







需要源码请点赞关注收藏后评论区留言私信~~~
基本思想
假如有另一个标注序列(代词 动词 名词 动词 动词),如何来评价哪个序列更合理呢?
条件随机场的做法是给两个序列“打分”,得分高的序列被认为是更合理的。既然要打分,那就要有“评价标准”,称为特征函数。例如,可以定义相邻两个词的词性的关系为一个特征函数,那么对于“语言 处理”来说,上文提到的两个序列分别标注为“名词 动词”和“动词 动词”。从语言学的知识可知,“动词”一般不与“动词”相邻,因此,对该特征函数来说,第一个标注序列可以得分,而后一个标注序列则不得分。
假如定义了很多这样的特征函数,那么就可以用这些特征函数的评分结果转化的概率值来衡量哪个标注序列更合理。
在条件随机场的应用中,特征函数需要用户自己定义。特征函数分为刻画相邻变量相互影响和变量自身影响两类。
不同的特征函数刻画的特征有不同的重要性,在条件随机场里是用特征函数的权重系数来刻画它们的重要性,因此,条件随机场学习的目标就是得到每个特征函数的合理权重系数。
一般条件随机场的计算很复杂,简化为线性链结构的条件随机场计算相对简单,在标注问题中有广泛的应用。
在所谓的线性链条件随机场(linear chain conditional random field)中,定义转移特征函数t和状态特征函数s用来刻画相邻变量相互影响和变量自身影响。
设观测序列为x=(x^(1),x^(2),…,x^(n)),待预测的标签序列为y=(y^(1),y^(2),…,y^(n)),也称为隐变量状态序列。假定x和y具有相同的结构。条件随机场学习的目标是从训练集中得到条件概率模型P(y|x)=P(y^(1),y^(2),…,y^(n)|x^(1),x^(2),…,x^(n))。
转移特征函数(transition feature function)用于刻画相邻标签变量之间的相关关系以及观测序列对它们的影响,对于观测序列x的第i个位置,转移特征函数t标记为:
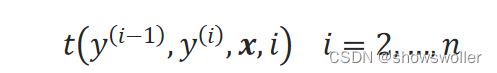
状态特征函数(status feature function)用于刻画观测序列对标签变量的影响,对于观测序列x的第i个位置,状态特征函数s标记为:
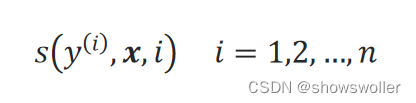

定义一个状态特征函数s:
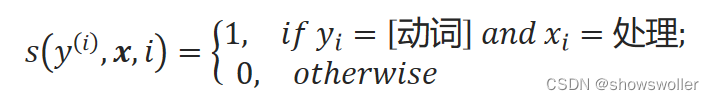
它表示在句子的第i个位置,当输入为“处理”时,如果对应的标签变量值为“动词”时,特征函数值为1,否则为0。
定义一个转移特征函数t:
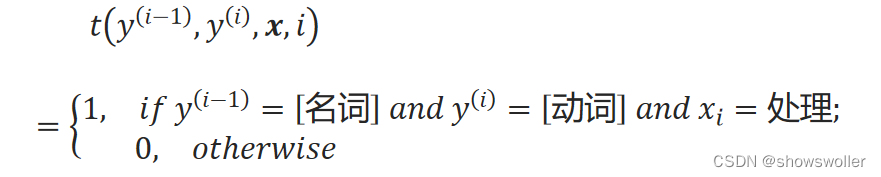
它表示在句子的第i个位置,当输入为“处理”时,如果对应的标签变量值为“动词”且前一个标签变量值为“名词”时,特征函数值为1,否则为0。
可以将条件概率模型P(y|x)写为: P(y|x)
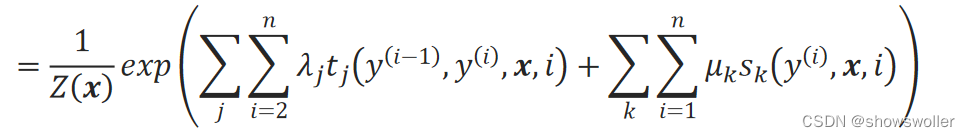
下标j表示转移特征函数的序号,λ_j表示该转移特征函数的权重系数,下标k表示状态特征函数的序号,μ_k表示该状态特征函数的权重系数,Z(x)是转化为概率的归一化因子:
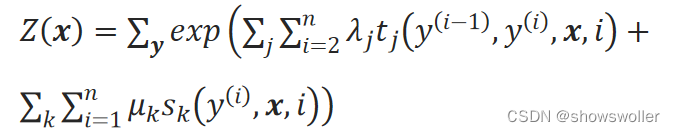
条件随机场的概率计算问题是给定条件随机场P(y|x),输入序列x和输出序列y,计算条件概率P(y^(i)|x),P(y^(i),y^(i+1)|x)以及相应的数学期望的问题。
学习问题是在给定训练集时,估计条件随机场模型的参数,即特征函数的权重系数。
预测问题是在给定条件随机场和观测序列的条件下,求条件概率最大的标注序列,即对观测序列进行标注。
中文分词应用示例
在实际应用中,特征函数的数量可能会很大,一般不是由用户逐个来定义,而是通过工具提供的模板来批量定义。
CRF++工具是一个简单、可定制、开源的条件随机场工具,可用于序列数据的标注任务,广泛应用于自然语言处理任务中。CRF++用C++语言实现,在Windows平台上,使用工具包中的crf_learn.exe、crf_test.exe、libcrfpp.dll三个文件即可完成模型的训练和预测。
在使用工具之前,要将训练语料和测试语句转换成符合CRF++要求的格式。

