







文章目录
1. select语法树
[with 表别名 as (查询语句)] -- 先写子查询,从而让代码更加任意看懂
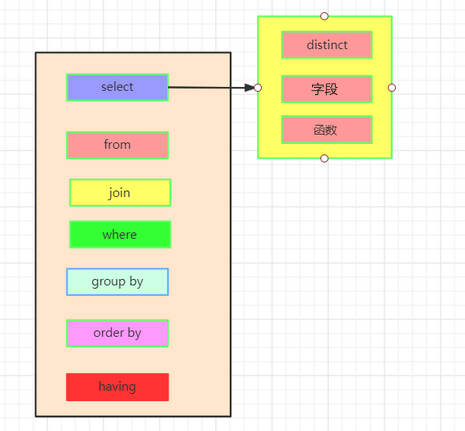
select [all | distinct] select_expr
from table_reference
[where where_condition]
[group by col_list [grouping sets | with cibe | with rollup]] --高阶聚合
[having having_condition]
[order by col_list]
[cluster by col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]]
[union [all | distinct]]
[limit [offset,] rows];
- 其中,
表名和列名不区分大小写。
2. 基本语法
2.1 all | distinct
all | distinct:前者表示对查询到的结果不去重,后者表示去重(只显示第一次出现的)- 默认为
all
2.2 select_expr
-
select_expr可以是 字段、正则表达式 或 函数。-- 1. 字段 select * from t_usa_covid19_p; select county, cases, deaths from t_usa_covid19_p; -- 2. 正则表达式 -- 如果要使用正则表达式,则需要先执行该语句 SET hive.support.quoted.identifiers = none; --带反引号的名称被解释为正则表达式 -- select表达式为正则表达式的查询语句 select `^c.*` from t_usa_covid19_p; -- 3. 函数 --查询当前数据库 select current_database(); --省去from关键字 --查询使用函数 select count(county) from t_usa_covid19_p;
2.3 table_reference
table_reference非常关键。它指名了从哪里查询,可以是普通物理表、视图、join结果 或 子查询结果
2.4 where
where后面是一个布尔表达式,用于第一次查询过滤。其中表达式可以是运算符、任何函数、子查询 和 分区过滤,但聚合函数除外。- 为什么不能使用聚合函数?
- 因为聚合函数要使用它的前提是结果集已经确定。执行完where语句后结果集才确定,因此在where语句中不能使用聚合函数。
- 聚合函数有哪些? sum(), count(), min(), max(), avg(), collect_set(), collect_list()
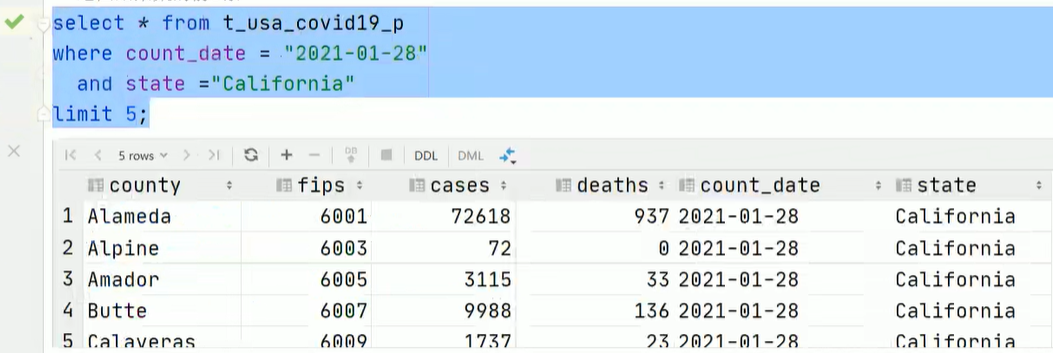
-- 1. 运算符、任何函数 select * from t_usa_covid19_p where length(state) > 10 ; -- 2. 子查询 select * from A where A.a in (select foo from B); -- 3. 分区过滤。假设t_usa_covid19_p分区表的分区字段为 count_date 和 state -- 只会对该分区扫描,不会全表扫描 select * from t_usa_covid19_p where count_date = "2021-01-28" and state ="California" and deaths > 1000;
2.5 group by (分组聚合、分组排序)
-
group by后面接一个或多个表字段,根据字段值对 已经确定的结果集 进行分组。 -
使用
group by分组,则 必须实现 分组聚合,而 分组排序 是可选的。-
分组后排序:① 若组内全局排序,则
group by+order by;② 若组内分区排序,则group by+cluster by / distribute by + sort by注意:如果要实现对原数据分组排序,只能使用开窗函数。因为 group by 会使得行数变少,而开窗保留原数据。具体可用:
select *, row_number() over(partition by 字段 order by 字段) as flag from 表名;
-
分组后聚合:一旦使用了 group by 关键字,那么
select后面的字段中:
① 有group by分组字段则直接写;
② 其余非分组字段都必须套上 聚合函数;
③ 另外可以写常数字段"张三" as name。
所以 最终分为几组就返回几行数据。因此,group by 分组统计之后不能显示原表数据。【如果想要 分组统计 之后还携带原表数据,则使用 窗口函数】- 问:为什么
select后面的字段中,非分组字段都必须套上聚合函数? - 答:避免出现一个字段多个值的歧义。

- 如果是联合分组,联合分组中的任何一个字段都可以直接写在select后面:
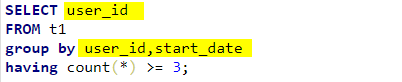
- 对于非分组字段,如果存在字段在分组后,每一组都只有一个值,也就是说不会造成歧义,那么该字段可以不套上聚合函数。
--根据state州进行分组 -- 1. 错误例子 --deaths不是分组字段,必须套上聚合函数。 --state是分组字段 直接用 -- 因此,会报错:SemanticException:Expression not in GROUP BY key 'deaths' select state,deaths from t_usa_covid19_p where count_date = "2021-01-28" group by state; --2. 正确例子:应该给非分组字段套上聚合函数 select state,count(deaths) from t_usa_covid19_p where count_date = "2021-01-28" group by state; - 问:为什么
