









需要全部代码请点赞关注收藏后评论区留言私信~~~
长期依赖问题
以基本单元为基础构建的循环神经网络具备记忆性,虽然能够处理有关联的序列数据问题,但是因为梯度消散和爆炸问题的存在,不能有效利用间距过长的信息,效果有限,称之为长期依赖(Long-Term Dependencies)问题。长短时记忆网络是在普通循环神经网络基本单元的基础上,在隐层各单元间传递时通过几个可控门(遗忘门、输入门、候选门、输出门),控制之前信息和当前信息的记忆和遗忘程度,从而使循环神经网络具备了长期记忆功能,能够利用间距很长的信息来解决当前问题。
LSTM基本单元
RNN基本单元的状态s_i和输出y_i可表示为
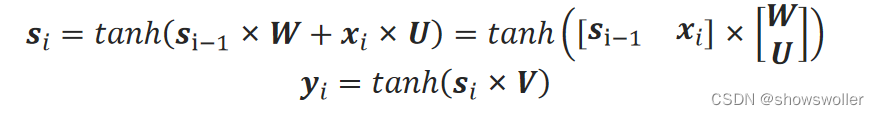
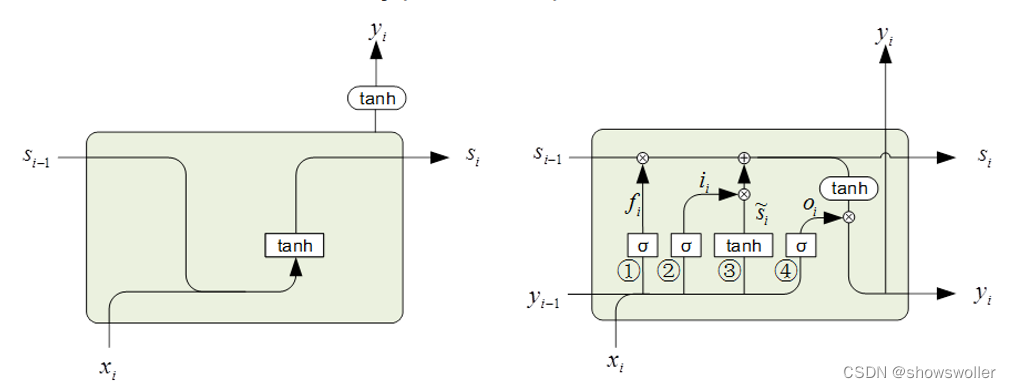
标记为①、②、③、④的分别称为遗忘门、输入门、候选门、输出门,σ表示Sigmoid激活函数,tanh表示tanh激活函数。
遗忘门用来控制上一步的状态s_i−1输入到本步的量,也就是遗忘上一步的状态的程度,它的输入是上一步的输出和本步的输入[■8(y_i−1&x_i)],它的输出为:
f_i=σ([■8(y_i−1&x_i)]∙W_f+b_f)
候选门通过tanh函数提供候选输入信息:
s ̃_i=tanℎ([■8(y_i−1&x_i)]∙W_s+b_s)
输入门通过Sigmoid函数来控制输入量:
in_i=σ([■8(y_i−1&x_i)]∙W_in+b_in)
为了进一步理解长短时记忆网络的单元结构,来计算一下它的参数个数。以示例为例,输入的x_i是1维的,输出y_i是100维的,单元状态s_i为100维,W_f、W_s、W_in和W_o是101×100的矩阵,b_f、b_s、b_in和b_o是100维的向量,因此,单元的参数个数为40800。
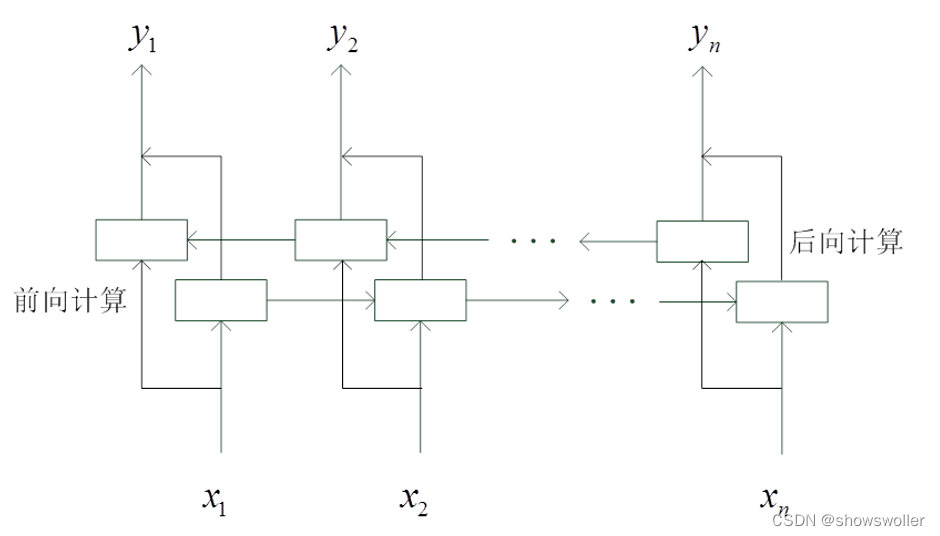
双向循环神经网络
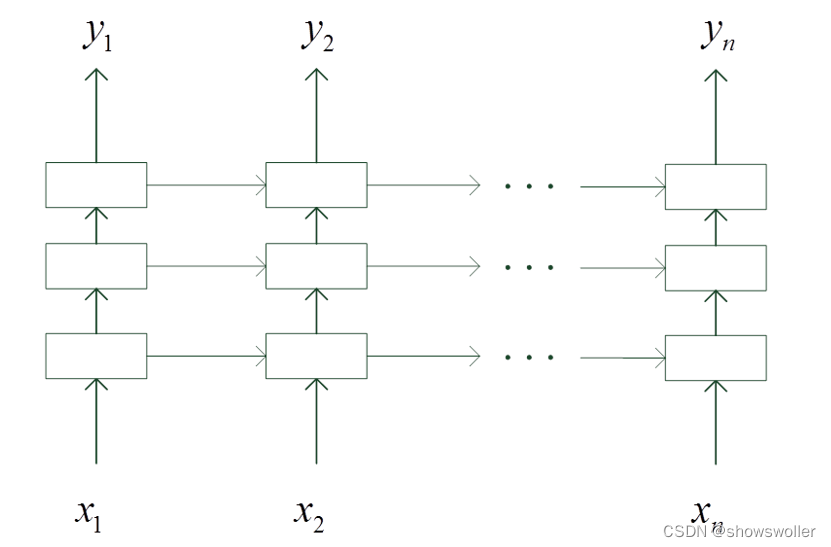
深度循环神经网络
中文分词应用示例
1)提取训练语料中的所有字,形成字典
该步的主要目的是给训练语料中用到的字进行编号
2)将语料中的句子转化为训练样本
模型对每个输入训练样本的长度要求一致,因此,可以指定一个固定长度,过长的句子应截断后面过长的部分。过短的句子在后面填充0,并指定一个新的标签“X”与之对应。通过字典将句子的汉字序列转换为数字序列。标签用独热编码表示。
3)搭建深度双向循环神经网络模型进行训练
4)利用训练好的模型进行分词
训练过程如下


