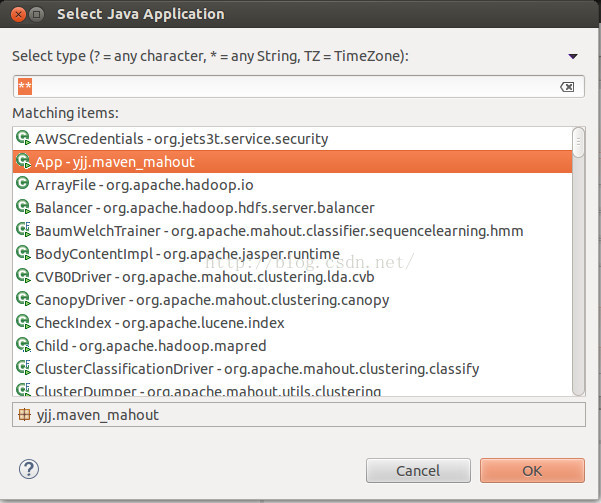
控制台成功输出啦!
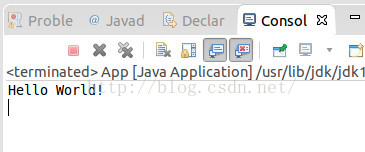
WordCount程序的编写
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>yjj</groupId>
<artifactId>maven-mahout</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>maven-mahout</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<mahout.version>0.9</mahout.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
</project>添加了hadoop-core,版本选用1.2.1版本。
Console中显示Build Success,此时刷新下项目,便可以在Maven Dependencies里边发现hadoop-core-1.2.1.jar啦!

我添加完这个之后,项目出现了个小×,好无语啊,解决办法参照http://www.cnblogs.com/yjmyzz/p/3495762.html里边说的,
我先在命令行下进入工程,然后运行mvn clean compile命令,运行成功,然后按如下方式
右键点击项目->Maven->Update Project
就ok啦!

WordCount.java
package yjj.maven_mahout;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one =new IntWritable(1);
private Text word =new Text();
public void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result =new IntWritable();
public void reduce(Text key, Iterator<IntWritable>values, Context context)throws IOException, InterruptedException {
int sum = 0;
while (values.hasNext()){
sum +=values.next().get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args)throws Exception {
String inputStr = "hdfs://127.0.0.1:9000/user/root/word.txt";
String outputStr = "hdfs://127.0.0.1:9000/user/root/result";
Configuration conf = new Configuration();
Job job = new Job(conf, "JobName");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
job.setJarByClass(WordCount.class);
job.setNumReduceTasks(4);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(inputStr));
FileOutputFormat.setOutputPath(job, new Path(outputStr));
job.waitForCompletion(true);
}
}需要说明的是在main函数里边输入与输出地址的设置,以及3个hadoop配置文件。
首先启动hadoop,然后把文件上传到了hdfs里边,
挺蛋疼的,每次都要让配置文件生效source /etc/profile以后才能直接用hadoop命令。
start-all.sh打开hadoop, ,这个Connection closed是肿么回事啊?
,这个Connection closed是肿么回事啊?
居然要用ssh登陆本机呀!!
之后再启动hadoop就ok啦!
看下jps,该启动的都启动啦!可惜不是诶,NameNode去哪了啊!!!


Jps结果没有Namenode
http://bbs.csdn.net/topics/390428450有大神提到
namenode 默认在/tmp下建立临时文件,但关机后,/tmp下文档自动删除,再次启动Master造成文件不匹配,所以namenode启动失败。
在core-site.xml中指定临时文件位置,然后重新格式化,终极解决!
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/grid/hadoop1.7.0_17/hadoop_${user.name}</value>
<property>
value中的路径只要不是/tmp 就行。

