









需要源码和数据集请点赞关注收藏后评论区留言私信~~~
1:折线图
折线图(line chart)是一种将数据点按照顺序连接起来的图形。可以看作是将散点图,按照x轴坐标顺序连接起来的图形
折线图的主要功能是查看因变量y随着自变量x改变的趋势,最适合用于显示随时间(根据常用比例设置)而变化的连续数据。同时还可以看出数量的差异,增长趋势的变化

plot函数
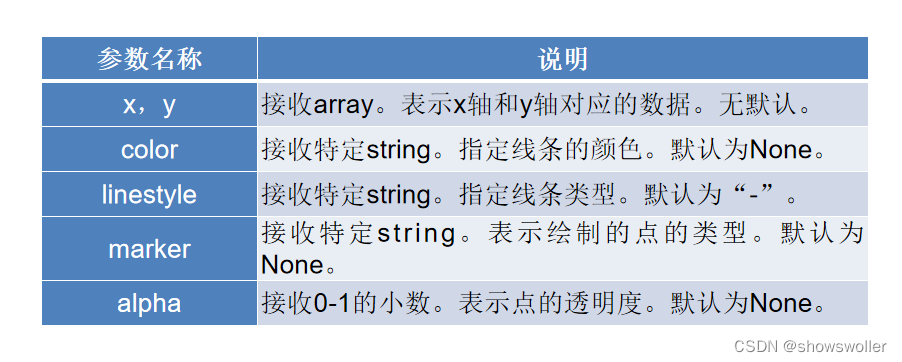
matplotlib.pyplot.plot(*args, **kwargs)
plot函数在官方文档的语法中只要求填入不定长参数,实际可以填入的主要参数主要如下
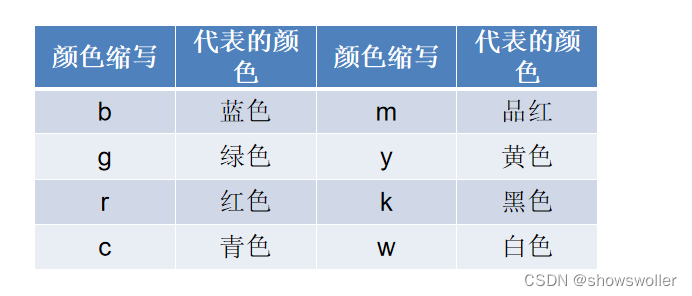
color参数的8种常用颜色的缩写
简单折线图绘制

x1 = np.arange(0, 30)
plt.plot(x1,x1*2, 'b')
plt.show()
带点的折线图

import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
x = np.arange(9)
y = np.sin(x)
z = np.cos(x)
# marker数据点样式,linewidth线宽,linestyle线型样式,
#color表示颜色
plt.plot(x, y, marker='*', linewidth=1, linestyle='--', color='orange')
plt.plot(x, z)
plt.title('matplotlib')
plt.xlabel('height',fontsize=15)
plt.ylabel('width',fontsize=15)
# 设置图例
plt.legend(['Y','Z'], loc='upper right')
plt.grid(True)
plt.show()
Series和DataFrame都有一个plot属性,用于绘制基本的图形。默认情况下,plot()绘制的都是折线
Series的索引传入作为绘图的X轴,x轴的刻度和范围可以通过xticks和xlim调整
2:散点图
散点图(scatter diagram)又称为散点分布图,是以一个特征为横坐标,另一个特征为纵坐标,利用坐标点(散点)的分布形态反映特征间的统计关系的一种图形
值是由点在图表中的位置表示,类别是由图表中的不同标记表示,通常用于比较跨类别的数据

scatter函数
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, alpha=None, **kwargs)

scatter绘图示例1

fig,ax = plt.subplots()
plt.rcParams['font.family'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x1 = np.arange(1,30)
y1 = np.sin(x1)
ax1 = plt.subplot(1,1,1)
plt.title('散点图')
plt.xlabel('X')
plt.ylabel('Y')
lvalue = x1
ax1.scatter(x1,y1,c = 'r',s = 100,linewidths = lvalue,marker = 'o')
plt.legend('x1')
plt.show() scatter绘图示例2

