







 本文详细介绍了HiveQL如何使用ANTLR3构建词法和语法规则,生成抽象语法树(AST)。内容涵盖了ANTLR3的基本概念、语法规则定义、AST的生成方式以及Hive查询和插入语句的语法树结构。
本文详细介绍了HiveQL如何使用ANTLR3构建词法和语法规则,生成抽象语法树(AST)。内容涵盖了ANTLR3的基本概念、语法规则定义、AST的生成方式以及Hive查询和插入语句的语法树结构。
HiveQL是一个非标准的sql语言,实现了sql的大部分规范,同时添加了一些hive独有的特性。Hive使用antlr3定义HiveQL语言。
1.1 antlr3简介
ANTLR(ANother Tool for Language Recognition)是一款功能强大的语言构建工具,提供了词法分析、语法分析等功能。用户编写语言的词法规则和语法规则,然后通过antlr提供的运行时库将语言转换成抽象语法树。antlr支持java、c、c++、Python等多种语言。Antlr3是antlr的第三版,采用了自顶向下的语法分析方法LL(k),支持语法树重写,import、语法预测等功能。
1.2 antlr3语法规则
使用antlr3定义一种语言需要先通过antlr3定义语言的词法规则和语法规则,然后通过antlr3的工具转换成目标语言的词法分析器和语法分析器代码。如Hive词法规则HiveLexer.g文件和语法规则HiveParser.g文件会被antlr3生成目标语言java对应的HiveLexer.java和HiveParser.java文件。HiveLexer.java是Hive的词法分析器,HiveParser.java则是语法分析器。HiveQL语言经过HiveLexer和HiveParser的分析处理生成抽象语法树AST.
1.2.1语法规则
如下为antrl3定义词法和语法的规则:
grammar-type grammar name;
options { name1 = value; name2 = value2; ... }
import grammar1,grammar2…..;
tokens { token-name1; token-name2 = value; ... }
@header { ... }
@lexer::header { ... }
@members { ... }
«rules»grammar-type为语法类型,常用的包括lexer和parser,lexer是语言的词法规则,parser是语法规则。
options定义了一些可选参数,如下表所示:
| 名称 |
描述 |
| language |
目标语言,默认是java |
| tokenVocab |