-
-
group by后面可以接数字,代表select后面的字段。比如:with data as ( select 'aaa' as name, 90 as money, 10 as age union all select 'aaa' as name, 30 as money, 20 as age union all SELECT 'bbb' AS NAME, 20 AS money, 30 as age UNION ALL SELECT 'bbb' AS NAME, 10 AS money, 40 as age ) select name, sum(money) as money from data group by 1 -- 这里的1等价于select后面的第一个字段,即name也可以数字,字段混合使用,比如:
with data as ( select 'aaa' as name, 90 as money, 20 as age union all select 'aaa' as name, 30 as money, 20 as age union all SELECT 'bbb' AS NAME, 20 AS money, 30 as age UNION ALL SELECT 'bbb' AS NAME, 10 AS money, 30 as age ) select name, age, sum(money) as money from data group by 1, age -
group by之后:
① 字段后直接使用聚合函数,则 每一组采用相同的聚合方式;
② 字段后case...end,每一个分支单独用聚合函数,则 不同组可以采用不同的聚合方式。
例子:WITH DATA AS ( SELECT 'aaa' AS NAME, 90 AS money, 20 AS age UNION ALL SELECT 'aaa' AS NAME, 30 AS money, 20 AS age UNION ALL SELECT 'bbb' AS NAME, 20 AS money, 30 AS age UNION ALL SELECT 'bbb' AS NAME, 10 AS money, 30 AS age UNION ALL SELECT 'ccc' AS NAME, 1 AS money, 1 AS age ) SELECT NAME, CASE WHEN NAME = 'aaa' THEN SUM(money) WHEN NAME = 'bbb' THEN SUM(age) END AS col1, -- 'aaa'、'bbb'两组采用不同的聚合方式 COUNT(1) AS col2 -- 'aaa'、'bbb'、'ccc' 所有组采用相同的聚合方式 FROM DATA GROUP BY 1
2.6 having
having后面是一个布尔表达式,用于第二次查询过滤。其中表达式不仅和where的表达式一样,可以是运算符、任意函数、子查询 和 分区过滤,而且还可以使用聚合函数。- 应用场景:因为where无法使用聚合函数进行过滤,因此having一般用于使用聚合函数过滤
- 为什么能使用聚合函数过滤?因为经过where 和 group by后,结果集已经是确定的了。
- where与having区别:
- where是在分组前对数据进行过滤;having是在分组后对数据进行过滤
- where后面不可以使用聚合函数;having后面可以使用聚合函数
- 如果having使用聚合函数进行过滤,则having后面使用字段聚合后的别名效率会更高,而不是直接聚合函数。因为这样可以少使用一次聚合函数,提高查询效率。
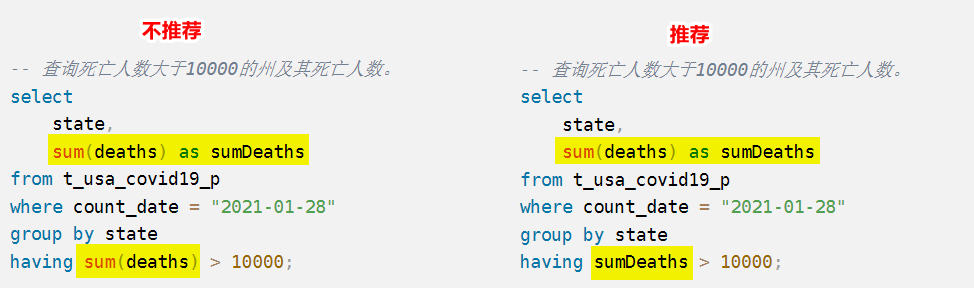
- 例子:统计死亡病例数大于10000的州及死亡人数
-- 1. 错误例子:where后面不能是聚合函数,可以是运算符、任意函数、子查询、分区过滤 select state,sum(deaths) from t_usa_covid19_p where count_date = "2021-01-28" and sum(deaths) > 10000 group by state; -- 2. 改正确: select state,sum(deaths) as sumDeaths from t_usa_covid19_p where count_date = "2021-01-28" group by state having sumDeaths > 10000;
2.7 排序
2.7.1 全局排序:order by
-
order by作用:① 对数据 进行 全局排序;
② 搭配group by可以实现 分组后全局排序。- 如果我们使用了
order By排序,意味着MR 任务只会有一个Reducer参与排序。 - 在公司中,
order by是不建议使用的,效率太低了!!!在数据特别少时可以使用。生产环境中数据过多,放一个reducer中排序,一般一个reducer是根本跑不成功的,会报错。 - 如果非要使用, 建议:在进行排序前一定要进行分区过滤,并且使用limit关键字进行行数限制。
- Hive 中可以针对
order by设置使用模式,严格模式(即hive.mapred.mode = strict)下,只要使用了order by,在运行时就会直接报错的,order by子句必须后跟一个limit子句。
- 如果我们使用了
-
升序或降序排序:
order by asc|desc 字段名:放在字段前,表示null值放在首行。 (asc表示升序,desc表示降序)order by 字段名 asc|desc:放在字段后,表示null值放在尾行。-- 目标:查询2021年1月28日California州死亡人数为前三的信息 select * from t_usa_covid19_p where count_date = "2021-01-28" and state ="California" order by deaths desc limit 3;
-
