






在发本文章之前,我也看过很多前辈们写的代码,但是总有些地方有问题,所以发一个我运行出来的一个版本,可能方法有点笨,但是能用。
jieba是python中一个重要的第三方中文分词函数库,不是安装包自带,需要通过pip指令安装。
import jieba
excludes={"什么","一个","不好","不过","老爷","奶奶","我们","那里","这里",
"知道","你们","说道","如今","出来","起来","姑娘","一面","怎么","只见",
"他们","众人","没有","不是","不知","自己","听见","这个","两个","就是",
"东西","进来","告诉","回来","咱们","丫头","大家","这些","只得","只是",
"不敢","这样","出去","这么","的话"}
txt=open("D:\\红楼梦.txt","r",encoding='utf-8').read()
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
elif word=="王夫人"or word=="太太":
word="王夫人"
counts[word]=counts.get(word,0)+1
elif word=="贾母"or word=="老太太":
word="贾母"
counts[word]=counts.get(word,0)+1
elif word=="凤姐"or word=="凤姐儿":
word="王熙凤"
counts[word]=counts.get(word,0)+1
elif word=="林黛玉"or word=="黛玉":
word="林黛玉"
counts[word]=counts.get(word,0)+1
else:
counts[word]=counts.get(word,0)+1
for word in excludes:
del(counts[word])
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
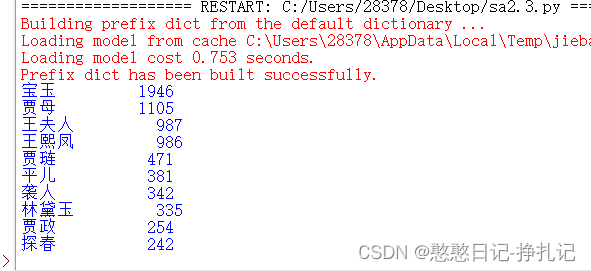
for i in range(10):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