fig,ax=plt.subplots()
plt.rcParams['font.family']=['SimHei']#用来显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
for color in ['red','green','blue']:
n=500
x,y=np.random.randn(2,n)
ax.scatter(x,y,c=color,label=color,alpha=0.3,edgecolors='none')
ax.legend()
ax.grid(True)
plt.show()
3:直方图
直方图(Histogram)又称质量分布图,是统计报告图的一种,由一系列高度不等的纵向条纹或线段表示数据分布的情况,一般用横轴表示数据所属类别,纵轴表示数量或者占比
用直方图可以比较直观地看出产品质量特性的分布状态,便于判断其总体质量分布情况。直方图可以发现分布表无法发现的数据模式、样本的频率分布和总体的分布
bar函数
matplotlib.pyplot.bar(left,height,width = 0.8,bottom = None,hold = None,data = None,** kwargs )
常用参数及说明如下表所示

bar绘图示例1

fig,axes = plt.subplots(2,1)
data = pd.Series(np.random.randn(16),index = list('abcdefghijklmnop'))
data.plot.bar(ax = axes[0],color = 'k',alpha = 0.7) #垂直柱状图
data.plot.barh(ax = axes[1],color = 'k',alpha = 0.7) #alpha设置透明度
bar绘图示例2

fig,ax = plt.subplots()
plt.rcParams['font.family'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x = np.arange(1,6)
Y1 = np.random.uniform(1.5,1.0,5)
Y2 = np.random.uniform(1.5,1.0,5)
plt.bar(x,Y1,width = 0.35,facecolor = 'lightskyblue',edgecolor = 'white')
plt.bar(x+0.35,Y2,width = 0.35,facecolor = 'yellowgreen',edgecolor = 'white')
plt.show()
4:饼图
饼图(Pie Graph)是将各项的大小与各项总和的比例显示在一张“饼”中,以“饼”的大小来确定每一项的占比
饼图可以比较清楚地反映出部分与部分、部分与整体之间的比例关系,易于显示每组数据相对于总数的大小,而且显现方式直观
pie函数
matplotlib.pyplot.pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=None, radius=None, … )

pie绘图示例
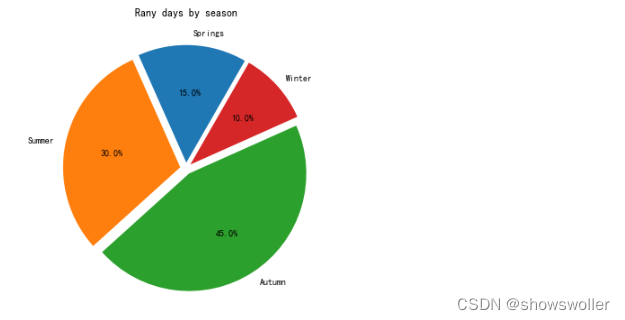
plt.figure(figsize = (6,6))
#建立轴的大小
labels = 'Springs','Summer','Autumn','Winter'
x = [15,30,45,10]
explode = (0.05,0.05,0.05,0.05)
#这个是控制分离的距离的,默认饼图不分离
plt.pie(x,labels = labels,explode = explode,startangle = 60,autopct = '%1.1f%%')
#qutopct在图中显示比例值,注意值的格式
plt.title('Rany days by season')
plt.tick_params(labelsize = 12)
plt.show()
5:箱线图
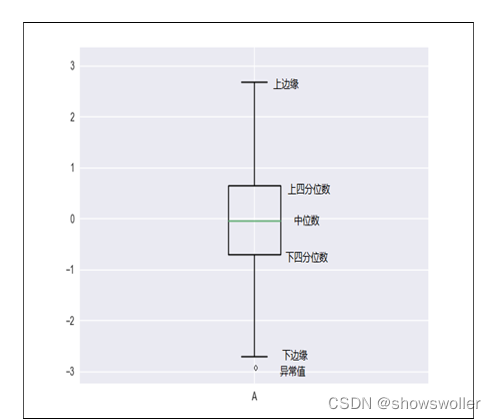
箱线图(boxplot)也称箱须图,其绘制需使用常用的统计量,能提供有关数据位置和分散情况的关键信息,尤其在比较不同特征时,更可表现其分散程度差异
箱线图利用数据中的五个统计量(最小值、下四分位数、中位数、上四分位数和最大值)来描述数据,它也可以粗略地看出数据是否具有对称性、分布的分散程度等信息,特别可以用于对几个样本的比较
boxplot函数
matplotlib.pyplot.boxplot(x, notch=None, sym=None, vert=None, whis=None, positions=None, widths=None, patch_artist=None,meanline=None, labels=None, … )