order by后面可以指定多个字段:先根据第一个字段排序,再根据第二个字段排序…-- 先根据gpa字段增序排序,当gpa字段中存在多行相等时,这些相等的行再根据age字段降序排序 select device_id, gpa, age from user_profile order by gpa asc,age desc;
2.7.2 分区排序:cluster by | distribute by + sort by
- 排序发生的时机:在数据进入reduce之前为每个reducer都产生一个排序后的文件,经过reduce处理之后产生最终文件,一个reduce产生一个文件。
- 分区排序只保证每个 reducer 的输出有序,不保证全局有序,也就是不保证 reducer 间是有序的。
(1) distribute by(指定分区规则) + sort by(每个reduce内部排序)
-
distribute by
- 作用:为每行数据打上分区号标签,表明该行数据属于哪一个分区。类似于
MapReduce中分区partationer对数据进行分区。 - 计算规则:根据指定一个或多个字段分区,
分区号 = 字段值的hash值 % 设置的reduce个数。因此,可以的到两个结论:- 分为几个分区取决于reducetask的个数
- 如果
distribute by 字段名,该字段的枚举值个数 <= 设置的reduce个数,那么该字段相同的行会 放入同一个分区。
- Hive如何进行自定义分区?(点击此处)
- 作用:为每行数据打上分区号标签,表明该行数据属于哪一个分区。类似于
-
sort by
- 功能:只保证分区内有序,不保证全局有序。其在数据进入reducer前完成排序,类似于
MapReduce的reduce向map拉取属于自己分区的数据之后要进行一次归并排序。也就是说它会在数据进入reduce之前为每个reducer都产生一个排序后的文件。 - sort by 和 order by:
order by能保证全局有序,但是只能由一个reduce执行;sort by只能保证分区有序,但是多个reduce可以并行计算,更快。注意:sort by 不是在所有情况下都比 order by 快。当数据量比较小的时候,reducer 的启动耗时可能远远数据处理的时间长,此时效果就反过来了。
- limit:
sort by + limit效率比order by + limit效率高。- sort by + limit n: ① 传输到reduce端的数据记录数就减少到 n *(map个数);
② 再根据sort by的排序字段进行排序;
③ 最后返回 n 条数据给客户端, - order by + limit n:是对所有数据排序好后再取 n 条数据,效率会底很多。
- sort by + limit n: ① 传输到reduce端的数据记录数就减少到 n *(map个数);
- 功能:只保证分区内有序,不保证全局有序。其在数据进入reducer前完成排序,类似于
-
distribute by + sort by:两者是好基友,常常搭配使用。
- 分区字段 和 排序字段可以相同也可以不相同
- 根据指定一个或多个字段分区,每一个分区内对指定的排序字段进行排序(可以升序也可以降序)。
基本上不用
cluster by,一般用distribute by + sort by
无论是distribute by + sort by还是cluster by在使用前都需要设置reducetask个数:-- 例子:把学生表数据根据性别分为两个部分,每个分组内根据年龄的倒序排序。 -- 设置reduce 个数 set mapreduce.job.reduces=2; -- 查看设置 reduce 个数 set mapreduce.job.reduces; -- 分组排序 select * from student distribute by sex sort by age desc;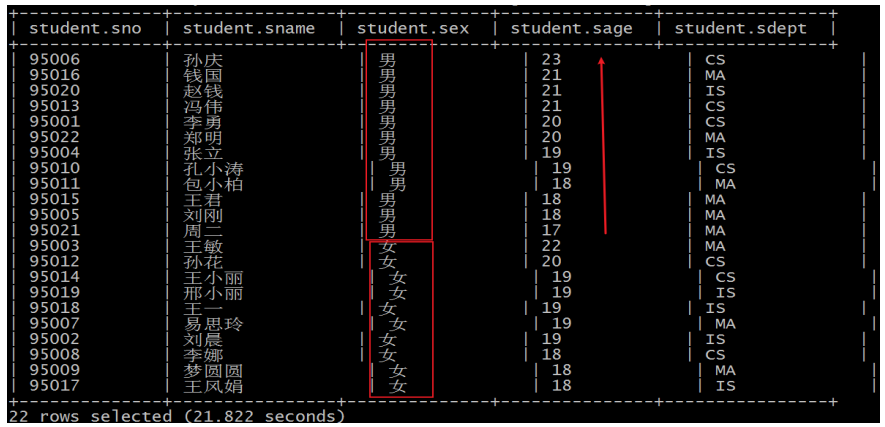
(2) cluster by (分区字段和排序字段相同时使用)
cluster by:等价于distribute by和sort by字段相同的情况。
------- 小结 order by vs cluster by vs distribute by + sort by

------- 分区排序 vs 分桶表
分区排序 与 分桶表 做的是相同的事情,都是用文件将数据隔开。但是又有所不同:
- 若
分桶表的分桶个数 == 分区排序的reducer个数,他俩结果一样。那么此时对于给个写入分桶表的SQL可以省略cluster by或者distribute by + sort by语法。 - 若
分桶表的分桶个数 != 分区排序的reducer个数:- 分桶表:强制分桶的情况下,最终文件数据等于分桶数,
分桶字段值 % 分桶数量 - 分区排序:最终文件数据等于分区数,
字段值的hash值 % 设置的reduce个数
- 分桶表:强制分桶的情况下,最终文件数据等于分桶数,
那么什么情况下使用 分区排序 vs 分桶表 ?
- 如果对于每个分区文件夹数据都需要用文件隔开,那么用分桶表
- 如果只是部分分区文件夹数据需要用文件隔开,那么使用分区排序就比较灵活。
2.8 limit
- 功能:
limit用于限制select语句返回的行数。 - 语法:
- 方式一:
limit 数字- limit + 一个数字n:从第一行开始,显示n行数据(包括第一行,即偏移量是从0开始)
- limit + 两个数字a, n:从第a行开始,显示n行数据(包括第a行,即偏移量是从0开始)
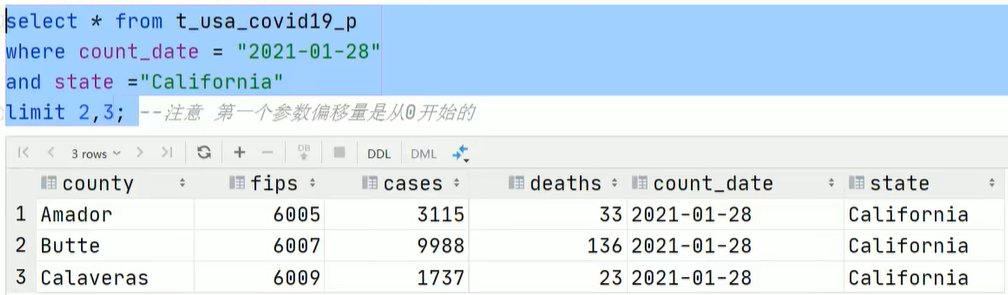
- 方式二:
limit 数字 offset 数字

- 方式一:
- with语法 vs cache table 语法:https://blog.csdn.net/qq_43546676/article/details/136937814
2.9 CTE表达式
CTE表达式功能等价于子查询。
-
问:那为什么要有CTE表达式?
