







循环神经网络的来源是为了刻画 一个序列当前的输出与之前信息的关系。从网络结构上,循环神经网络会记忆之前的信息,并利用之前的信息影响后面结点的输出。即:循环神经网络的 隐藏层之间的结点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。其中双向循环神经网络
(Bidirectional RNN, Bi-RNN)和长短期记忆网络
(Long Short-Term Memory networks,LSTM)是常见的循环神经网络 。
1.为什么要使用循环神经网络
RNN背后的想法是利用顺序的信息。 在传统的神经网络中,我们假设所有输入(和输出)彼此独立。 如果你想预测句子中的下一个单词,你就要知道它前面有哪些单词,甚至要看到后面的单词才能够给出正确的答案。 RNN之所以称为循环,就是因为它们对序列的每个元素都会执行相同的任务,所有的输出都取决于先前的计算。 从另一个角度讲RNN的它是有“记忆”的,可以捕获到目前为止计算的信息。 理论上,RNN可以在任意长的序列中使用信息,但实际上它们仅限于回顾几个步骤。 循环神经网络的提出便是基于记忆模型的想法,期望网络能够记住前面出现的特征,并依据特征推断后面的结果,而且整体的网络结构不断循环,因为得名循环神经网络。
以下是RNN在NLP中的一些示例: 语言建模与生成文本
- 机器翻译:机器翻译类似于语言建模,我们的输入源语言中的一系列单词,通过模型的计算可以输出目标语言与之对应的内容。
- 语音识别:给定来自声波的声学信号的输入序列,我们可以预测一系列语音片段及其概率,并把语音转化成文字
- 生成图像描述:与卷积神经网络一起,RNN可以生成未标记图像的描述。
2.RNN的网络结构及原理
2.1 RNN
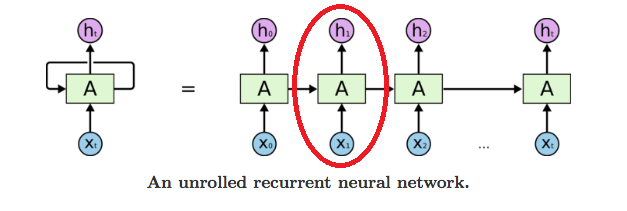
循环神经网络的基本结构特别简单,就是将网络的输出保存在一个记忆单元中,这个记忆单元和下一次的输入一起进入神经网络中。我们可以看到网络在输入的时候会联合记忆单元一起作为输入,网络不仅输出结果,还会将结果保存到记忆单元中,下图就是一个最简单的循环神经网络在输入时的结构示意图。
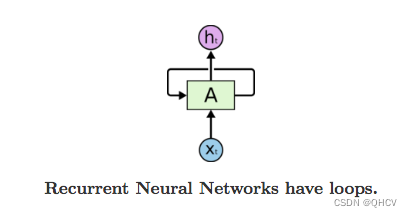
RNN 可以被看做是同一神经网络的多次赋值,每个神经网络模块会把消息传递给下一个,我们将这个图的结构展开 :