boxplot绘图示例

np.random.seed(2) #设置随机种子
df = pd.DataFrame(np.random.rand(5,4),
columns = ['A', 'B', 'C', 'D'])
#生成0-1之间的5*4维度数据并存入4列DataFrame中
df.boxplot() #也可用plot.box()
plt.show()
6:概率图
概率图模型是图灵奖获得者Pearl提出的用来表示变量间概率依赖关系的理论
正态分布又名高斯分布
正态概率密度函数 normpdf(X,mu,sigma) 其中,x为向量,mu为均值,sigma为标准差
绘制概率图

from scipy.stats import norm
fig,ax = plt.subplots()
plt.rcParams['font.family'] = ['SimHei']
np.random.seed(1587554)
mu = 100
sigma = 15
x = mu+sigma*np.random.randn(437)
num_bins = 50
n,bins,patches = ax.hist(x,num_bins,density = 1)
y=norm.pdf(bins,mu,sigma)
ax.plot(bins,y,'--')
fig.tight_layout()
plt.show()7:雷达图
雷达图也称为网络图,星图,蜘蛛网图,不规则多边形,极坐标图等。雷达图是以从同一点开始的轴上表示的三个或更多个定量变量的二维图表的形式显示多变量数据的图形方法。轴的相对位置和角度通常是无信息的。雷达图相当于平行坐标图,轴径向排列
绘制雷达图
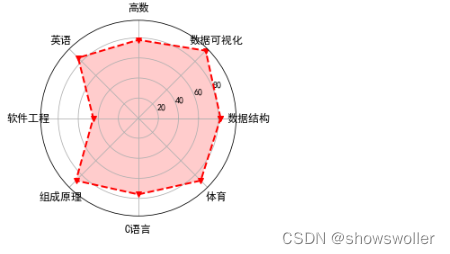
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
# 某学生的课程与成绩
courses = ['数据结构', '数据可视化', '高数', '英语', '软件工程', '组成原理', 'C语言', '体育']
scores = [82, 95, 78, 85, 45, 88, 76, 88]
dataLength = len(scores) # 数据长度
# angles数组把圆周等分为dataLength份
angles = np.linspace(0, 2*np.pi, dataLength, endpoint=False)
scores.append(scores[0])
angles = np.append(angles, angles[0]) # 闭合
# 绘制雷达图
plt.polar(angles, # 设置角度
scores, # 设置各角度上的数据
'rv--', # 设置颜色、线型和端点符号
linewidth=2) # 设置线宽
# 设置角度网格标签
plt.thetagrids(angles*180/np.pi, courses, fontproperties='simhei', fontsize=12)
# 填充雷达图内部
plt.fill(angles, scores, facecolor='r', alpha=0.2)
plt.show()8:流向图
在运输问题中,常常需要标明产地的产量、销地的销量,以及流向和流量的交通图,此时可以用到流向图。流向图能够能够直观地展示数据流向,揭示出运动中的一些规律或现象
流向图
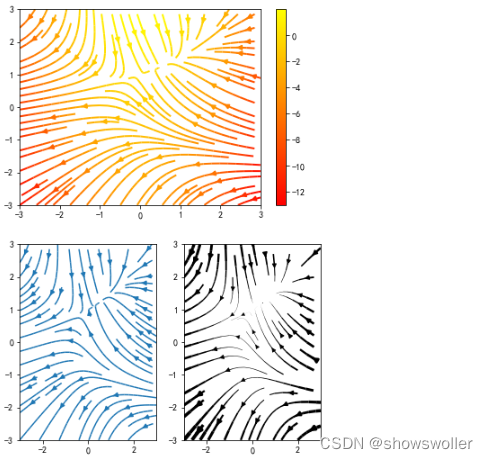
import numpy as np
import matplotlib.pyplot as plt
Y, X = np.mgrid[-3:3:100j, -3:3:100j]
U = -1 - X**2 + Y
V = 1 + X - Y**2
speed = np.sqrt(U*U + V*V)
plt.streamplot(X, Y, U, V, color=U, linewidth=2, cmap=plt.cm.autumn)
plt.colorbar()
f, (ax1, ax2) = plt.subplots(ncols=2)
ax1.streamplot(X, Y, U, V, density=[0.5, 1])
lw = 5*speed/speed.max()
ax2.streamplot(X, Y, U, V, density=0.6, color='k', linewidth=lw)
plt.show()9:带表格的绘图
在绘图中,有时候需要同时显示数据表格。Matplotlib在绘图中提供了table方法可以同时显示数据表格

