









一、一致性哈希算法
一致性Hash算法通过一个叫做一致性Hash环的数据结构实现Key到缓存服务器的Hash映射,如图6.11所示:
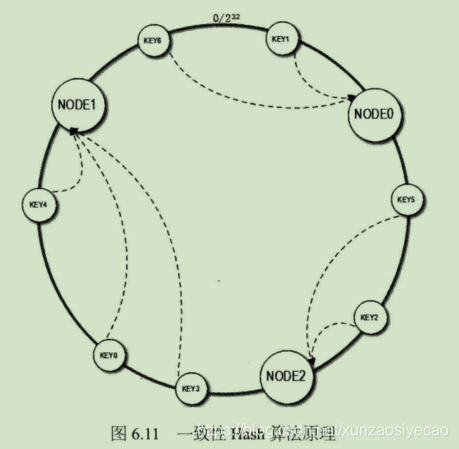
算法过程如下:
先构造一个长度为2^32的整数环(这个环被称为一致性Hash环),根据节点名称的Hash值(其分布为[0, 2^32-1])将缓存服务器节点放置在这个Hash环上,然后根据需要缓存的数据的Key值计算得到其Hash值(其分布也为[0, 2^32-1]),然后在Hash环上顺时针查找距离这个Key值的Hash值最近的服务器节点,完成Key到服务器的映射查找。
假设NODE1的Hash值为3,594.963,423, N0DE2的Hash值为1,845,328,979,而KEY0的Hash值为2,534,256.785,那么KEY0在环上.顺时计查找,找到的最近的节点就是NODE1。
当缓存服务器集群要扩容的时候,只需要将新加入的节点名称(NODE3 )的Hash 值放入一致性Hash环中,由于KEY是顺时针查找距离其最近的节点.因此新加入的节点只影响整个环中的一小段.如图6.12中深色一段
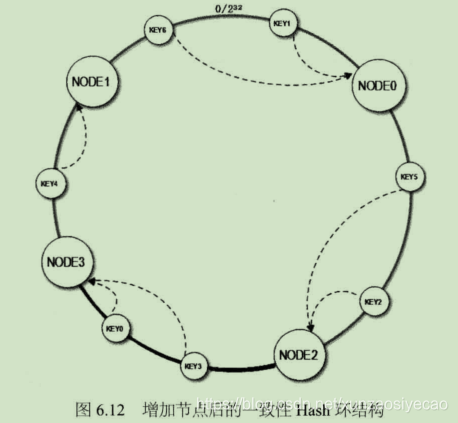
假设 N0DE3 的 Hash是2,790,324,235,那么加入 N0DE3 后,KEYO(Hash 值 2,534.256,785)顺时针查找得到的节点就是NODE3。
图6.12中,加入新节点N0DE3后,原来的KEY大部分还能继续计算到原来的节点.只冇KEY3、KEY0从原来的NODE1重新计算到N0DE3。这样就能保证大部分被缓存的数据还可以继续命中。3台服务器扩容至4台服务器.可以继续命中原有缓存数据的概率是75%,远高于余数Hash的25%.而且随着集群规模越大.继续命中原有缓存数据的槪率也逐渐增大,100台服务器扩容增加1台服务器.继续命中的槪率是99%,.虽然仍有小部分数据缓存在服务器中不能被读到,但是这个比例足够小.通过访问数据库获取也不会对数据库造成致命的负载压力。
具体应用中,这个长度为232 的一致性Hash环通常使用二叉查找树实现,Hash查找过程实际上是在二叉査找树中查找不小于査找数的最小数值。当然这个二叉树的最右边叶子节点和最左边的叶子节点相连接,构成环。
从增加节点和减少节点的例子中觉察到了问题:新增一个节点时,除了新增的节点外,只有一个节点受影响,这个新增节点和受影响的节点的负载是明显比其他节点低的;减少一个节点时,除了减去的节点外,只有一个节点受影响,它要承担自己原来的和减去的节点的工作,压力明显比其他节点要高。如果4台机器的性能是一样的,么这种结果显然不是我们需要的。这似乎要增加一倍节点或减去一半节点才能保持各个节点的负载均衡。如果真是这样,一致性哈希的优势就不明显了。