-
答:CTE表达式将子查询写在前面,从而使得代码更加容易读懂,逻辑感更强。
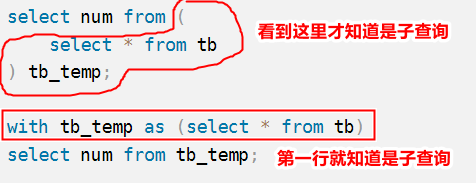
-
语法:
WITH d1 AS (SELECT ... FROM ...), -- 这里的select语句没有封号; d2 AS (SELECT ... FROM d1 ... ) -- 这里的select语句没有封号; ... SELECT FROM d1, d2 ...; -
实现方式:为查询结果取别名,有点视图的味道。与视图的区别在于CTE的创建与查询语句必须一起执行才不会出错,而视图可以先执行创建视图语句,再执行查询语句。
-- 例子: select num from ( select * from tb ) tb_temp; -- 等价于 with tb_temp as (select * from tb) select num from tb_temp; -- from风格 with tb_temp as (select * from tb) from tb_temp select num; -- 嵌套子查询 with t1 as (select * from student where num = 95002) t2 as (select num, name, age from t1) select * from t2; -- 联合擦好像 with t1 as (select * from student where num = 95002) t2 as (select * from student where num = 95003) select * from t1 union all select * from t2;
3. 执行顺序
一条标准的sql查询语句为:
面试时问:只需要回答关键字即可

其中,在
select处的函数执行顺序可参考:https://blog.csdn.net/qq_43546676/article/details/131004933

select distinct
state,
sum(deaths) as cnts
from t_usa_covid19_p
where count_date = "2021-01-28"
group by state
having cnts> 10000;
order by cnts
limit 3;
4. 高阶语法
4.1 union联合查询
-
union [all | distinct]用于将来自于多个select语句的结果合并为一个结果集。union all:表示不去重。union distinct:表示去重。(默认)
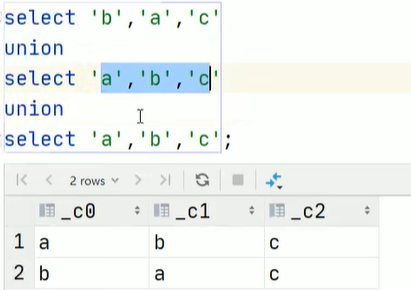
-
由于是拼接,所以每个select_expr返回的列的数量和名称必须相同。
select num,name from student_local union distinct select num,name from student_hdfs;- 注意:若上下列名不一致,不会报错,但会以上面的列名为主
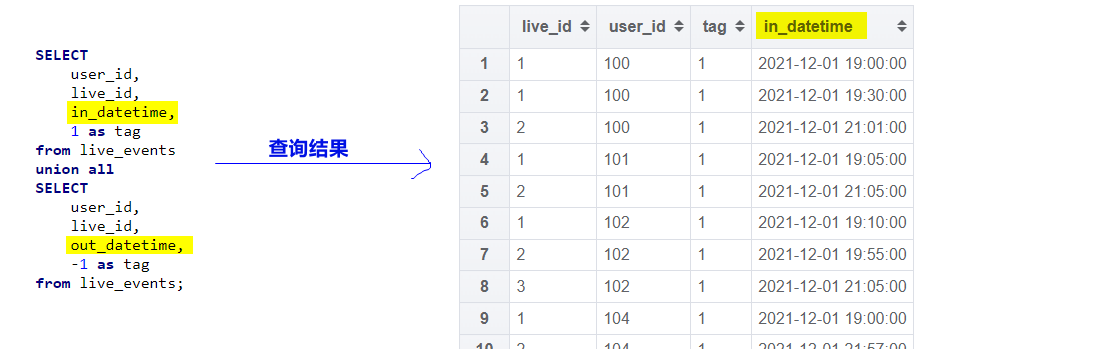
- 注意:若上下列名不一致,不会报错,但会以上面的列名为主
-
关于先联合还是先处理:
-
联合之后再处理:必须将先将联合写成子查询,之后再处理
select num, name from ( -- 先将数据联合起来 select num,name from student_local union select num,name from student_hdfs ) order by num desc; -
处理之后再联合:注意一点就行:
order by和limit是针对整个SQL语句,where、group by、having都是针对子句的

-
例子1:where 是针对子句生效,可以出现多次

-
例子2:limit 是针对整个整个SQL生效,只能出现一次
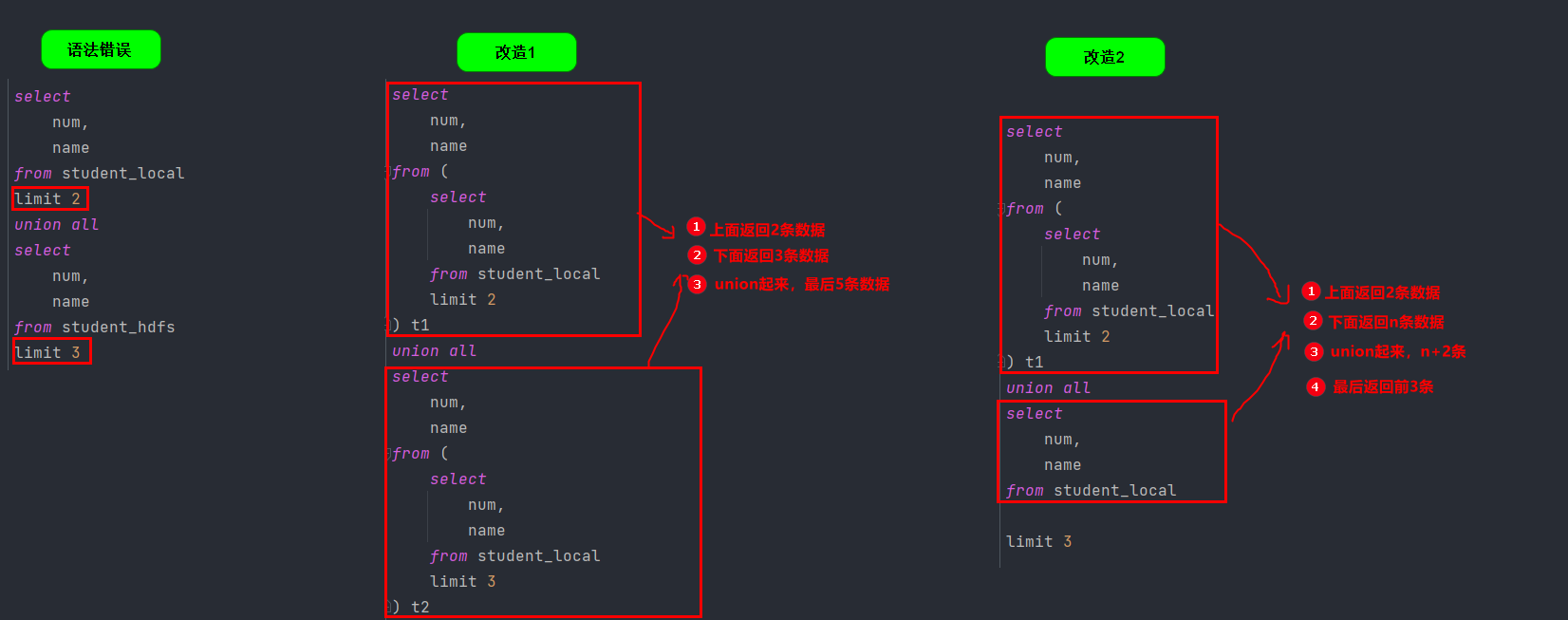
-
-
4.2 子查询
(1) 在from后
- 子查询必须取别名。
- 只有from后的子查询可以改造为
CTE表达式
(2) 在 where/select 后
- 要么是不相关子查询,要么是相关子查询