import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['SimHei']
data = [[ 66386, 174296, 75131, 577908, 32015],
[ 58230, 381139, 78045, 99308, 160454],
[ 89135, 80552, 152558, 497981, 603535],
[ 78415, 81858, 150656, 193263, 69638],
[ 139361, 331509, 343164, 781380, 52269]]
columns = ('Freeze', 'Wind', 'Flood', 'Quake', 'Hail')
rows = ['%d year' % x for x in (100, 50, 20, 10, 5)]
values = np.arange(0, 2500, 500)
value_increment = 1000
colors = plt.cm.BuPu(np.linspace(0, 0.5, len(columns)))
n_rows = len(data)
index = np.arange(len(columns)) + 0.3
bar_width = 0.4
y_offset = np.array([0.0] * len(columns))
cell_text = []
for row in range(n_rows):
plt.bar(index, data[row], bar_width, bottom=y_offset)
y_offset = y_offset + data[row]
cell_text.append(['%1.1f' % (x/1000.0) for x in y_offset])
colors = colors[::-1]
cell_text.reverse()
the_table = plt.table(cellText=cell_text,
rowLabels=rows,
rowColours=colors,
colLabels=columns,
loc='bottom')
plt.subplots_adjust(left=0.2, bottom=0.2)
plt.ylabel("Loss in ${0}'s".format(value_increment))
plt.yticks(values * value_increment, ['%d' % val for val in values])
plt.xticks([])
plt.title('气象灾害损失')
plt.show()10:极坐标图
在极坐标投影中,需要以半径和角度的形式定位坐标,极坐标投影中的半径以圆半径的大小显示,并且以每个角度为0度的圆的角度作为起点投影角度,要生成极坐标投影,需要将投影类型定义为极坐标
极坐标图
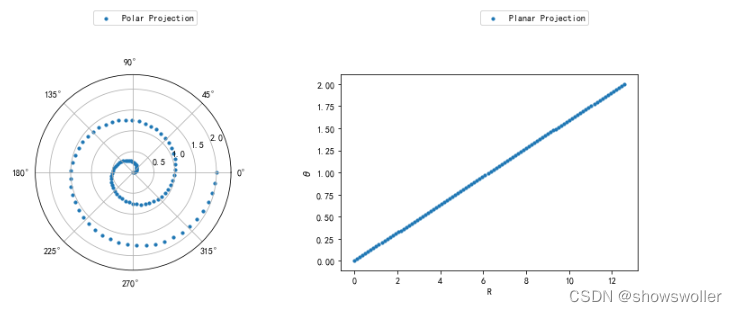
r = np.linspace(0, 2, 100)
theta = 2 * np.pi * r
fig = plt.figure(figsize=(13, 4))
ax1 = plt.subplot(121, projection='polar')
ax1.scatter(theta, r, label = 'Polar Projection', s = 10)
ax1.legend(bbox_to_anchor = (.85, 1.35))
ax2 = plt.subplot(122)
ax2.scatter(theta, r, label = 'Planar Projection', s = 10)
ax2.legend(bbox_to_anchor = (0.85, 1.35))
ax2.set_xlabel('R')
ax2.set_ylabel(r'$\theta$')11:词云图
词云用于对网络文本中出现频率较高的关键词予以视觉上的突出,形成关键词云层或者关键词渲染,从而过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨
一般生成词云的过程为:
(1)首先使用pandas读取数据并将需要分析的数据转化为列表;
(2)对获得的列表数据利用分词工具jieba进行遍历分词;
(3)使用WordCloud设置词云图片的属性、掩码和停用词,并 生成词云图像
生成词云

# import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud,STOPWORDS
import PIL.Image as image
import numpy as np
def get_wordList():
f = open("data//text.txt")
wordList = f.read()
return wordList
def get_wordClound(mylist):
pic_path = 'data//myimg.jpg'
img_mask = np.array(image.open(pic_path))
wordcloud = WordCloud(background_color="white",mask=img_mask).generate(mylist)
plt.imshow(wordcloud)
plt.axis("off")
wordList = get_wordList()
get_wordClound(wordList)
创作不易 觉得有帮助请点赞关注收藏~~~















 1673
1673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











