






上一篇文章中,我们已经介绍了,分布式缓存的集群,与应用服务器的集群策略有所不同。分布式缓存集群,每一个节点上缓存的数据各不相同。
缓存策略
常见的策略有求留余数法和一致性Hash算法。
缓存的本质是一个内存Hash表,网站应用中,数据缓存以一对Key、Value的形式存储在内存Hash表中。
计算KV对中Key的HashCode对应的Hash表索引,可快速访问Hash表中的数据。我们可以理解为:HashCode,就是该对象的唯一标识。
求留余数法
求留余数法,是最简单的一种计算策略。它的计算过程,就是使用Hash表数据长度对HashCode求余数,将余数作为索引,使用该余数,直接设置或者访问缓存。

举个例子:将所有应用服务器依次进行编号,如现在有8台缓存服务器,那么,我就用对象的HashCode,除以缓存服务器个数8,然后将相应的缓存,存入相同的缓存服务器。取得过程与存的过程完全类似。
由于HashCode具有随机性,因此使用求留余数路由算法可以保证缓存数据在整个Memcached服务器集群中比较均衡的分布。
对该方法稍加改进,就可以实现和负载均衡算法中加权负载均衡一样的加权路由算法。可以说,简单的求留余数法基本上能够满足绝大多数的路由需求。
然而,在分布式缓存集群需要扩容时,事情就变棘手了。
如果现在增加一台缓存服务器,变成9台了。之前是用缓存对象的HashCode,除以8,现在改成除以9了。很明显,之前缓存的数据,绝大多数都访问不到了,绝大多数的数据,都需要从数据库中,重新加载。
这不是我们想看到的,能不能通过改进路由算法,使得新加入的服务器不影响大部分缓存数据的正确命中呢?现在比较流行的一种方式就是一致性Hash算法。
一致性Hash算法
一致性Hash算法通过一个叫做一致性Hash环的数据结构,实现KEY到缓存服务器的Hash映射。

算法过程如下:
先构造一个0到232的整数环,然后将服务器节点的Hash值,放在该环上(可以理解为将你的ip做hash,将ip的HashCode放在环上)。然后根据需要缓存的数据的Key,计算Key的HashCode,然后在环上,顺时针查找距离这个Key的Hash值最近的缓存服务器的节点,然后将Value,存储到该服务器节点上。
这是当缓存服务器集群需要扩容的时候,只需要将新加入的节点的HashCode,放入一致性Hash环中,由于Key是顺时针查找距离最近的节点,因此,新加入的节点只影响整个环中的一小段。
请参见上图,如果我们新加入的服务器节点Node3,在Node1和Node2之间,如下图:
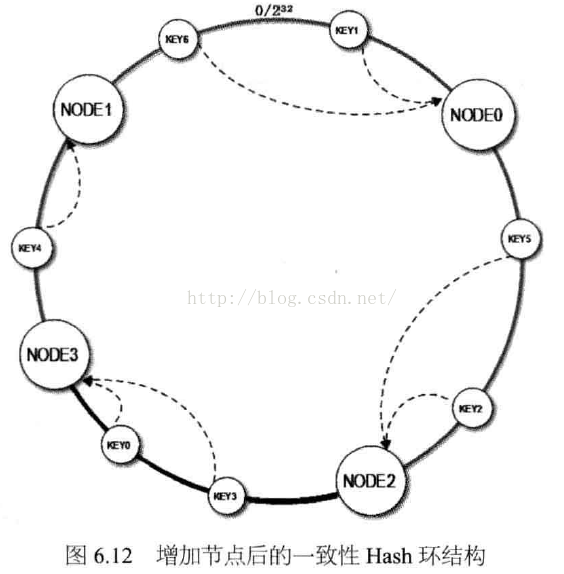
那么受影响的区域,只是Node2到Node3之间(顺时针)的缓存,此区间的缓存数据,加入节点之前是缓存在Node1上的,现在需要重新缓存到Node3上面。
具体应用中,这个长度为232的整数环,通常使用二叉查找树实现,Hash查找过程实际上是在二叉树中查找不小于查找树的最小值。当然,这个二叉树的最右边的叶子节点和最左边的叶子节点相连接,构成环。
通过上面的一致性Hash算法,就解决了分布式缓存集群中扩容的问题。然而上面的方法,仍然有问题。我们已经说过,上面的架构,只影响了Node2到Node3之间的区域(顺时针),那么Node3,也只是分摊了Node1节点的压力,而Node0和Node2的访问压力,并没有变化。也就是说:我们加入了硬件投入,却起到了很小的效果。
一致性Hash算法的进化版
所以说,我们还需要对上面的做法,进行改进。
上述问题是,一致性Hash算法带来的负载均衡不均衡。我们可以通过增加虚拟层来实现。
我们将每台缓存服务器,虚拟为一组虚拟缓存服务器,将虚拟服务器的Hash值,放置在Hash环上,Key在环上先找到虚拟服务器节点,再得到物理服务器的信息。
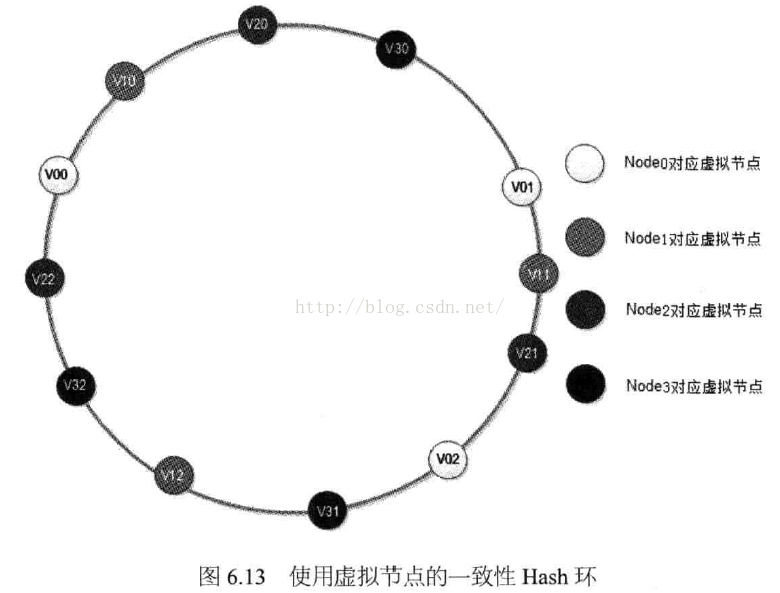
这样,一台服务器节点,被环中多个虚拟节点所代表,且多个节点均匀分配。很显然,每个物理节点对应的虚拟节点越多,各个物理节点之间的负载越均衡,新加入物理服务器对原有的物理服务器的影响越保持一致。
本文主要介绍了缓存的存取策略,最常用的、也是目前最流行的就是一致性Hash算法,以及一致性Hash算法的改进版的介绍。这些东西都偏理论,下篇文章,我们将从实现的角度,从具体角度来操作一下。















 9746
9746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









