







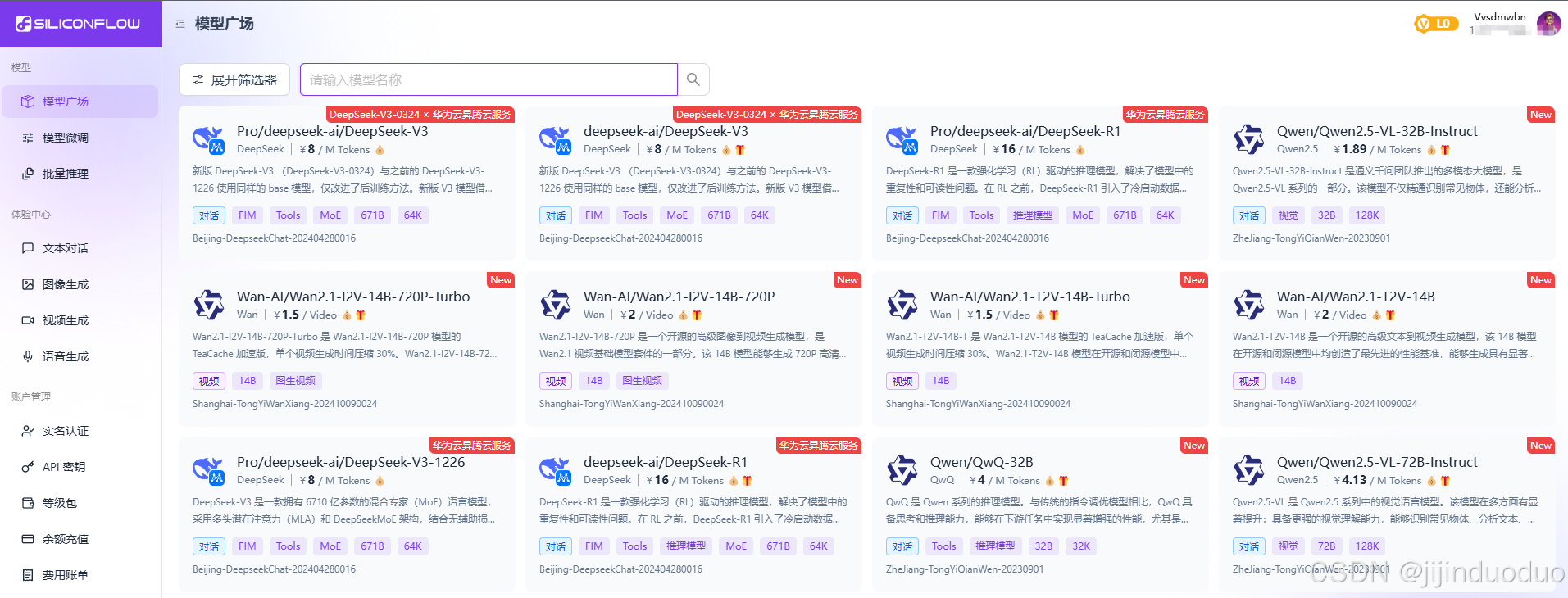
实测:经过本地化部署通过 Dify、AnythingLLM 、RAGFlow 测试知识库的客服等理解回答能力,QwQ-32B强于deepseek-r1:32B及其他32B以下模型,和硅基流动 免费的deepseek-r1满血版差不多的。推荐通义千问QwQ-32B。
硅基流动免费给的少但是没有时间限制。可以与阿里云互补(阿里没有腾讯系大模型)
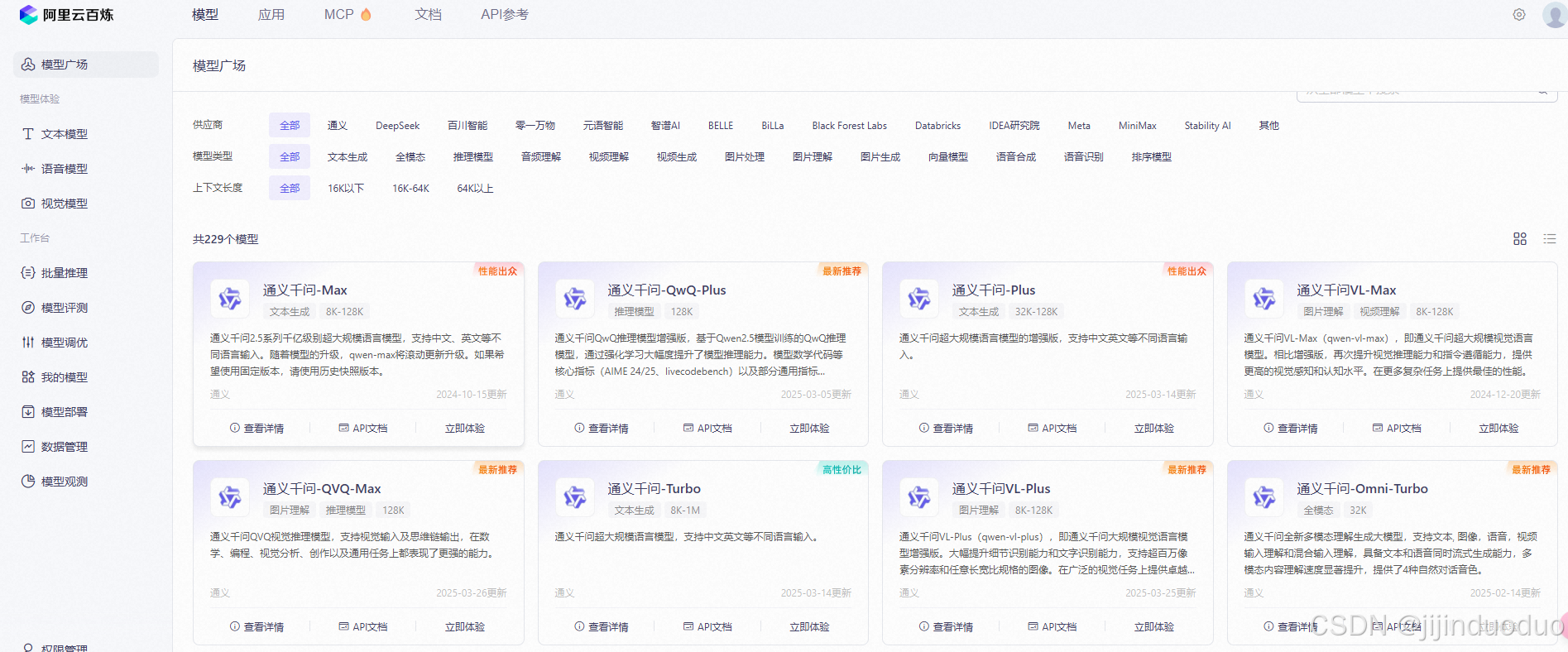
阿里云大模型服务平台目前6个月100 万 Tokens 测试。下面有详细教程。
通义千问推理模型QwQ-32B详细介绍
一、核心定位与技术突破
QwQ-32B是阿里巴巴于2025年3月6日开源的推理模型,其核心定位是以极简参数规模实现顶级性能,参数量仅320亿(32B),但通过强化学习与架构优化,性能可媲美6710亿参数的DeepSeek-R1,甚至在部分评测中超越后者。这一突破标志着大模型从“参数竞赛”向“效率与场景精度”范式的转变。

三大技术突破:
- 参数效率革命