-
不相关子查询:子查询不引用父查询中的列。在括号前加上
in或not in【608. 树节点】-- 不相关子查询可以放在 where/select 后 -- 例子:where + 列名 + in + 子查询 SELECT * FROM student_hdfs WHERE student_hdfs.num in (select num from student_local limit 2); -- 例子:select + 列名 + in + 子查询 select if(id in (select p_id from tab2), "yes", "no") from tab1; -
相关子查询:子查询引用父查询中的列。在括号前加上
exit或not exit-- 相关子查询只能放在 where 后 -- 例子:where + exists + 子查询 SELECT A FROM T1 WHERE EXISTS (SELECT B FROM T2 WHERE T1.X = T2.Y);
-
- where/select后的子查询不可以改造为
CTE表达式【SQL91 返回购买价格为 10 美元或以上产品的顾客列表】
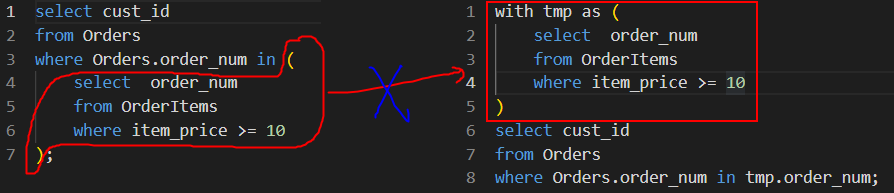
-------- 无论在from后还是where/select后
-
子查询里面还可以包含子查询,即嵌套子查询
SELECT num FROM ( select num,name from ( select * from student ) as tmp1 ) tmp2; -
子查询可以是联合查询
select t3.name from ( select num,name from student_local UNION distinct select num,name from student_hdfs ) t3;
4.3 join 表连接
- 背景:数据库的表是满足
三范式设计的,也就是说一个完整字段的大表会拆分成多个不完整字段的小表,那么在需要将小表合成大表时,就需要join语法。

- 分类:
- inner join(内连接)
- left join(左连接)
- right join(右连接)
- full join(全连接)
- left semi join(左半开连接)
- cross join(交叉连接,也叫做笛卡尔乘积)
- 位置:在from后使用 join 将多个表连接起来合成一个表。因此join是在where条件之前执行的。
4.3.1 inner join(内连接)
-
含义:以左表为基准,右表去比对;或以右表为基准,左表去比对都可以。(因为是交集,结果集一样)
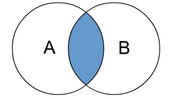
-
语法:
①inner join关键字:table1 inner join table2 on fields
② 可以 省略inner 只用join关键字:table1 join table2 on fields
③ 可以用逗号,代替 inner join 关键字:table1, table2 on fields
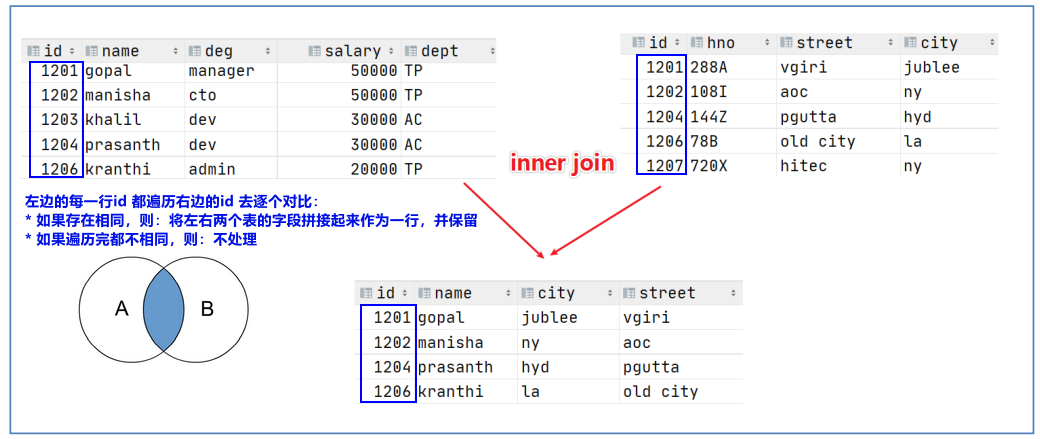
-
因此,如果以左表为基准,右表比对时:如果左表某行的id在右表遍历重复出现n次,则会保留n行。
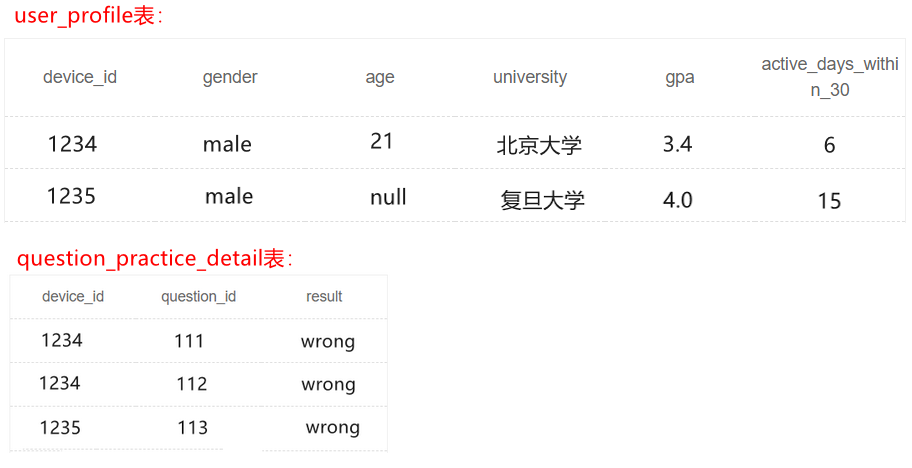
up.device_id as device_id, gender, age, university, gpa, active_days_within_30, question_id, result from user_profile up join question_practice_detail qpd on up.device_id = qpd.device_id; -
结果为:

