







概述
本篇博客是描述生产环境出现的问题,以及解决问题时的整个过程。
场景
生成环境出现CPU占用为98%的情况,当时那段时间也有相应的定时任务在运行。
定位问题
发现CPU占用为98%的情况后,当时,首先想的是到底是那个点,或者那块代码导致的这个问题啊,于是先查看了占用CPU较高的进程ID,查询进程ID后,再查看该进程下CPU占用较高的线程ID,然后,打印出相应线程的堆栈信息,具体操作如下
1、查看CPU占用较高的进程ID
通过top命令,查看所有进程的CPU占用情况,如果知道是某个程序导致的CPU占用高的话,可以通过 ps -ef | grep '程序名称'查看相应的进程ID,如果,当前用户只启动了一个java程序,可以通过jps命令查看。获得进程ID的方式有很多,当时的操作是通过top命令获得。
2、查看进程ID下CPU占用较高的线程
可以通过top -H -p PID查看对应进程的哪个线程CPU占用过高,也可以通过ps -mp PID -o THREAD,tid,time | sort -rn查看。
3、获得线程ID的堆栈信息
首先需要将线程ID转换为16进程格式,具体可用printf "%x\n" TID,获得相应的值后,可通过如下命令打印线程的堆栈信息,jstack PID | grep TID -A 30,也可以写入到相应的文件中,jstack PID | grep TID -A 30 > temp.txt。也可以打印出进程ID下所有线程的堆栈信息,jstack PID > temp.txt。当时是打印出相应线程的堆栈,详细信息如下图
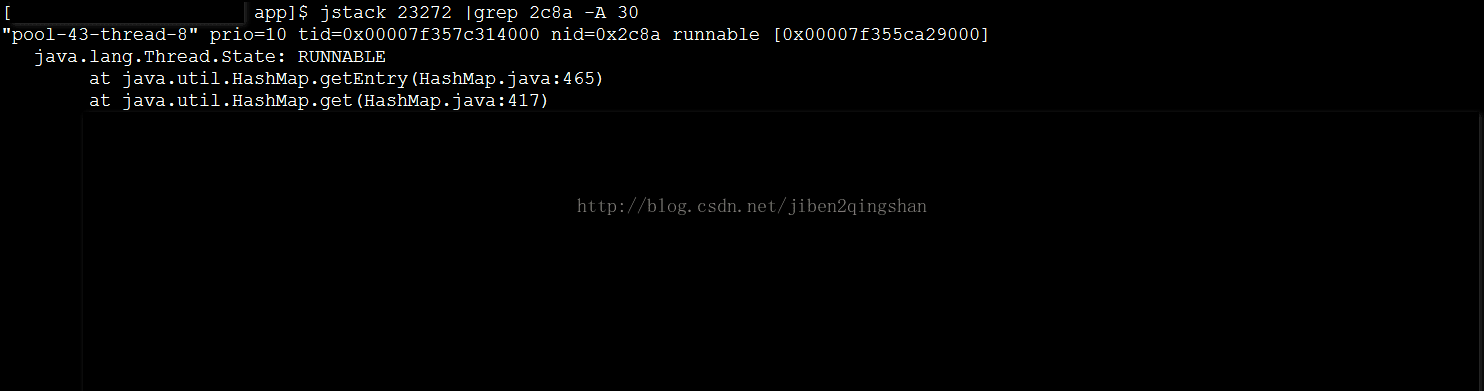
具体原因
从上图中可以定位到是那个类,那段代码的问题,于是就看那段代码,发现定义了一个静态的局部变量HashMap对象,而那段操作HashMap对象的代码,又是被多个线程同时操作,于是就网上搜了一下关于并发操作HashMap的后果的文章,结合JDK的源码,找到了原因,即,多并发操作HashMap会导致获取数据时死循环,下面解释为什么会出现死循环。
HashMap的put方法具体实现代码如下:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果该key已经被插入,则替换掉旧的value
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//该key不存在,需要增加一个结点
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看当前的size是否超过了我们设定的阀值threshold,如果超过,需要resize操作
if (size++ >= threshold)
resize(2 * table.length);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//创建一个新的Entry数组
Entry[] newTable = new Entry[newCapacity];
//将Old Entry[]的数据迁移到New Entry[]上
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
//从Old Entry[]里摘一个元素出来,然后放到new Entry[]中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}原来HashMap的数组是2,当里面再进行存放第三个元素时,就会发生rehash,此时原HashMap如下图

