







这三种方法都是监督学习中的参数估计方法,假定已知data的分布形式(比如第二章里介绍的各种分布),但是需要确定参数。
1 最大似然估计Maximize Likelihood Estimation等价于曲线拟合中的最小二乘法,MLE把待估的参数看作是确定性的量,只是其取值未知,缺点:容易导致过拟合。
最大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。MLE一个非常重要的假设,就是所有采样必须是i.i.d。
第一步模型选择,即确定参数的分布,例如Gaussian distribution;
第二步计算参数的似然函数,一般会取对数运算;
第三步解似然方程。
2 最大后验估计Maximize A Posterior Estimation等价于曲线拟合中的正则化的最小二乘法,也是假设model的参数是确定量,但是值未定,比MLE多了一项先验概率。由于引入了先验概率,可以抑制过拟合现象。
3 Bayesian估计(预测分布Predictive Distribution)与前面二者不同,预测分布把待估的参数看做是与先验概率有类似形式的(contingent prior)随机变量,是不确定值。对样本进行观察的过程,实际就是计算先验概率和似然函数,计算得到posterior probability,再进行积分。
Bayesian估计不再估计参数,而是估计参数的后验分布p(w|D);
不再构建回归函数,而是构造一个回归模型的分布密度p(t|x,w);
决策阶段利用后验分布函数去加权回归模型的预测性分布
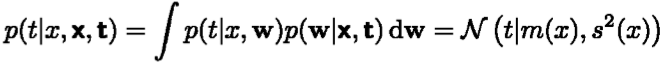
把待估计的参数看成是符合某种先验概率分布的随机变量;对样本进行观测的过程,就是把先验概率密度转化为后验概率密度,这样就利用样本的信息修正了对参数的初始估计值。典型的效果是:每得到新的观测样本,都使得后验概率密度函数变得更加尖锐,使其在待估参数的真实值附近形成最大的尖峰,这个现象就称为“贝叶斯学习”过程。















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









