







所谓内存查看对象,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问。
1.缓冲区协议
buffer protocol是一种允许对象以二进制数据形式共享内存的机制。这个协议对于实现低层次的、高效的数据访问和操作非常有用,特别是在涉及大量数据处理时。支持缓冲区协议的对象可以直接进行内存操作,而不需要通过中间复制,这样可以大幅提高性能。
下面列出了一些主要的Python内置对象,它们支持缓冲区协议:
1. bytes
bytes对象是不可变的,支持缓冲区协议,允许访问其中的原始数据。
2. bytearray
与bytes类似,但是bytearray是可变的。它同样支持缓冲区协议。
3. array.array
array模块提供的array.array对象,它根据指定的数据类型存储数值数据,并支持缓冲区协议。
4. memoryview
memoryview对象本身就是基于缓冲区协议来创建的。它可以用来访问其他支持缓冲协议对象的内存,而无需复制其内容。
5. numpy.ndarray
虽然numpy不是Python的内置库,但其数组类型numpy.ndarray广泛用于科学计算中,它也支持缓冲区协议,允许其它对象访问数组的内存。
6.其他类型
其他一些特定的类型,如某些类和实例,如果实现了相应的__buffer__接口,也可以支持缓冲区协议。
这些对象都可以通过实现__buffer__接口来让其他Python代码安全、高效地访问其内部数据。在使用这些对象时,可以通过如memoryview这类工具来直接操作内存,从而避免不必要的数据复制,实现高效的数据处理。
memoryview的实现依赖于Python的buffer protocol。它允许一个对象暴露其内部数据给其他对象,而这些对象可以直接操作这些数据(例如数组或者任何实现了buffer接口的对象)。
这个协议定义了一组必须实现的方法,这些方法使得实现它的对象能够:
- 告诉其他对象它们的内存信息,如大小、存储方式等。
- 允许其他对象直接读写这些内存区域。
因此,当memoryview被创建时,它实际上是使用了对象的buffer接口来获取关于数据的信息,比如数据类型、数组的形状(shape)、每个元素的大小等。
当使用切片或索引来访问memoryview的某部分时,它会计算出新的视图应该如何表示,而不需要进行任何数据复制。这个计算包括:更新偏移量(offset)以指向正确的内存位置。调整视图的维度和形状,如果需要的话。
memoryview对象还涉及精细的内存管理操作,包括引用计数。Python的垃圾收集系统会跟踪memoryview对象的生命周期,当没有任何引用指向一个memoryview时,它会被自动销毁,其占用的资源会被释放。这一点是自动进行的,用户无需手动管理内存。
2.数组对象
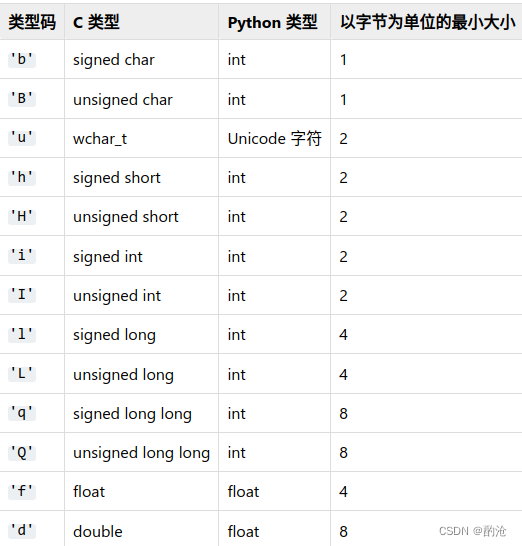
在数组对象创建时用单个字符的 类型码 来指定。已定义的类型码如下
https://docs.python.org/zh-cn/3/library/array.html
3.使用memoryview操作array示例1
利用memoryview的多维视图功能来观察和修改底层array.array对象的数据
from array import array
octets = array('B', range(6)) # 创建一个6字节的数组,类型代码为'B'
m1 = memoryview(octets) # 根据这个数组创建一个memoryview对象,然后导出一个列表
m1_list = m1.tolist() #m1.tolist()将memoryview转换成普通的Python列表,方便查看其内容。
print(m1_list) # [0, 1, 2, 3, 4, 5]
m2 = m1.cast('B', [2, 3]) # 根据前一个memoryview对象构建一个新的memoryview对象,不过是2行3列
m2_list = m2.tolist()
print(m2_list) # [[0, 1, 2], [3, 4, 5]]
m3 = m1.cast('B', [3, 2]) # 在构建一个memoryview对象,这一次是3行2列
m3_list = m3.tolist()
print(m3_list) # [[0, 1], [2, 3], [4, 5]]
m2[1, 1] = 22 # 修改m2中第二行第二列的元素(原本是4)
m3[1, 1] = 33 # 修改m3中第二行第二列的元素(刚才被改为22,现在改为33)
print(octets) # array('B', [0, 1, 2, 33, 22, 5])
4.使用memoryview操作array示例2
首先,我们创建一个类型为 h (有符号短整型)的 array.array 对象,此类型数据每个元素占两个字节,并初始化包含五个整数(-2, -1, 0, 1, 2)。
import array
numbers = array.array('h', [-2, -1, 0, 1, 2])
在内存中,这五个整数的二进制表示如下(注意:Python中整数通常使用补码来存储):
-2 -> 1111 1111 1111 1110
-1 -> 1111 1111 1111 1111
0 -> 0000 0000 0000 0000
1 -> 0000 0000 0000 0001
2 -> 0000 0000 0000 0010
接下来,我们创建一个 memoryview 对象,这样可以在不复制原始数组的情况下操作其数据。
memv = memoryview(numbers)
我们将 memoryview 的数据类型从 h (有符号短整型) 转换为 B (无符号字符,每个字节表示一个整数)。
memv_oct = memv.cast('B')
在转换后,原来由两个字节表示的整数现在被看作是两个独立的字节:
- -2 被拆分为两个字节:1111 1110 和 1111 1111 (对应于 254 和 255)
- -1 被拆分为两个字节:1111 1111 和 1111 1111 (对应于 255 和 255)
- 0 被拆分为两个字节:0000 0000 和 0000 0000 (对应于 0 和 0)
- 1 被拆分为两个字节:0000 0001 和 0000 0000 (对应于 1 和 0)
- 2 被拆分为两个字节:0000 0010 和 0000 0000 (对应于 2 和 0)
转换后的字节序列是:
print(memv_oct.tolist()) # 输出: [254, 255, 255, 255, 0, 0, 1, 0, 2, 0]
我们修改 memoryview 的第6个字节(从0开始计数),将其从0改为4。
memv_oct[5] = 4
这会影响原始数组中第3个整数的高位字节:原本第3个整数为0(0000 0000 0000 0000),修改后变为1024(0000 0000 0010 0000)。最后,我们查看原始的 array.array 对象,看到第三个整数已从0变为1024。
print(numbers) # 输出: array('h', [-2, -1, 1024, 1, 2])
这个示例清楚地展示了如何使用 memoryview 来直接操作内存中的数据。通过改变视图的数据类型和修改数据,我们可以实现对原始数据的高效和精确控制,而无需进行数据复制。


















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