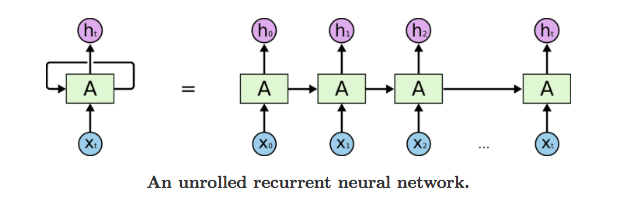
网络中具有循环结构,这也是循环神经网络名字的由来,同时根据循环神经网络的结构也可以看出它在处理序列类型的数据上具有天然的优势。因为网络本身就是 一个序列结构,这也是所有循环神经网络最本质的结构。
循环神经网络具有特别好的记忆特性,能够将记忆内容应用到当前情景下,但是网络的记忆能力并没有想象的那么有效。记忆最大的问题在于它有遗忘性,我们总是更加清楚地记得最近发生的事情而遗忘很久之前发生的事情,循环神经网络同样有这样的问题。
pytorch 中使用 nn.RNN 类来搭建基于序列的循环神经网络,它的构造函数有以下几个参数:
-
input_size:输入数据
X的特征值的数目。 -
hidden_size:隐藏层的神经元数量,也就是隐藏层的特征数量。
-
num_layers:循环神经网络的层数,默认值是 1。
-
bias:默认为 True,如果为 false 则表示神经元不使用
bias 偏移参数。 -
batch_first:如果设置为
True,则输入数据的维度中第一个维度就是 batch 值,默认为 False。默认情况下第一个维度是序列的长度, 第二个维度才是batch,第三个维度是特征数目。 -
dropout:如果不为空,则表示最后跟一个
dropout 层抛弃部分数据,抛弃数据的比例由该参数指定。
RNN 中最主要的参数是 input_size 和 hidden_size,其余的参数通常不用设置,采用默认值就可以了。
import torch
rnn = torch.nn.RNN(20, 50, 2)
input = torch.randn(100, 32, 20)
h_0 =torch.randn(2, 32 ,50)
output,hn=rnn(input, h_0)
print(output.size(), hn.size())
在实现之前,我们继续深入介绍一下RNN的工作机制,RNN其实也是一个普通的神经网络,只不过多了一个 hidden_state 来保存历史信息。这个hidden_state的作用就是为了保存以前的状态,我们常说RNN中保存的记忆状态信息,就是这个 hidden_state 。
对于RNN来说,我们只要己住一个公式:
