







流数据和流计算
在大数据时代,数据可以分为静态数据和流数据,静态数据是指在很长一段时间内不会变化,一般不随运行而变化的数据。流数据是一组顺序、大量、快速、连续到达的数据序列,一般情况下数据流可被视为一个随时间延续而无限增长的动态数据集合。应用于网络监控、传感器网络、航空航天、气象测控和金融服务等领域
但是,在大数据时代,不仅数据格式复杂、来源众多,而且数据量巨大,这就对实时计算提出了很大的挑战。因此,针对流数据的实时计算——流计算,应运而生。
一般的来说,流计算秉承一个基本理念,即数据的价值随着时间的流逝而降低。因此,当事件出现时就应该立即进行处理,而不是缓存起来进行批量处理。为了及时处理流数据,就需要一个低延迟、可扩展、高可靠的处理引擎。
对于一个流计算系统来说,它应达到如下需求。
高性能。处理大数据的基本要求,如每秒处理几十万条数据。
海量式。支持TB级甚至是PB级的数据规模。
实时性。必须保证一个较低的延迟时间,达到秒级别,甚至是毫秒级别。
分布式。支持大数据的基本架构,必须能够平滑扩展。
易用性。能够快速进行开发和部署。
可靠性。能可靠地处理流数据
流计算处理过程包括数据实时采集、数据实时计算和实时查询服务

常用的实时计算框架
1. Apache Spark Streaming
Apache公司开源的实时计算框架。Apache Spark Streaming主要是把输入的数据按时间进行切分,切分的数据块并行计算处理,处理的速度可以达到秒级别。
2. Apache Storm
Apache公司开源的实时计算框架,它具有简单、高效、可靠地实时处理海量数据,处理数据的速度达到毫秒级别,并将处理后的结果数据保存到持久化介质中(如数据库、HDFS)。
3. Apache Flink
Apache公司开源的实时计算框架。Apache Spark Streaming主要是把输入的数据按时间进行切分,切分的数据块并行计算处理,处理的速度可以达到秒级别。
4. Yahoo!S4
Yahoo公司开源的实时计算平台。Yahoo!S4是通用的、分布式的、可扩展的,并且还具有容错和可插拔能力,供开发者轻松地处理源源不断产生的数据。
Spark Streaming简介
SparkStreaming是构建在Spark上的实时计算框架,且是对Spark Core API的一个扩展,它能够实现对流数据进行实时处理,并具有很好的可扩展性、高吞吐量和容错性。Spark Streaming具有易用性、容错性及易整合性的显著特点。
Spark Streaming可整合多种输入数据源,如Kafka、Flume、HDFS,甚至是普通的TCP套接字。经处理后的数据可存储至文件系统、数据库,或显示在仪表盘里。
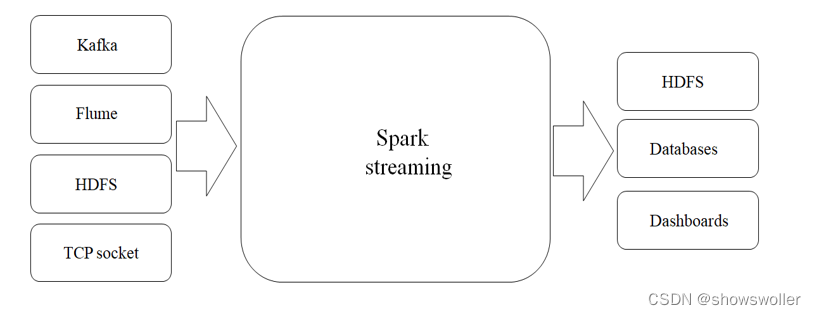
DStream简介
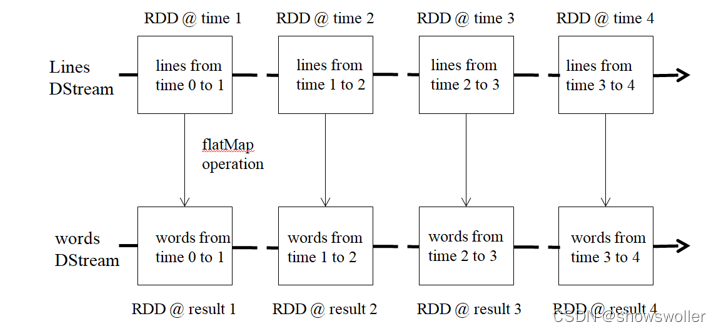
Spark Streaming提供了一个高级抽象的流,即DStream(离散流)。DStream表示连续的数据流,可以通过Kafka、Flume等数据源创建,也可以通过现有DStream的高级操作来创建。DStream的内部结构是由一系列连续的RDD组成,每个RDD都是一小段时间分隔开来的数据集。对DStream的任何操作,最终都会转变成对底层RDDs的操作。
例如,下图展示了进行单词统计时,每个时间片的数据(存储句子的RDD)经flatMap操作,生成了存储单词的RDD。整个流式计算可根据业务的需求对这些中间的结果进一步处理,或者存储到外部设备中
创作不易 觉得有帮助请点赞关注收藏~~~
















 1316
1316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