二、虛拟节点对一致性哈希的改进(解决负载不均衡问题)
计算机领域有句话:计算机的任何问题都可以通过增加一个虚拟层来解决。计算机硬件、计算机网络、计算机软件都莫不如此。计算机网络的7层协议,每一层都可以看作是下一层的虚拟层;计算机操作系统可以看作是计算机硬件的虚拟层;Java虚拟机可以看作是操作系统的虚拟层;分层的计算机软件架构事实上也是利用虚拟层的概念。
解决上述一致性Hash算法带来的负载不均衡问题,也可以通过使用虚拟层的手段: 将每个节点虚拟为一组虚拟节点,将虚拟节点的Hash值放置在Hash环上,KEY在环上先找到虚拟节点,再得到物理节点的信息。
这样新加入物理节点时,是将一组虚拟节点加入环中,如果虚拟节点的数目足够多,这组虚拟节点将会影响同样多数目的已经在环上存在的虚拟节点,这些已经存在的虚拟节点又对应不同的物理节点。最终的结果是:新加入一个物理节点,将会较为均匀地影响原来集群中已经存在的所有节点,也就是说分摊原有节点在集群中所有节点的一小部分负载,其总的影响范围和上面讨论过的相同。如图6.13所示。
在图6.13中,新加入节点NODE3对应的一组虚拟节点为V30,V31,V32,加入到 —致性Hash环上后,影响V01, V12, V22三个虚拟节点,而这三个虚拟节点分别对应 NODE0 NODE1, N0DE2三个物理节点。最终集群中加入一个节点,但是同时影响到集群中已存在的三个物理节点,在理想情况下,每个物理节点受影响的数据量 为其节点缓存数据最的1/4(X/(N+X)),N为原有物理节点数,X为新加入物理节点数),也就是集群中已经被缓存的数据有75%可以被继续命中,和未使用虚拟节点的一致性Hash算法结果相同,只是解决的负载均衡的问题。
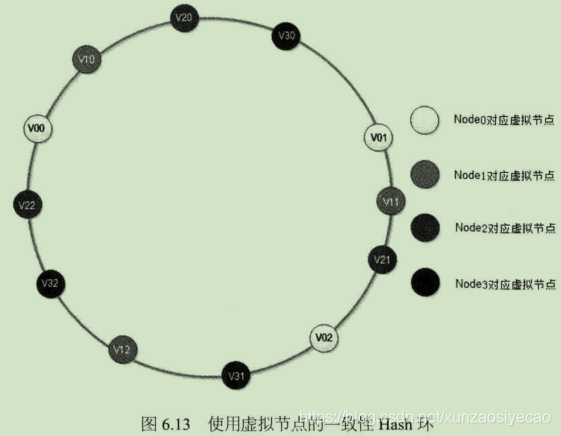
显然每个物理节点对应的虚拟节点越多,各个物理节点之间的负载越均衡,新加入物理服务器对原有的物理服务器的影响越保持一致(这就是一致性Hash这个名称的由来)。 那么在实践中,一台物理服务器虚拟为多少个虚拟服务器节点合适呢?太多会影响性能,太少又会导致负载不均衡,一般说来,经验值是150,当然根据集群规模和负载均衡的精度需求,这个值应该根据具体情况具体对待。
要解决的问题:就是增减缓存集群机器的时候,仍然尽量保持较好的缓存命中率及较均衡的机器负载。
本文整理自:《大型网站技术架构:核心原理与案例分析》
个人微信公众号:

作者:jiankunking 出处:http://blog.csdn.net/jiankunking














 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