h t = tanh ( W i h x t + b i h + W h h h ( t − 1 ) + b h h ) h_t = \tanh(W_{ih} x_t + b_{ih} + W_{hh} h_{(t-1)} + b_{hh}) ht=tanh(Wihxt+bih+Whhh(t−1)+bhh)
公式参考: https://pytorch.org/docs/stable/nn.html?highlight=rnn#torch.nn.RNN
下图演示了使用过程
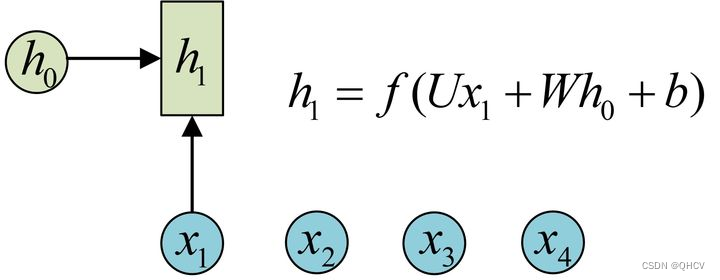
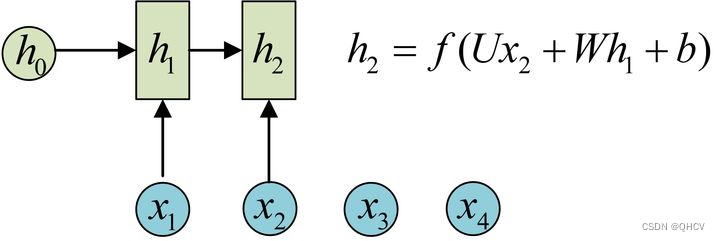
这个公式里面的
x
t
x_t
xt 是我们当前状态的输入值,
h
(
t
−
1
)
h_{(t-1)}
h(t−1) 就是上面说的要传入的上一个状态的hidden_state,也就是记忆部分。 整个网络要训练的部分就是
W
i
h
W_{ih}
Wih。 当前状态输入值的权重
W
h
h
W_{hh}
Whh 、hidden_state也就是上一个状态的权重还有这两个输入偏置值。这四个值加起来使用tanh进行激活,pytorch默认是使用tanh作为激活,也可以通过设置使用relu作为激活函数。
上面讲的步骤就是用红框圈出的一次计算的过程
这个步骤与普通的神经网络没有任何的区别,而 RNN 因为多了 序列(sequence) 这个维度,要使用同一个模型跑 n 次前向传播,这个n就是我们序列设置的个数。
下面我们开始手动实现我们的RNN:
class RNN(object):
def __init__(self,input_size,hidden_size):
super().__init__()
#因为最后的操作是相加 所以hidden要和output的shape一致
self.W_xh = torch.nn.Linear(input_size, hidden_size)
self.W_hh = torch.nn.Linear(hidden_size, hidden_size)
def __call__(self, x, hidden):
return self.step(x, hidden)
def step(self, x, hidden):
#前向传播的一步
h1 = self.W_hh(hidden)
w1 = self.W_xh(x)
out = torch.tanh(h1 + w1)
hidden = self.W_hh.weight