先要将待分词的句子转换成适合模型输入的形式,再用模型进行分词。分词结果为:“中国 首次 火星 探测 任务 天问 一 号 探测器 实施 近 火 捕 获制动”。
部分代码如下
# 4.利用训练好的模型进行分词
def predict(testsent):
# 将汉字句子转换成模型需要的输入形式
x = [0] * maxlen
replace_len = len(testsent)
if len(testsent) > maxlen:
replace_len = maxlen
for j in range(replace_len):
x[j] = char2id[testsent[j]]
# 调用模型进行预测
label = model.predict([x])
# 根据模型预测结果对输入句子进行切分
label = np.array(label)[0]
s = ''
for i in range(len(testsent)):
tag = np.argmax(label[i])
if tag == 0 or tag == 3: # 单字和词结尾加空格切分
s += testsent[i] + ' '
elif tag ==1 or tag == 2:
s += testsent[i]
print(s)
# 2.将训练语句转化为训练样本
trainX = []
trainY = []
for i in range(len(new_sents)):
x = [0] * maxlen # 默认填充值
y = [4] * maxlen # 默认标签X
sent = new_sents[i][0]
labe = sents_labels[i][0]
replace_len = len(sent)
if len(sent) > maxlen:
replace_len = maxlen
for j in range(replace_len):
x[j] = char2id[sent[j]]
y[j] = tags[labe[j]]
trainX.append(x)
trainY.append(y)
trainX = np.array(trainX)
trainY = tf.keras.utils.to_categorical(trainY, 5)
print("训练样本准备完毕,训练样本共" + str(len(trainX)) + "句。")创作不易 觉得有帮助请点赞关注收藏~~~
















 413
413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