通过动态稀疏激活技术,实际推理时激活参数仅占理论值的52%,计算效率提升3倍,存储体积缩减至65GB(DeepSeek-R1为671GB),支持消费级显卡(如RTX 4090)本地部署,显存需求仅需96G即可完整运行。 - 强化学习驱动的性能跃迁
基于冷启动预训练+任务结果反哺的闭环架构,结合动态奖励模型与规则验证双引擎,在数学推理(AIME24评测)和代码生成(LiveCodeBench)中达到与DeepSeek-R1相当的水平,部分指标(如BFCL工具调用测试)甚至超越。 - 智能体(Agent)集成
支持工具调用与环境反馈的动态推理,可进行多步骤批判性思考。例如,在代码生成场景中,模型能根据测试用例执行结果迭代优化代码逻辑,提升输出质量。
二、性能表现与评测结果
QwQ-32B在多项权威基准测试中表现亮眼:
- 数学推理:AIME24评测得分78%,超越DeepSeek-R1(未公开具体数值),接近o3-mini-high模型。
- 代码生成:LiveCodeBench评测中与DeepSeek-R1持平,显著优于同规模竞品(如o1-mini)。
- 通用能力:在Meta首席科学家杨立昆领衔的LiveBench、谷歌指令遵循评测IFEval、伯克利BFCL测试中,均超越DeepSeek-R1,尤其在工具调用准确率上优势明显。