-- 1. inner join select e.id,e.name,e_a.city,e_a.street from employee e inner join employee_address e_a on e.id =e_a.id; -- 2. 等价于 join select e.id,e.name,e_a.city,e_a.street from employee e join employee_address e_a on e.id =e_a.id; -- 3. 等价于 隐式连接表示法, select e.id,e.name,e_a.city,e_a.street from employee e, employee_address e_a where e.id =e_a.id; -
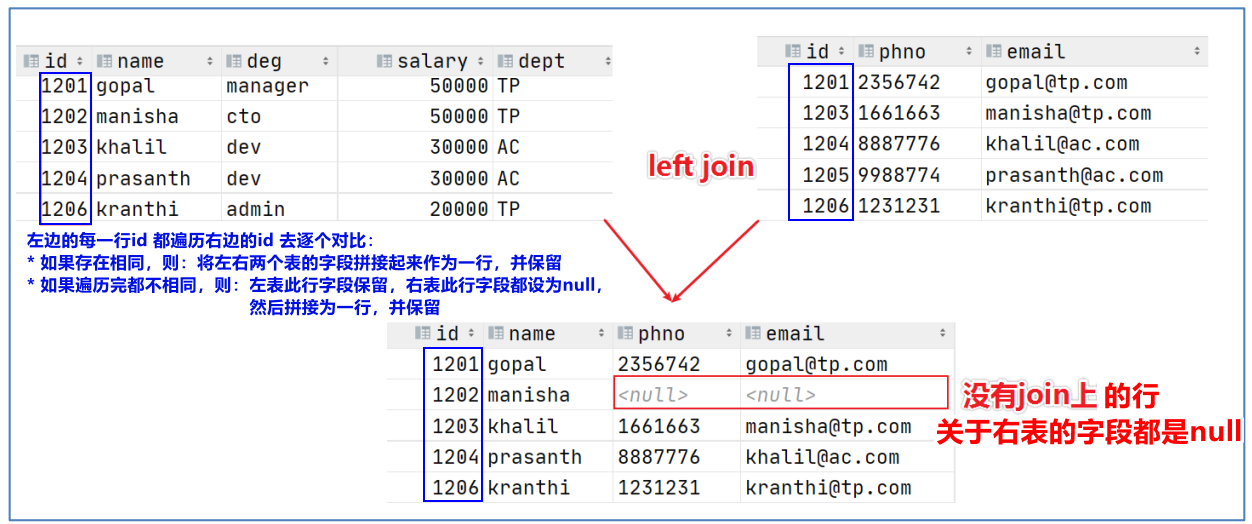
4.3.2 left join (左连接)
-
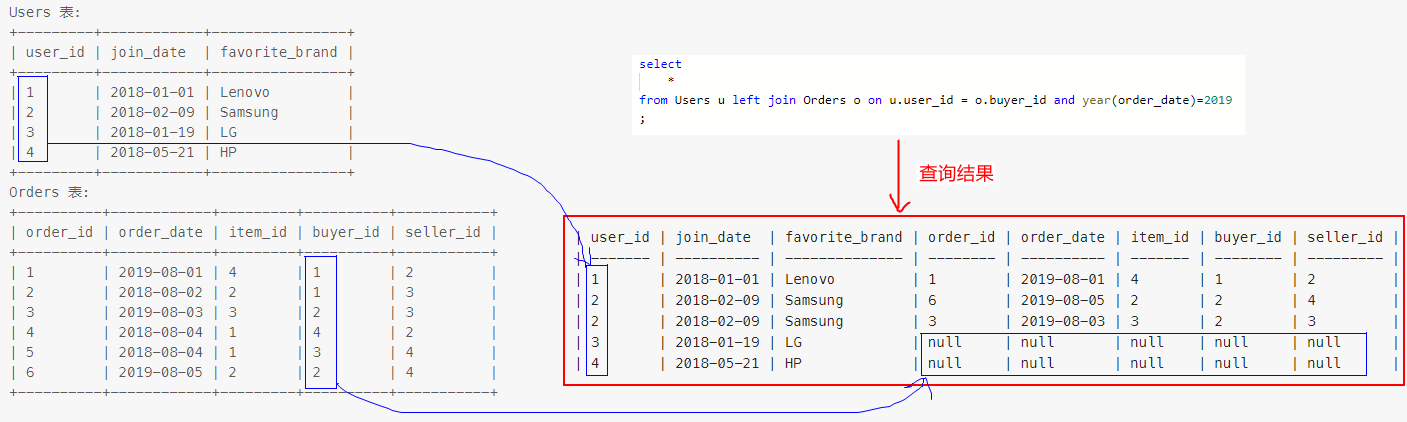
含义:以左表为基准,右表去比对。左表都显示,右表比对的上就显示右表,右表比对不上就显示null
注意:以左表为基准,不是说查询结果的行数为左表的行数;而是说拿右表去对比左表,若多次匹配上,则返回的行数多于左表行数:
-
语法:
①left outer join关键字:table1 left outer join table2 on fields
② 可以 省略outer 用left join关键字:table1 left join table2 on fields
-- 1. left outer join select e.id,e.name,e_conn.phno,e_conn.email from employee e left outer join employee_connection e_conn on e.id =e_conn.id; -- 2. 等价于 left join select e.id,e.name,e_conn.phno,e_conn.email from employee e left join employee_connection e_conn on e.id =e_conn.id;
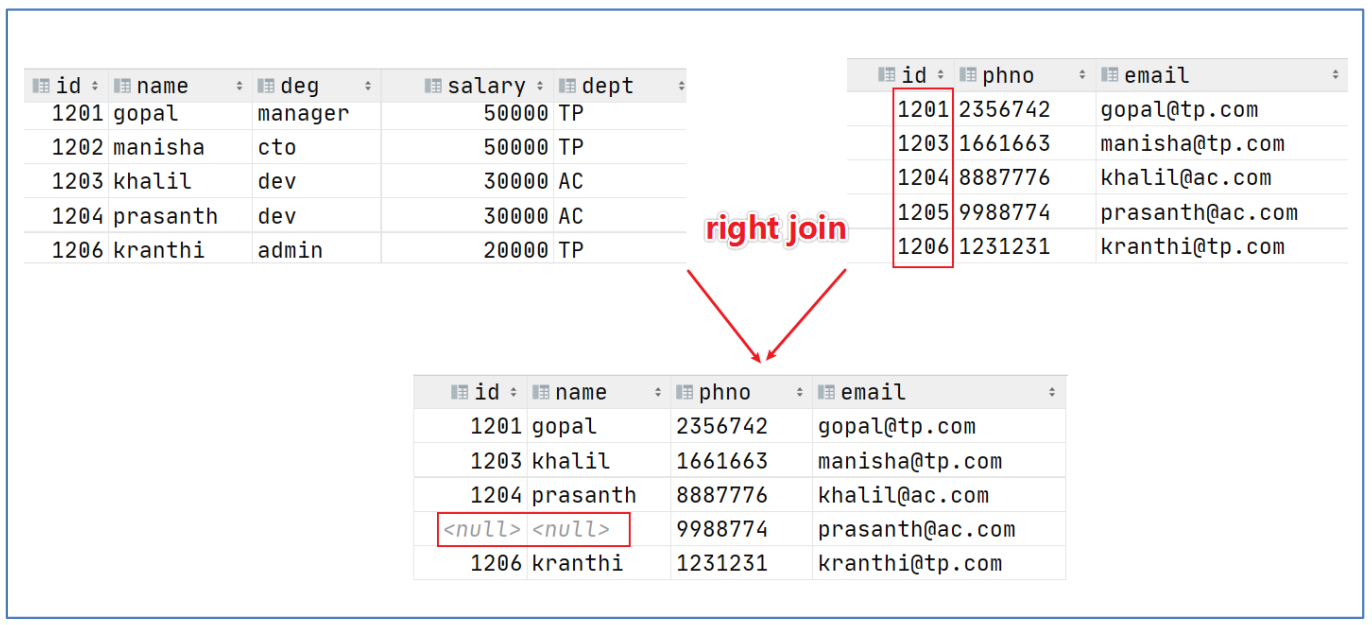
4.3.3 right join(右连接)
与left join类似,他们转换左右方向后是等价的。
-
含义:以右表为准,左表去比对。右表都显示,左表比对的上就显示左表,左表比对不上就显示null
-
语法:
①right outer join关键字:table1 right outer join table2 on fields
② 可以 省略outer 用right join关键字:table1 right join table2 on fields
-- 1. right outer join select e.id,e.name,e_conn.phno,e_conn.email from employee e right outer join employee_connection e_conn on e.id =e_conn.id; -- 2. 等价于 right join select e.id,e.name,e_conn.phno,e_conn.email from employee e right join employee_connection e_conn on e.id =e_conn.id;
4.3.4 full join(全连接)
-
含义:等价于 先左连接;再右连接;最后去重。
-
语法:
①full outer join关键字:table1 full outer join table2 on fields
② 可以 省略outer 用full join关键字:table1 full join table2 on fields
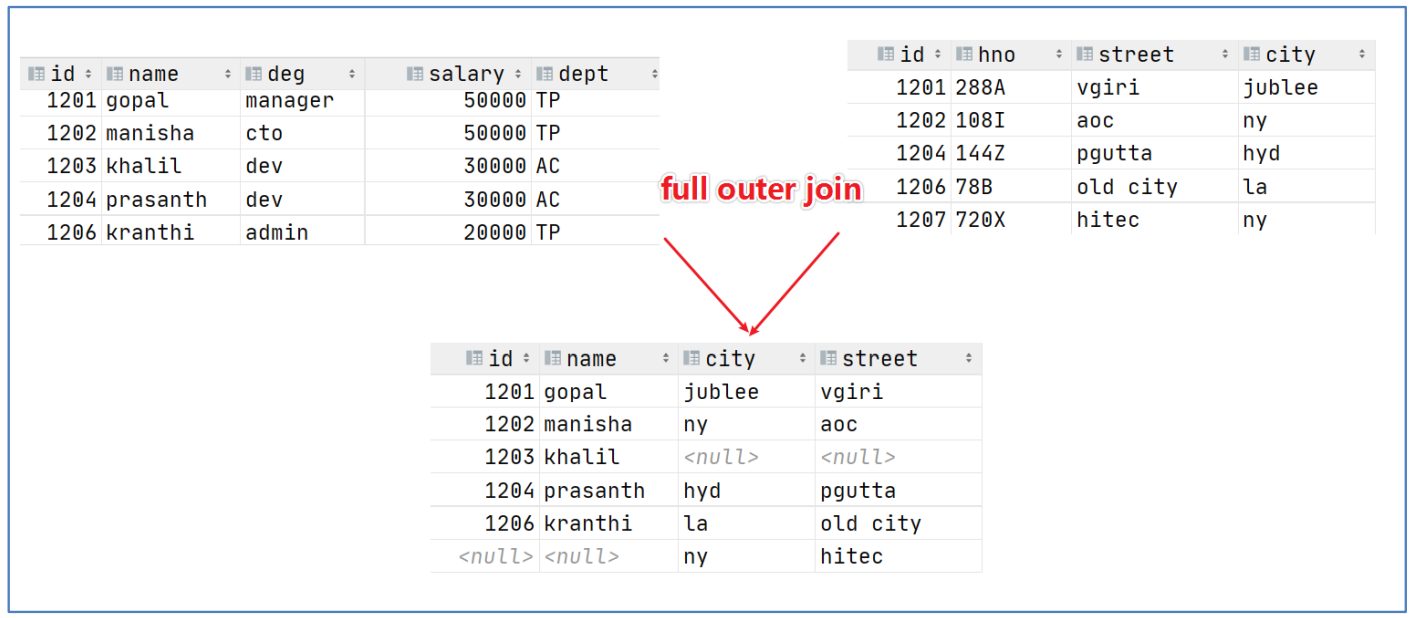
-- 1. full outer join select e.id,e.name,e_a.city,e_a.street from employee e full outer join employee_address e_a on e.id =e_a.id; -- 2. 等价于 full join select e.id,e.name,e_a.city,e_a.street from employee e full join employee_address e_a on e.id =e_a.id; -
关于主键为
