







需要源码或觉得有帮助请点赞关注收藏后评论区留下QQ邮箱或者私信博主
与基于状态值函数的策略迭代不同,基于动作值函数的策略迭代是在当前策略下用另一个式子进行评估。
关于条件描述和环境搭建可以参考我这篇博客扫地机器人简介
算法步骤如下

下面通过基于动作值函数的策略迭代算法应用于确定环境的扫地机器人任务中,经过多轮迭代后,得到下图中动作值函数和策略迭代的更新过程
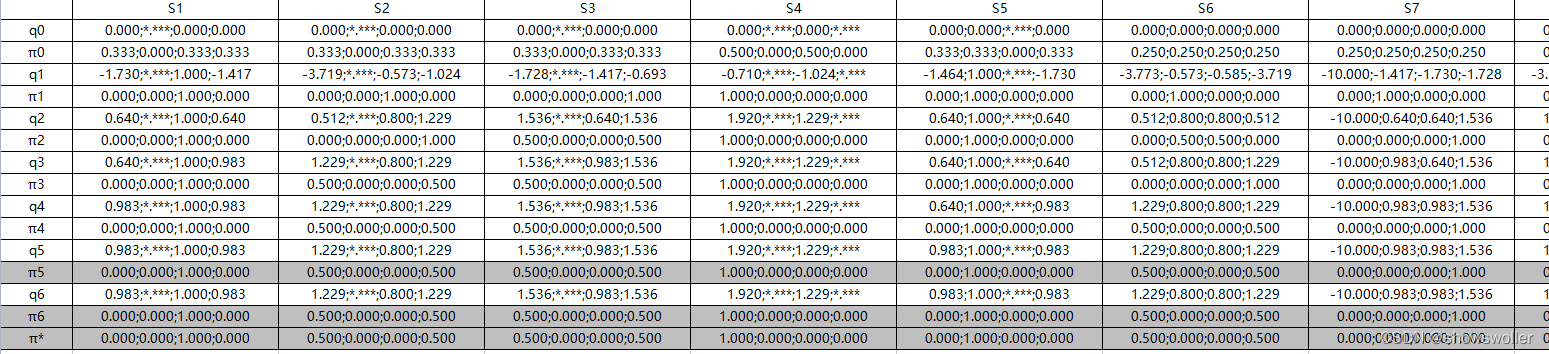
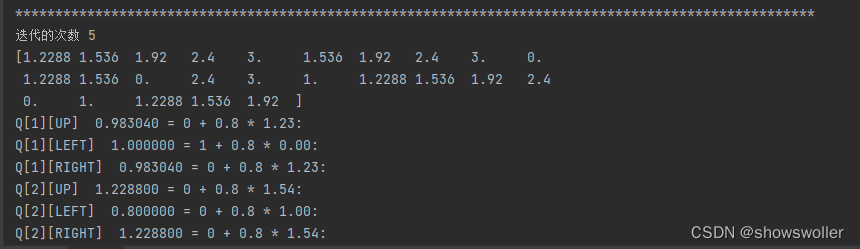
代码运行结果如下 经过五次迭代逐渐收敛
部分代码如下
# 代11-例4.7-基于动作值函数的确定环境扫地机器人任务策略迭代
import numpy as np
world_h = 5
world_w = 5
length = world_h * world_w
gamma = 0.8
state = [i for i in range(length)] # 状态(编号)
action = ['n', 's', 'w', 'e'] # 动作名称
ds_action = {'n': -world_w, 'e': 1, 's': world_w, 'w': -1}
value = [0 for i in range(length)] # 初始化状态值函数,均为0. [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
policy = np.zeros([length, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