修改完之后格式化下Namenode
root@ubuntu:/usr/local/hadoop-1.2.1# hadoop namenode -format
15/07/20 04:09:26 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = ubuntu/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.2.1
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1503152; compiled by 'mattf' on Mon Jul 22 15:23:09 PDT 2013
STARTUP_MSG: java = 1.8.0_40
************************************************************/
15/07/20 04:09:26 INFO util.GSet: Computing capacity for map BlocksMap
15/07/20 04:09:26 INFO util.GSet: VM type = 32-bit
15/07/20 04:09:26 INFO util.GSet: 2.0% max memory = 1013645312
15/07/20 04:09:26 INFO util.GSet: capacity = 2^22 = 4194304 entries
15/07/20 04:09:26 INFO util.GSet: recommended=4194304, actual=4194304
15/07/20 04:09:27 INFO namenode.FSNamesystem: fsOwner=root
15/07/20 04:09:27 INFO namenode.FSNamesystem: supergroup=supergroup
15/07/20 04:09:27 INFO namenode.FSNamesystem: isPermissionEnabled=false
15/07/20 04:09:27 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
15/07/20 04:09:27 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
15/07/20 04:09:27 INFO namenode.FSEditLog: dfs.namenode.edits.toleration.length = 0
15/07/20 04:09:27 INFO namenode.NameNode: Caching file names occuring more than 10 times
15/07/20 04:09:27 INFO common.Storage: Image file /usr/local/hadoop-1.2.1/hadoop_root/dfs/name/current/fsimage of size 110 bytes saved in 0 seconds.
15/07/20 04:09:28 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/usr/local/hadoop-1.2.1/hadoop_root/dfs/name/current/edits
15/07/20 04:09:28 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/usr/local/hadoop-1.2.1/hadoop_root/dfs/name/current/edits
15/07/20 04:09:28 INFO common.Storage: Storage directory /usr/local/hadoop-1.2.1/hadoop_root/dfs/name has been successfully formatted.
15/07/20 04:09:28 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at ubuntu/127.0.1.1
************************************************************/
此时再看Jps就有Namenode啦!
root@ubuntu:/usr/local/hadoop-1.2.1# jps
7027 Jps
4150 DataNode
3710 TaskTracker
3496 JobTracker
6105 NameNode
3426 SecondaryNameNode
root@ubuntu:/usr/local/hadoop-1.2.1# chmod -R 777 tmp
root@ubuntu:/usr/local/hadoop-1.2.1# rm -R tmp
然后上传文件
坑爹的是,又遇到问题了
root@ubuntu:/usr/local/hadoop-1.2.1# hadoop dfs -copyFromLocal /home/user/opencv.txt opencv-word.txt
15/07/20 04:11:04 WARN hdfs.DFSClient: DataStreamer Exception: org.apache.hadoop.ipc.RemoteException: java.io.IOException: File /user/root/opencv-word.txt could only be replicated to 0 nodes, instead of 1
15/07/20 04:11:04 WARN hdfs.DFSClient: Error Recovery for null bad datanode[0] nodes == null
查下日志看看到底又怎么了吧。
在hadoop目录下有个log目录,因为上面说了是datanode的问题,那就看看hadoop-root-datanode-ubuntu.log这个文件吧

************************************************************/
2015-07-20 02:12:59,116 INFO org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2015-07-20 02:12:59,138 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source MetricsSystem,sub=Stats registered.
2015-07-20 02:12:59,144 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2015-07-20 02:12:59,144 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: DataNode metrics system started
2015-07-20 02:12:59,463 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source ugi registered.
2015-07-20 02:12:59,644 WARN org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Source name ugi already exists!
2015-07-20 02:12:59,771 INFO org.apache.hadoop.util.NativeCodeLoader: Loaded the native-hadoop library
2015-07-20 02:13:01,683 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:9000. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
2015-07-20 02:13:02,685 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:9000. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
hadoop错误INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1
原因是:hadoop默认配置是把一些tmp文件放在/tmp目录下,重启系统后,tmp目录下的东西被清除,所以报错
解决方法:在conf/core-site.xml (0.19.2版本的为conf/hadoop-site.xml)中增加以下内容
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
<description>A base for other temporary directories</description>
</property>
 这不就是我刚刚做的嘛!!!为毛又出错诶?
这不就是我刚刚做的嘛!!!为毛又出错诶?
好吧,再一次重启,格式化