null时,会匹配不上with data1 as ( select 'aaa' as name, 1 as num union all select 'aaa' as name, 2 as num union all select 'bbb' as name, 3 as num union all select null as name, 4 as num ), data2 as ( select 'aaa' as name, 5 as num union all select 'bbb' as name, 6 as num ) select data1.name, data1.num, data2.name, data2.num from data1 full join data2 on data1.name = data2.name结果:

-
常见使用场景:数据diff时,使用full join
-
需要查看明细数据:
/* 数据DIFF模板:看不同数据的明细数据 */ select old.ws_dim as old_ws_dim, new.ws_dim as new_ws_dim, old.ws_data as old_ws_data, new.ws_data as new_ws_data from ( select concat_ws('@', title, channel) as ws_dim, concat_ws('@', disp_pv, disp_uv, click_pv, click_uv) as ws_data from ( -- 旧sql ) t ) old full join ( select concat_ws('@', title, channel) as ws_dim, concat_ws('@', disp_pv, disp_uv, click_pv, click_uv) as ws_data from ( -- 新sql ) t ) new on old.ws_dim = new.ws_dim where old.ws_dim is null or new.ws_dim is null or old.ws_data != new.ws_data -
只查看占比
/* 查看diff占比 */ select CASE when old.ws_dim is null then 1 when new.ws_dim is null then 2 when old.ws_dim = new.ws_dim and old.ws_data = new.ws_data then 3 when old.ws_dim = new.ws_dim and old.ws_data != new.ws_data then 4 else 5 end as kind, count(1) as cnt from ( select cuid as ws_dim, concat_ws('@', auto_refresh_cnt, mannual_refresh_cnt, pulldown_refresh_cnt, pullup_refresh_cnt, bottomright_refresh_cnt, remindmid_refresh_cnt, main_refresh_cnt, error_refresh_cnt) as ws_data from ( -- 旧sql ) t ) old full join ( select cuid as ws_dim, concat_ws('@', auto_refresh_cnt, mannual_refresh_cnt, pulldown_refresh_cnt, pullup_refresh_cnt, bottomright_refresh_cnt, remindmid_refresh_cnt, main_refresh_cnt, error_refresh_cnt) as ws_data from ( -- 新sql ) t ) new on old.ws_dim = new.ws_dim group by 1
-
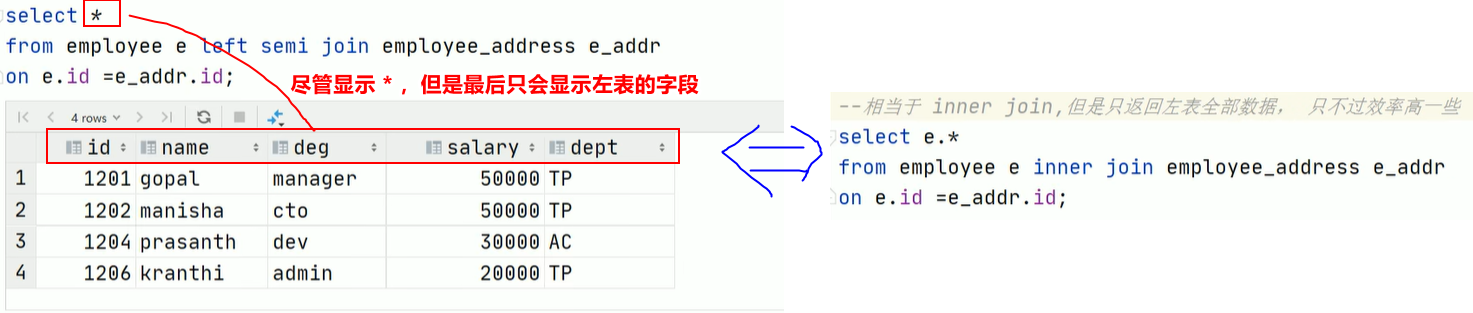
4.3.5 left semi join(左半开连接)
- 含义:相当于 内连接后,只显示左表的数据。(一般不会用,因为两表进行笛卡尔积,数据会爆炸增长)
