







作者介绍
熊亚军
灵犀技术总监,原百度系统部高级项目经理,负责百度IT基础设施监控团队,其带领的团队经历了百度服务器规模迈入几十万量级,网络架构数次演进,对服务器尤其是网络层的监控和运维自动化智能化有丰富的经验。
开篇:
在超级互联网公司,随着服务器规模都早早迈过 10 万台量级,加之业务模式的多样性和 IT 架构的云化迁移,其 IT 运维团队面临的挑战与日俱增,常规的系统和经验都需要不断迭代更新。
本文将给大家介绍在超级互联网公司如何基于网络的故障根因自动定位技术,提高故障定位速度,从而提高业务可用性。
规模效应和云的效应极大提升了运维的复杂性
首先我们先来看看超级互联网公司的业务架构示例图:
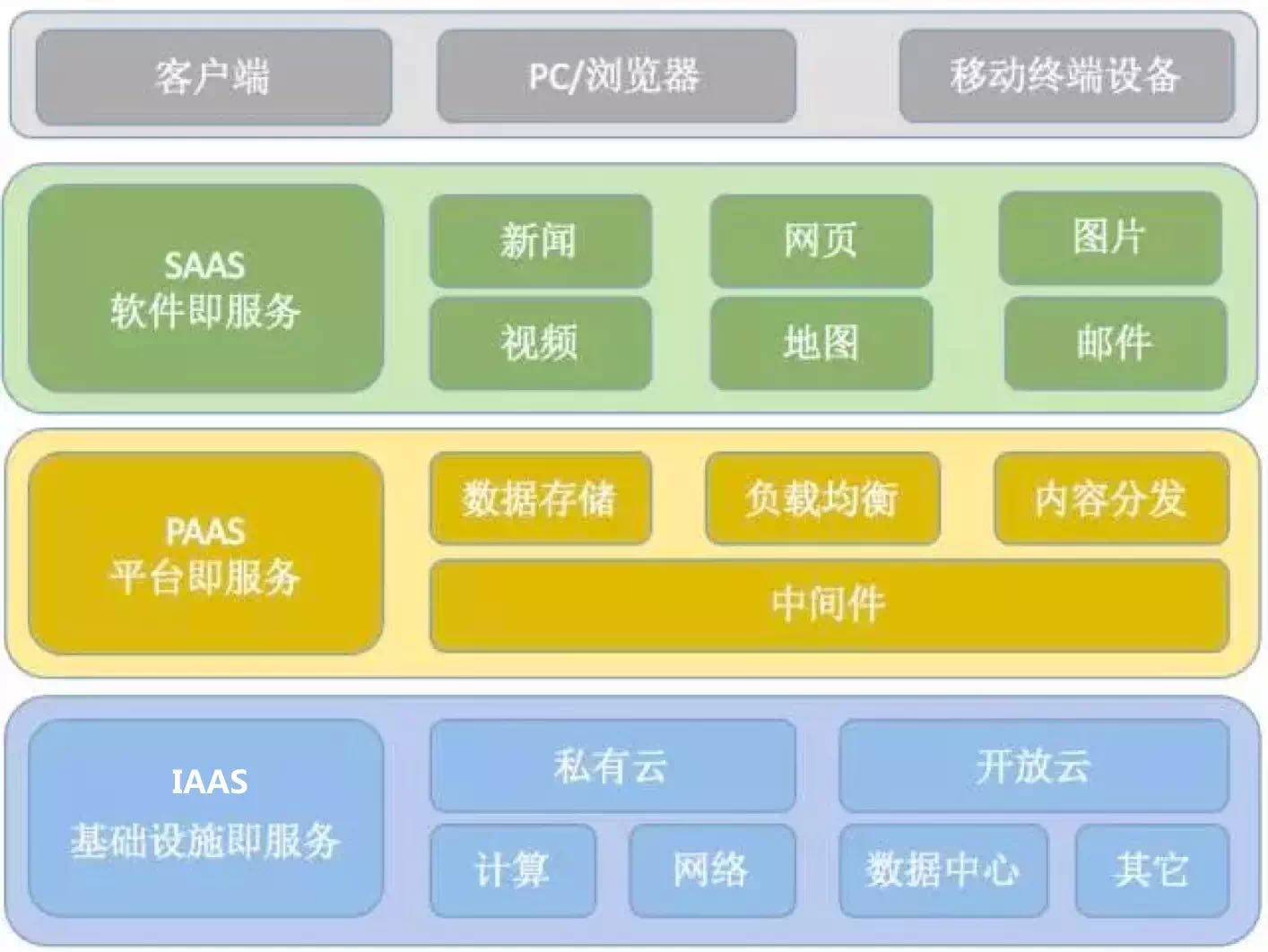
在超级互联网公司中,通常不同的层次都由不同的团队来负责运维管理,同层次不同的硬件/系统/应用都由不同的小组来负责运维管理。
就基础设施即服务这层来说,随着IT设备规模的不断增加,IT 设备故障的告警种类与告警数量也随之急剧增加。
告警的多面性、冗余性、耦合性,导致某些核心层面的故障会引起大面积告警的现象,而这些告警又有可能分属不同小组,运维人员处理故障会增加排查问题的难度以及增加小组间沟通成本。
同时因为对故障信息缺乏统一的管理,无法对告警系统进行反馈优化,致使误报漏报频出。同样也无法进行全面的故障信息统计分析,不知道如何对基础设施资源进行风险管理。
众所周知,IT基础设施层的运维工作,直接影响公司服务稳定性。一次服务中断事件便会对公司造成极大的经济损失。
但正如上述现状描述中提到的问题:
- 运维平台繁杂多样
- 运维小组之间沟通滞后
- 告警信息共享程度低
- 工程师水平参差不齐,故障处理自动化程度较低
告警系统缺乏有效的反馈机制进行系统优化,同时缺少全面有效的故障信息沉淀,无法帮助预算与评估采购系统
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 52
52

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