还有个权限问题
org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="user":hadoop:supergroup:rwxr-xr-x
so,在master节点上修改hdfs-sit.xml
加上以下内容,取消权限功能吧 :
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
文件路径的问题
String inputStr = "hdfs://127.0.0.1:9000/user/root/word.txt";
String outputStr = "hdfs://127.0.0.1:9000/user/root/result";我是如下写的,hdfs里边的路径用的都是localhost。


然后ifconfig看看

有两个地址,一个IP地址,一个内网地址,说起来我也挺困惑的,到底该填哪个呢?
实验得知该填下面这个啦。所以
hdfs://127.0.0.1:9000/也就是hdfs的根目录。
之后将hdfs里边的文件目录加进去就好了。
实验结果
在eclipse下跑一下,Console端便会输出相应结果。
INFO: Total input paths to process : 1
Jul 20, 2015 4:44:04 AM org.apache.hadoop.io.compress.snappy.LoadSnappy <clinit>
WARNING: Snappy native library not loaded
Jul 20, 2015 4:44:05 AM org.apache.hadoop.mapred.JobClient monitorAndPrintJob
INFO: Running job: job_local1284391682_0001
Jul 20, 2015 4:44:05 AM org.apache.hadoop.mapred.LocalJobRunner$Job run
INFO: Waiting for map tasks
Jul 20, 2015 4:44:05 AM org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable run
INFO: Starting task: attempt_local1284391682_0001_m_000000_0
Jul 20, 2015 4:44:06 AM org.apache.hadoop.mapred.JobClient monitorAndPrintJob
INFO: map 0% reduce 0%
Jul 20, 2015 4:44:12 AM org.apache.hadoop.mapred.LocalJobRunner$Job run
INFO: Map task executor complete.
Jul 20, 2015 4:44:12 AM org.apache.hadoop.mapred.Task initialize
INFO: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@5289d2
Jul 20, 2015 4:44:12 AM org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
INFO:
Jul 20, 2015 4:44:12 AM org.apache.hadoop.mapred.Merger$MergeQueue merge
INFO: Merging 1 sorted segments
Jul 20, 2015 4:44:13 AM org.apache.hadoop.mapred.Merger$MergeQueue merge
INFO: Down to the last merge-pass, with 1 segments left of total size: 75936 bytes
Jul 20, 2015 4:44:13 AM org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
INFO:
Jul 20, 2015 4:44:13 AM org.apache.hadoop.mapred.JobClient monitorAndPrintJob
INFO: map 100% reduce 0%
Jul 20, 2015 4:44:16 AM org.apache.hadoop.mapred.Counters log
INFO: Reduce shuffle bytes=0
Jul 20, 2015 4:44:16 AM org.apache.hadoop.mapred.Counters log
INFO: Physical memory (bytes) snapshot=0
Jul 20, 2015 4:44:16 AM org.apache.hadoop.mapred.Counters log
INFO: Reduce input groups=2522
Jul 20, 2015 4:44:16 AM org.apache.hadoop.mapred.Counters log
INFO: Combine output records=0
Jul 20, 2015 4:44:16 AM org.apache.hadoop.mapred.Counters log
INFO: Reduce output records=5987
Jul 20, 2015 4:44:16 AM org.apache.hadoop.mapred.Counters log
INFO: Map output records=5987
Jul 20, 2015 4:44:16 AM org.apache.hadoop.mapred.Counters log
INFO: Combine input records=0
Jul 20, 2015 4:44:16 AM org.apache.hadoop.mapred.Counters log
INFO: CPU time spent (ms)=0
Jul 20, 2015 4:44:16 AM org.apache.hadoop.mapred.Counters log
INFO: Total committed heap usage (bytes)=321527808
我们到hdfs里边看看结果如何

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