- 语法:
4.3.6 cross join(交叉连接,也叫做笛卡尔乘积)
-
含义:根据两表指定的字段,进行笛卡尔积。返回结果的行数等于两个表行数的乘积
-
语法:
select * from employee a cross join employee_address;
------ 关于join on的on关键字
-
如果不写
on关键字,就是进行笛卡尔积,两个表的每行都两两拼接;
写on关键字就是根据on关键字后面的逻辑判断两个表的哪些行的拼接保留。 -
连接 + where与连接 + on能实现相同的效果,但是效率不同。【SQL96 返回顾客名称和相关订单号】select cust_name, order_num from Customers c join Orders o where c.cust_id = o.cust_id -- 虽然此效率更低,但是可以使用谓词下移提高效率 order by cust_name,order_num; select cust_name, order_num from Customers c join Orders o on c.cust_id = o.cust_id order by cust_name,order_num; -
cross join是笛卡尔积,会将所有行都保留,所以不写on关键字,写就写on 1=1
------- 6大注意事项(重要)
-
在 join … on () 的
on后面多个字段用and,另外还支持非等值连接-- 多个字段用and 的例子 SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department)
-- 非等值连接的例子 select uid,购买个数,折扣 from 表B inner join 表A on 表B.购买个数 >=表A.开始个数 and 表B.购买个数 <=表A.结束个数 -
同一查询中可以连接2个以上的表
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) -
同一查询中连接2个以上的表时,表字段相等一次,底层MapReduce任务少一个
-- 有两个join,因此会产生两个MR。 -- 但是由 a.key = b.key1 与 c.key = b.key1 得到 他们其实是相等的 -- 所以 2 - 1 = 1,最后该语句只映射为一个MapReduce执行 SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1) -- 第一个mapreduce作业将a与b联接在一起, -- 第二个mapreduce作业将上面的结果再与c联接到一起 SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) -
同一查询中连接2个以上的表时,将大表放在最后或者使用
streamtable关键字指定最后流式加载哪个表。-- 计算涉及两个MR作业。其中的第一个将a与b连接起来,并缓冲a的值,同时在reducer中流式传输b的值。 -- 第二个MR作业中,将缓冲第一个连接的结果,同时将c的值通过reducer流式传输。 SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) -- 等价于 select streamtable(c) a.val, b.val, c.val from a join b on (a.key = b.key1) join c on (c.key = b.key2) -
如果除一个要连接的表之外的所有表都很小,则可以将其作为仅map作业执行(mapjoin)。【后面再详细介绍】
SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a JOIN b ON a.key = b.key --不需要reducer。对于A的每个Mapper,B都会被完全读取。限制是不能执 行FULL / RIGHT OUTER JOIN b -
关于null


















 3026
3026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