单线程进行rehash时,不会出现什么问题,会得到如下图所示的结果
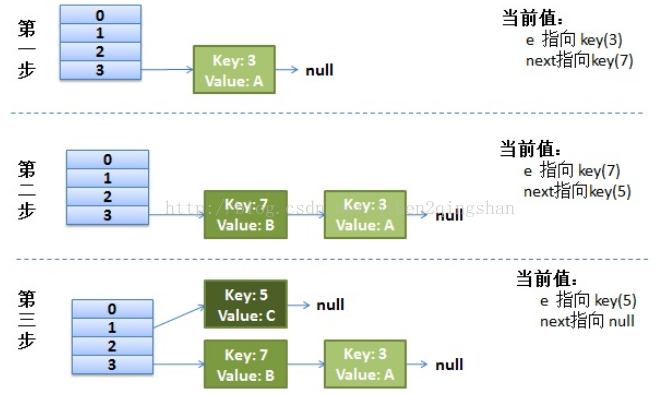
多个线程进行rehash时,就会出现环形链接或丢失数据(可自己分析)的情况,下面以两个线程同时进行rehash时,出现环形链接现象的解释。
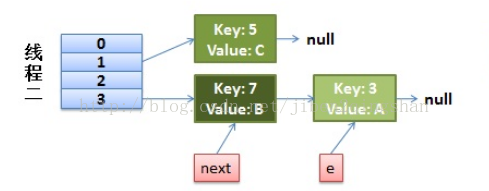
线程一先执行,处理第一个元素key=3时,transfer方法执行到如下图中代码行时,线程被调度挂起来了,此时,线程一中,next指向的是key=7,e指向的是key=3。

线程二的rehash完成,此时Entry和Entry关系如下图,因为Entry和Entry之间的关系考的是引用维系的,所以,此时,线程二修改Entry和Entry之间的关系,其实,也作用与线程一看到Entry和Entry的关系。
线程二完成rehash后,线程一被调度回来执行,当线程一完成第一次循环后,结果如下图:
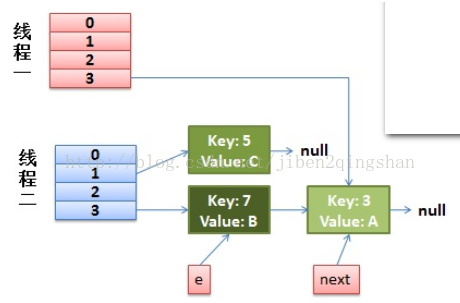
线程一进入第二次循环时,此时的e指向的是key=7的entry,而此时的key=7的next指向的是key=3,所以,第二次完成后的结果如下图
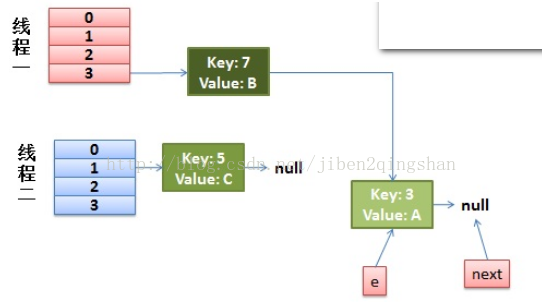
线程一进行第三次循环时,此时的e指向的是key=3的entry,而此时的key=3的next指向的是null(没有第四次循环了),所以,第三次完成后的结果如下图
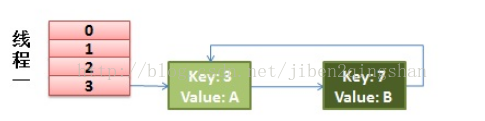
最终HashMap会指向线程一的Entry[],此时,如果我们get一个值时,并且这个值正好在下标为3的元素中,并且,这个值不存在在HashMap中,此时,就会在key=3和key=7之间不停的循环,get的源码如下
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//如果HashMap中没有这个值,并且,下标指向了3,并且3下标里面有环形链接,那么就会出现死循环
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}解决问题
找到问题的原因后,解决就比较简单了,可以使用线程安全的CurrentHashMap,也可以HashMap加锁,也可以换成每个线程单独一个HashMap对象,也可以换成其他的数据对象进行存取。
总结
定位问题时,查看代码发现使用了静态的HashMap对象,但是,当时并不认为是这个造成CPU过高,也就认为是正常业务的原因造成的CPU过高,没有再查(当时CPU也有往下降),等业务运行完成后,发现CPU换是那么高,才在网上继续搜,最终找到了原因,解决了问题。
在这里需要反思,因为当时查到问题指向HashMap的get上时,自己却凭已有的认知说不可能发生这样的情况,于是推测CPU过高是业务正常运行造成的,真的是不该啊。当问题指向我们认为不该发生的点时,请一定要正式它,重视它,千万不要一口否决,不去重新认识它,因为,可能是我们的疏忽或对它认识的不全面,而导致我们现认为它不会带来这个问题。
注:本文中出现的图片来自网上,本人仅做了微小调整。

















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