操作步骤如下
将crf_learn.exe、crf_test.exe、libcrfpp.dll文件拷贝到工作目录下,定义一个模板文件“template” 。
在控制台环境下,执行“crf_learn template crf_train_file crf_model”命令进行训练,得到模型文件“crf_model”。
在控制台环境下,执行“crf_test -m crf_model crf_test_file > crf_test_output”命令得到测试语句的输出文件“crf_test_output”。
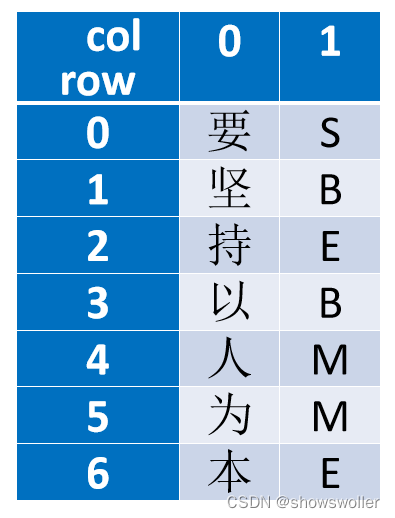
CRF++中的一元模板(Unigram template)的形式为:%x[row,col],其中row指定行的相对位置,col指定列的绝对位置。
示例用的模板文件内容如下:
# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
实际上,U02:%x[0,0]模板产生的特征函数类似于状态特征函数。func1、func2、func3将返回值0,func4将返回值1。特征函数的返回值会用于调整它们的权重系数。 对于转移特征函数,可以用U01:%x[-1,0]模板来产生。 CRF++用所谓的二元模板(Bigram template)扩展了条件随机场的传统特征函数。二元模板是在一元模板的基础上引入了前一个输出标签作为特征函数的元素,从而产生了能反映前后标签关系的特征函数。
输出结果如下 能非常精确的对输入句子进行分词
![]()
# 将训练语料改成crf++的格式,并写入文件crf_train_file
crf_train_file = "crf_train_file"
output_file = open(crf_train_file, 'w', encoding='utf-8')
for i in range(len(new_sents)):
for j in range(len(new_sents[i][0])):
output_file.write(new_sents[i][0][j] + ' ' + sents_labels[i][0][j] + '\n')
output_file.write('\n')
output_file.close()
# 将测试文本改成crf++的格式,并写入文件crf_test_file
crf_test_file = "crf_test_file"
output_file = open(crf_test_file, 'w', encoding='utf-8')
for i in range(len(test_str)):
output_file.write(test_str[i] + '\n')
output_file.close()
# 将测试语句的分词输出改写方便观看的格式。
crf_test_output = "crf_test_output"
input_file = open(crf_test_output, encoding='utf-8')
str = ""
for line in input_file.readlines():
line = line.split()
if len(line) == 2:
if line[1] == 'E' or line[1] == 'S':
str += line[0] + ' '
else:
str += line[0]
input_file.close()
print(str)创作不易 觉得有帮助请点赞关注收藏~~~
















 9807
9807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











