









需要源码请点赞关注收藏后评论区留言私信~~~
算法原理
层次聚类 (Hierarchical Clustering)就是按照某种方法进行层次分类,直到满足某种条件为止。层次聚类主要分成两类
凝聚:从下到上。首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有的对象都在一个簇中,或者满足某个终结条件
分裂:从上到下。首先将所有对象置于同一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终止条件
簇间距离度量
1. 最短距离法(最大相似度)
最短距离被定义为两个类中最靠近的两个对象间的距离为簇间距离
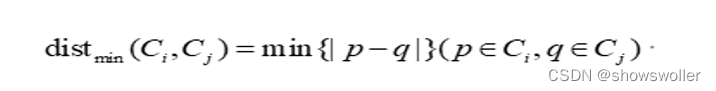
2.最长距离法(最小相似度)
最长距离被定义为两个类中最远的像个对象间的距离为簇间距离

3. 类平均法
计算两类中任意两个对象间的距离的平均值作为簇间距离
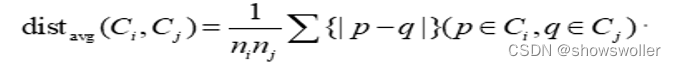
4. 中心法
定义两类的两个中心点的距离为簇间距离

分裂层次聚类DIANA
分裂的层次聚类方法使用自顶向下的策略把对象划分到层次结构中。从包含所有对象的簇开始,每一步分裂一个簇,直到仅剩单点簇或者满足用户指定的簇数为止
DIANA算法是典型的层次分裂聚类算法
DIANA算法中用到如下两个定义
簇的直径:计算一个簇中任意两个数据点之间的欧式距离,选取距离中的最大值作为簇的直径
平均相异度:两个数据点之间的平均距离
DIANA算法描述如下

凝聚层次聚类AGNES
凝聚的层次聚类方法使用自底向上的策略把对象组织到层次结构中。开始时以每个对象作为一个簇,每一步合并两个最相似的簇。AGNES算法是典型的凝聚层次聚类,起始将每个对象作为一个簇,然后根据合并准则逐步合并这些簇。两个簇间的相似度由这两个不同簇中距离最近的数据点的相似度确定。聚类的合并过程反复进行直到所有对象最终满足终止条件设置的簇数目
AGNES算法描述如下

层次聚类应用
Python中层次聚类的函数是A gglomerativeClustering(),最重要的参数有3个:n_clusters为聚类数目,affinity为样本距离定义,linkage是类间距离的定义,有3种取值
ward:组间距离等于两类对象之间的最小距离
average:组间距离等于两组对象之间的平均距离
complete:组间距离等于两组对象之间的最大距离
实战效果如下 可以看到明显的分为三个类

部分代码如下
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import AgglomerativeClustering
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle #python自带的迭代器模块
#产生随机数据的中心
centers = [[1, 1], [-1, -1], [1, -1]]
#产生的数据个数
n_samples = 3000
#生产数据
X, lablete = 0)
#设置分层聚类函数
linkages = ['ward', 'average', 'complete']
n_clusters_ = 3
ac = AgglomerativeClustering(linkage = linkages[2],n_clusters = n_clusters_)
#训练数据
ac.fit(X)
#每个数据的分类
lables = ac.labels_
plt.figure(1) #绘图
plt.clf()
colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')
for k, col in zip(range(n_clusters_), colors):
#根据lalables == k
#X[my_members, 0]取出my_members对应位置为True的值的横坐标
plt.plot(X[my_members, 0], X[my_members, 1], col + '.')
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()创作不易 觉得有帮助请点赞关注收藏~~~
















 4979
4979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