return out, hidden
#网络实例化
rnn = RNN(20, 50)
#随机化生成输入数据
input = torch.randn(32 , 20)
#随机初始状态h0
h_0 = torch.randn(32, 50)
#序列的长度,也就是x的个数
seq_len = input.shape[0]
#每个x依次进行计算
for i in range(seq_len):
output, hn = rnn(input[i, :], h_0)
#打印输出尺寸
print(output.size(), h_0.size())
#torch.Size([32, 50]) torch.Size([32, 50])
2.2 LSTM(长短时记忆网络)
LSTM 的网络结构是 1997 年由 Hochreiter 和 Schmidhuber 提出的,随后这种网络结构变得非常流行。 LSTM虽然只解决了短期依赖的问题,并且它通过刻意的设计来避免长期依赖问题,这样的做法在实际应用中被证明还是十分有效的,有很多人跟进相关的工作解决了很多实际的问题,所以现在LSTM 仍然被广泛地使用。

上面动画的具体计算细节:
标准的循环神经网络内部只有一个简单的层结构,而 LSTM 内部有 4 个层结构:
- 第一层是个忘记层:决定状态中丢弃什么信息
- 第二层
tanh层用来产生更新值的候选项,说明状态在某些维度上需要加强,在某些维度上需要减弱 - 第三层
sigmoid层(输入门层),它的输出值要乘到tanh层的输出上,起到一个缩放的作用,极端情况下sigmoid输出0说明相应维度上的状态不需要更新 - 最后一层决定输出什么,输出值跟状态有关。候选项中的哪些部分最终会被输出由一个
sigmoid层来决定。
pytorch 中使用 nn.LSTM 类来搭建基于序列的循环神经网络,他的参数基本与RNN类似。
lstm = torch.nn.LSTM(10, 20,2)
input = torch.randn(5, 3, 10)
h0 = torch.randn(2, 3, 20)
c0 = torch.randn(2, 3, 20)
output, hn = lstm(input, (h0, c0))
print(output.size(), hn[0].size(), hn[1].size())
#torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])