指定词法分析器 |
| output |
输出类型,包含AST和template,Hive使用AST. |
| ASTLabelType |
AST节点类型,java默认为CommonTree |
| k |
LL(k)参数,LL分析中提前读取单词个数 |
import为导入的其他语法和词法文件。
tokes包含了所以语法树节点名称。
header包含java的import信息。
memers:antlr3可以在语法规则文件中嵌入目标语言的代码,如java代码等。memers可以定义该语法规则文件的类变量和方法。
rules:定义了语言的词法规则和语法规则。规则的一般格式为:
rule-name:rule1 | rule2…;
rule-name为规则名称,如果是词法规则,rule-name首字母必须大写,语法规则小写。每个规则后面可以包含多条规则,例如:
Letter: ‘a’…’z’ | ‘A’..’Z’; //定义字母
booleanValue: KW_TRUE | KW_FALSE;//定义布尔变量的值
1.2.2 AST生成
antlr3支持两种方式生成抽象语法树(AST):运算符和规则重写.
1) 运算符
语法规则中所有的节点(子规则或者常量)默认作为AST的子节点。可以使用”!”将节点排除语法树外;使用”^”可以将节点设置为语法树的根节点。如:
N : [0-9];
e : e’+‘e | ‘(‘! e !‘)’!;给定输入1+1,生成语法树为:
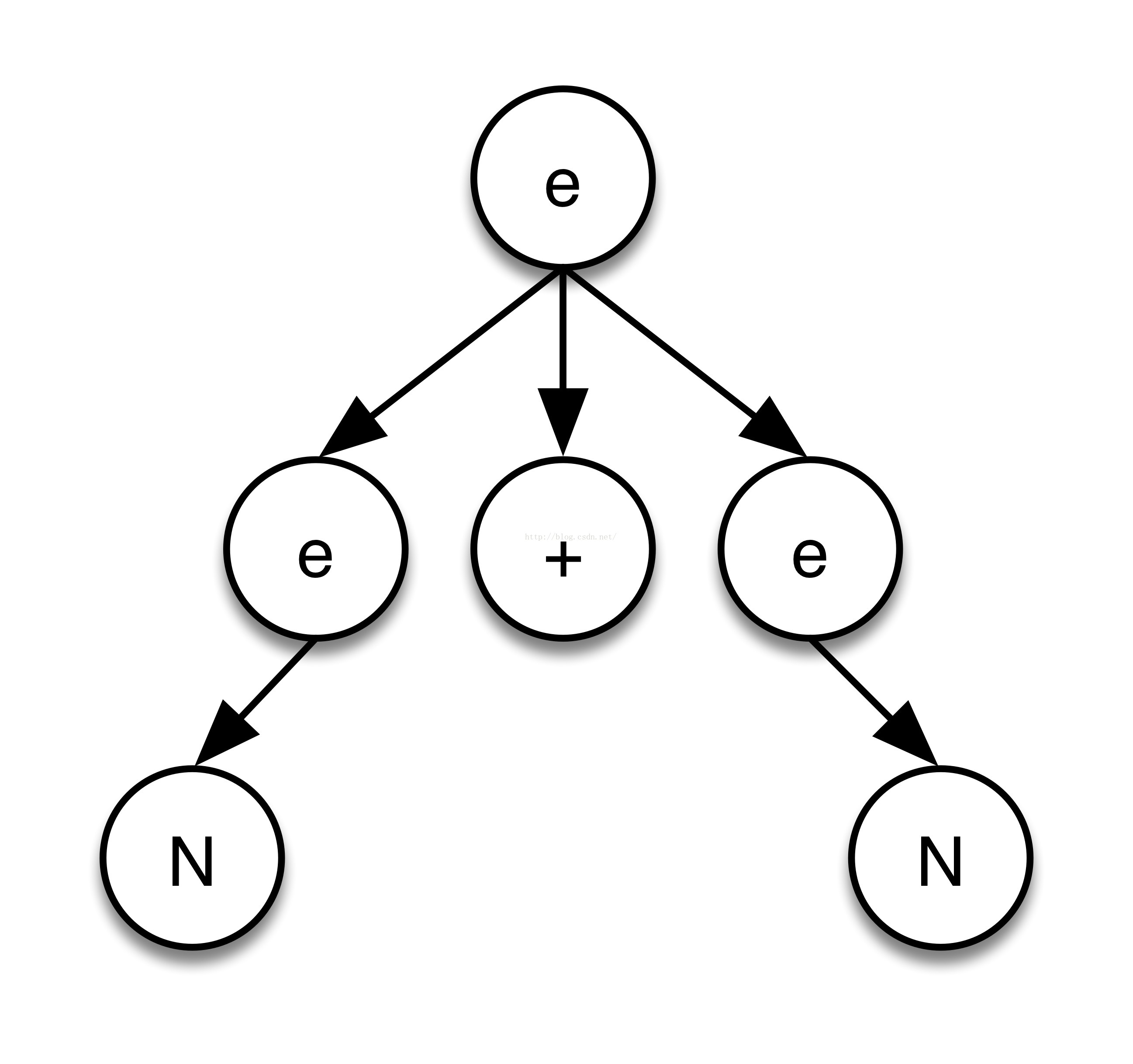
输入(1)生成的语法树则为:

可见,左右两边的括弧被排除出AST了。
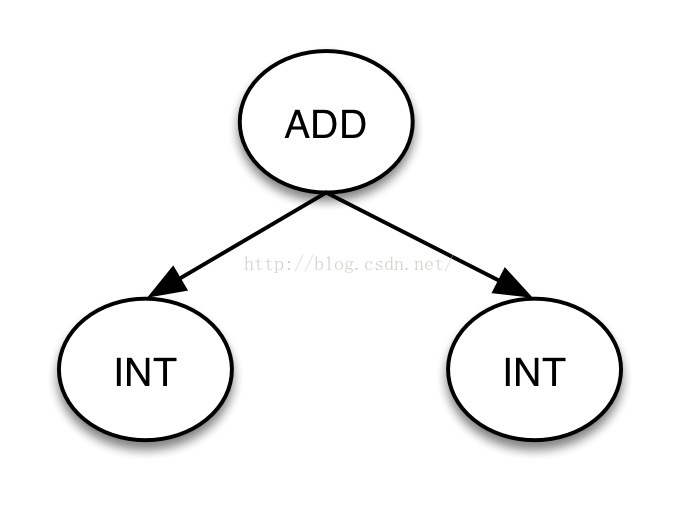
2)规则重写
antlr3可以在语法规则中使用”->”符号指定生成的语法树,称之为规则重写,如:
INT:[0-9]+
add: a=INT ‘+’ b=INT -> ^(ADD $a $b)
关于antlr3的详细使用请参考官方文档http://www.antlr3.org/
1.3 Hive语法树
Hive的词法规则和语法规则文件定义在Hive源码ql工程org/apache/hadoop/hive/ql/parse目录下,主要文件及功能说明如下表所示:
| 文件名 |
功能 |
| HiveLexer.g |
HiveQL词法规则</ |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1869
1869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









