







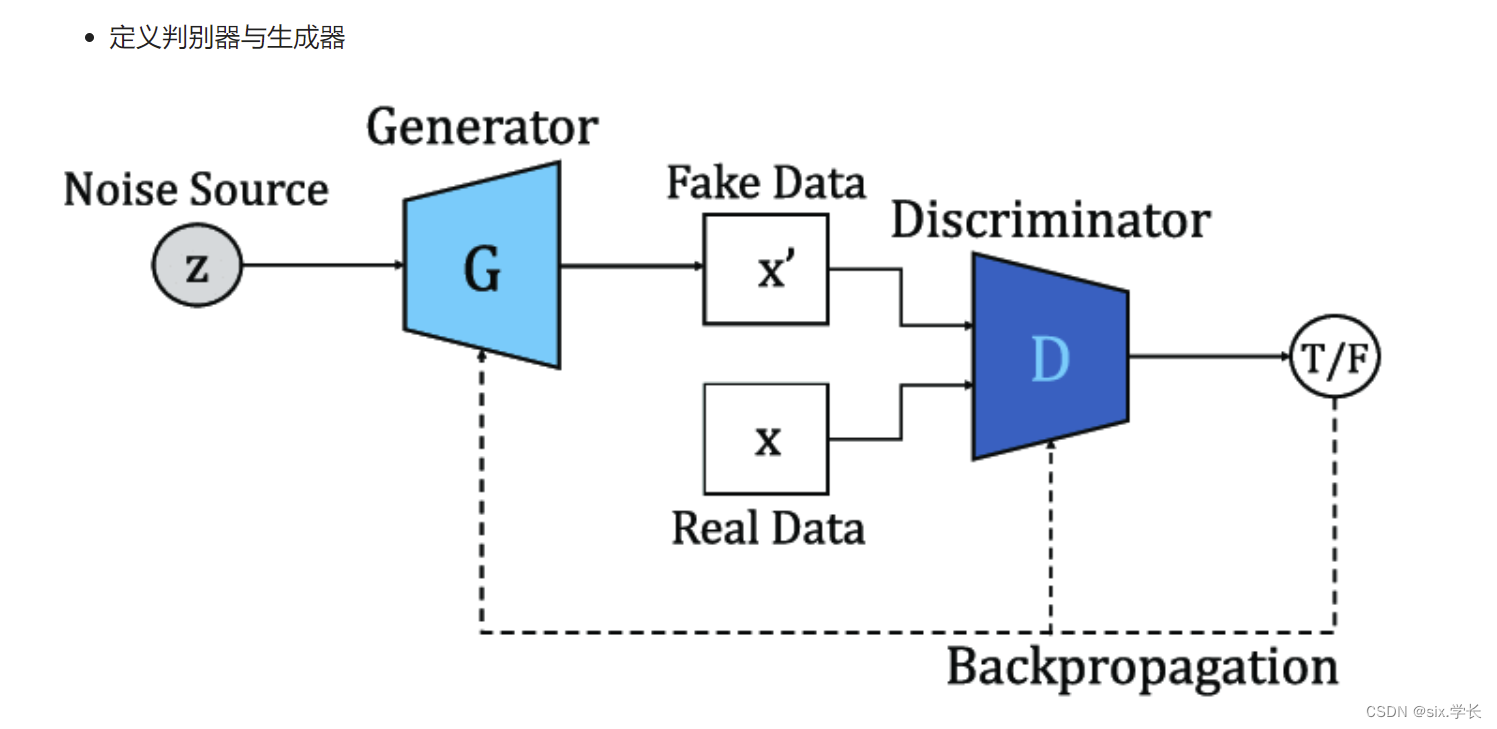
这张图片描述了生成对抗网络(GAN, Generative Adversarial Network)的结构和工作原理。让我们逐步详细解释图片中的内容。
1. GAN 的组成
GAN 由两个基础网络组成:
- 生成器(Generator,简写为 G):负责生成假数据。
- 判别器(Discriminator,简写为 D):负责判断数据是真实的(Real)还是生成的(Fake)。
2. 生成器(Generator)
生成器的输入是一个随机噪声(Noise Source),通常记为 z z z,它可以是高斯分布或均匀分布的随机数。生成器通过神经网络将这个随机噪声转换成假数据(Fake Data),记为 x ′ x' x′。生成器的目标是尽量生成看起来像真实数据的假数据,以欺骗判别器。
3. 判别器(Discriminator)
判别器的输入包括两部分:
- 假数据(Fake Data,记为 x ′ x' x′),来自生成器。
- 真实数据(Real Data,记为 x x x),来自真实世界的数据集。
判别器的任务是将输入的数据进行分类,输出一个概率值(记为 D ( x ) D(x) D(x)),表示输入数据为真实数据的概率。判别器通过最大化这个概率来训练自己,即识别出更多的真实数据,识别出生成器生成的假数据。
4. 训练过程
对抗训练
GAN 的训练是一个对抗过程:
- 生成器的目标:生成尽可能逼真的假数据,使判别器认为这些数据是真实的(即 D ( G ( z ) ) D(G(z)) D(G(z)) 接近 1)。
- 判别器的目标:正确地区分真实数据和生成数据(即对真实数据 D ( x ) D(x) D(x) 输出接近 1,对假数据 D ( G ( z ) ) D(G(z)) D(G(z)) 输出接近 0)。
通过这种对抗训练,生成器和判别器不断改进:
- 生成器变得越来越擅长生成逼真的假数据。
- 判别器变得越来越擅长区分真实数据和假数据。
误差反向传播(Backpropagation)
在训练过程中,误差通过反向传播算法在网络中传递:
- 判别器计算输出误差后,调整自身参数。
- 生成器通过判别器的反馈调整自身参数,以生成更逼真的数据。
5. 具体步骤
- 生成器生成假数据:输入随机噪声 z z z,生成假数据 x ′ x' x′。
- 判别器判断数据:输入真实数据 x x x 和假数据 x ′ x' x′,输出它们分别为真实数据的概率 D ( x ) D(x) D(x) 和 D ( x ′ ) D(x') D(x′)。
- 计算损失:
- 判别器损失: − log D ( x ) − log ( 1 − D ( G ( z ) ) ) -\log D(x) - \log(1 - D(G(z))) −logD(x)−log(1−D(G(z)))。
- 生成器损失: − log D ( G ( z ) ) -\log D(G(z)) −logD(G(z))。
- 更新参数:
- 判别器根据损失更新参数。
- 生成器根据损失更新参数。
总结
通过以上对抗训练过程,生成器和判别器不断相互优化,最终生成器能够生成高度逼真的假数据,而判别器能够准确地区分真实数据和假数据。
如果您有更多问题或者需要更详细的解释,请告诉我!















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