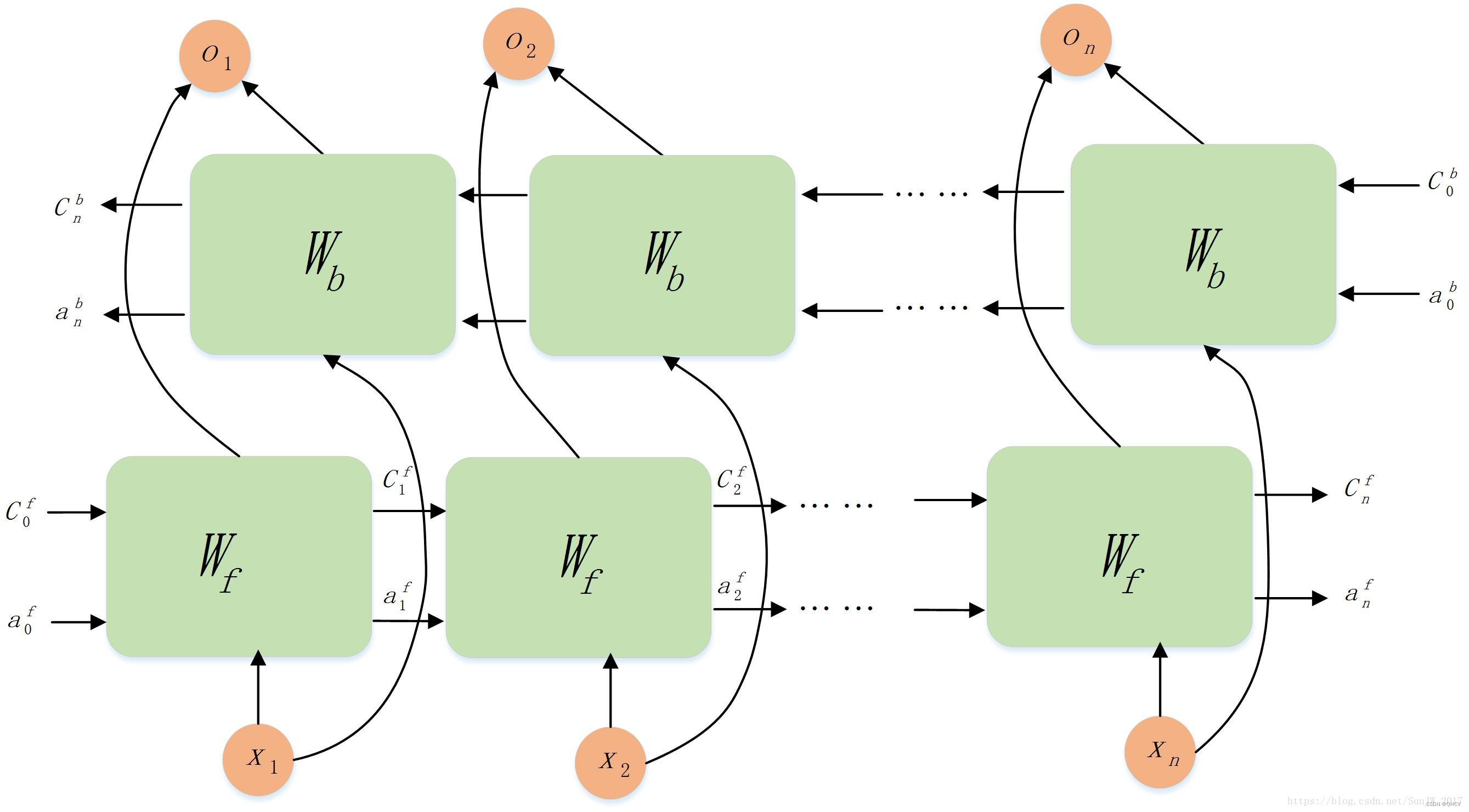
2.3 Bi-LSTM(双向长短时记忆网络)
Bi-LSTM考虑了上文信息和下文信息,其最终的输出的结果为正向的LSTM结果与反向LSTM结果的简单堆叠。
2.4 GRU(门控循环神经网络)
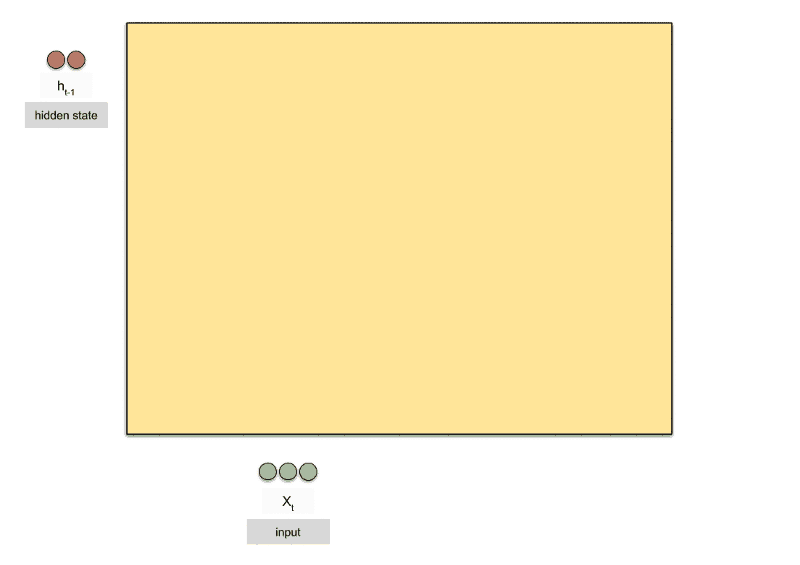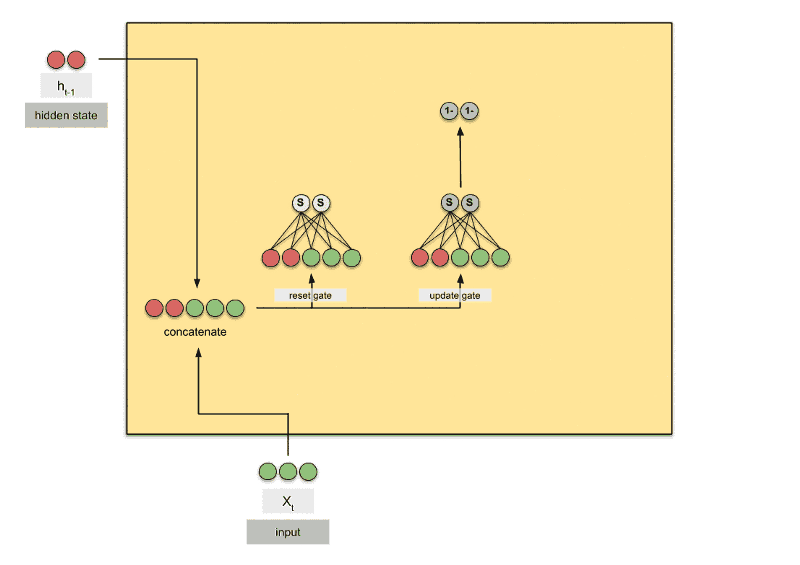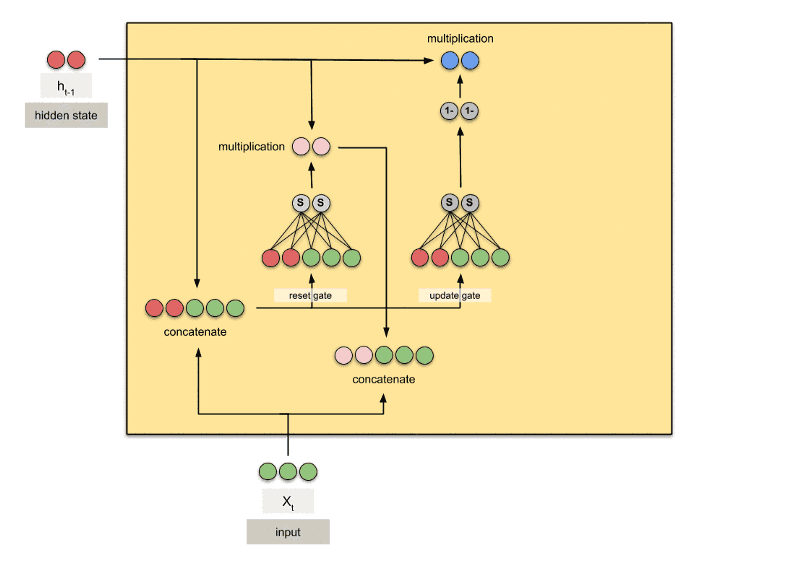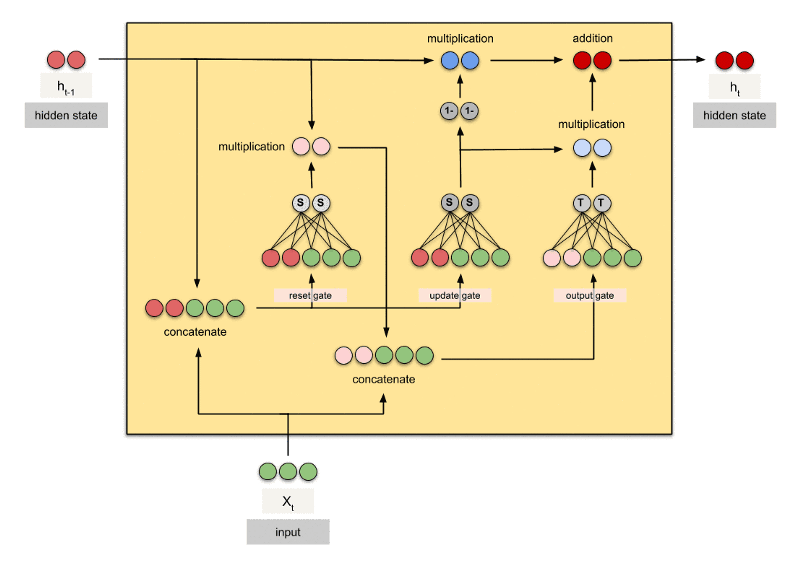
GRU 是gated recurrent units的缩写,由 Cho在 2014 年提出。GRU 和 LSTM 最大的不同在于 GRU 将遗忘门和输入门合成了一个"更新门",同时网络不再额外给出记忆状态,而是将输出结果作为记忆状态不断向后循环传递,网络的输人和输出都变得特别简单。所以GRU模型中只有两个门:分别是更新门和重置门。
rnn = torch.nn.GRU(10, 20, 2)
input = torch.randn(5, 3, 10)
h_0= torch.randn(2, 3, 20)
output, hn = rnn(input, h0)
print(output.size(),hn.size())
torch.Size([5, 3, 20]) torch.Size([2, 3, 20])
#torch.Size([5, 3, 20]) torch.Size([2, 3, 20])
相关练习代码:
https://pytorch.apachecn.org/#/docs/1.7/28
参考资料:
https://blog.csdn.net/fkyyly/article/details/82592963
https://towardsdatascience.com/animated-rnn-lstm-and-gru-ef124d06cf45
欢迎关注公众号【智能建造小硕】(分享计算机编程、人工智能、智能建造、日常学习、科研和写作经验等,欢迎大家关注交流。)
















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