三、部署与应用优势
- 低成本部署
- 支持消费级GPU(如RTX 4090、A10)部署,量化版本(QwQ-32B-GGUF)仅需单卡即可运行,部署成本仅为同类模型的1/10。
- 阿里云PAI平台提供一键部署服务,支持SGLang、vLLM等加速框架,显著降低开发者门槛。
- 多场景适配
- 教育领域:通过通义App提供解题辅助,80%用户反馈知识理解效率提升30%。
- 企业服务:支持制造业、医疗等领域的定制化方案,如小张的制造企业通过QwQ-32B提升50%生产效率。
- 个人开发者:Hugging Face与ModelScope平台开放下载,Apache 2.0协议允许商用与二次开发。
四、开源生态与行业影响
- 社区响应
开源仅6天即登顶Hugging Face模型热榜,成为全球开发者首选,衍生模型“阿里万相”迅速崛起。 - 产业链激活
推动国产芯片厂商(如壁仞科技)推出适配硬件,加速AI一体机普及,助力中国智造生态升级。 - 普惠AI战略
阿里云通过开源模型降低AI技术门槛,推动从企业级到个人用户的广泛落地,预计2026年全球AI模型市场规模将显著增长。
五、未来展望
QwQ-32B的发布标志着阿里在强化学习与轻量化模型结合路径上的成功探索。团队透露下一代QwQ-64B将采用“液态神经网络”架构,目标在保持32B参数规模下实现DeepSeek-R1 90%的推理能力,进一步突破参数与性能的平衡边界。
通义千问推理模型QwQ-32B免费使用
一、注册与账号准备
- 注册阿里云账号
- 访问阿里云官网,完成账号注册与实名认证(未实名用户需在账号中心补全信息)。
- 登录后搜索“大模型服务平台百炼”,进入服务页面。
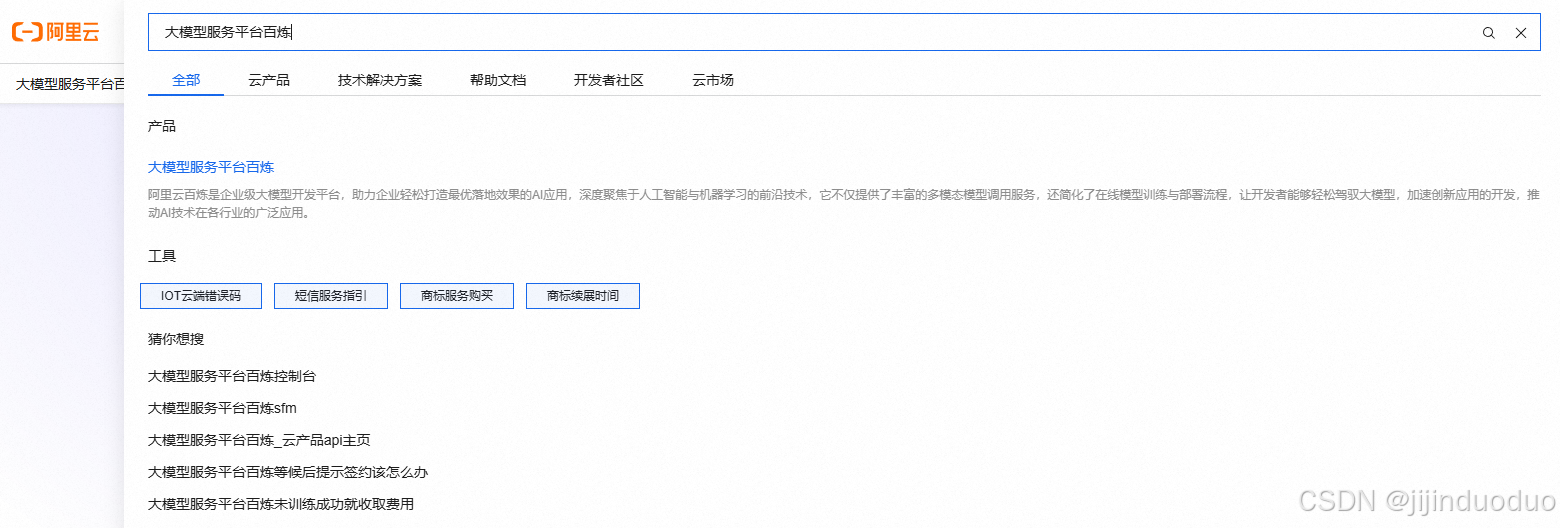

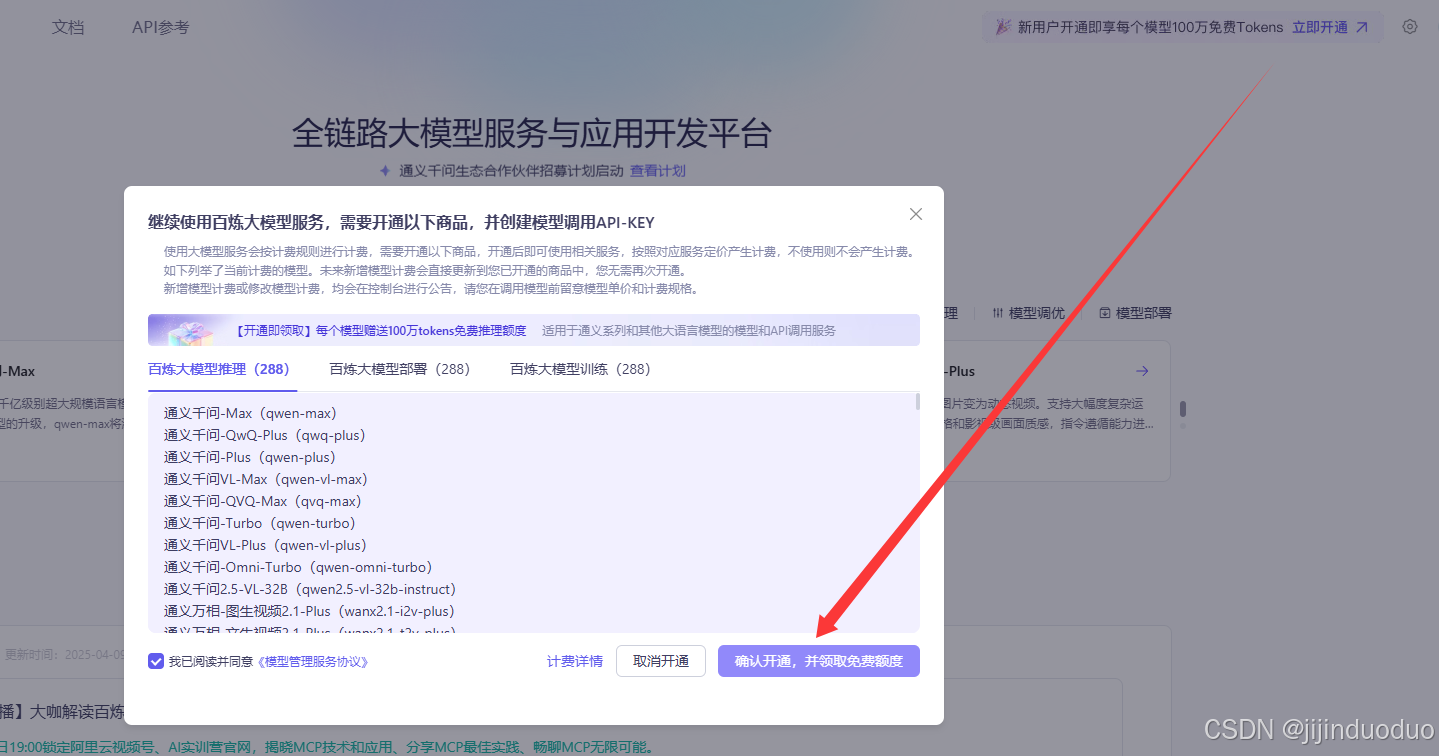
- 领取免费额度
- 在百炼平台点击“免费体验 → 同意服务协议 → 免费领取额度”,即可获得100万Tokens的免费调用额度(覆盖QwQ-32B等30+模型)。
二、API Key生成
- 创建API Key
- 进入百炼平台后台。模型底部→ 选择“API-KEY” → 创建并复制API Key(格式如
sk-xxx),此Key用于后续所有API调用。
- 进入百炼平台后台。模型底部→ 选择“API-KEY” → 创建并复制API Key(格式如
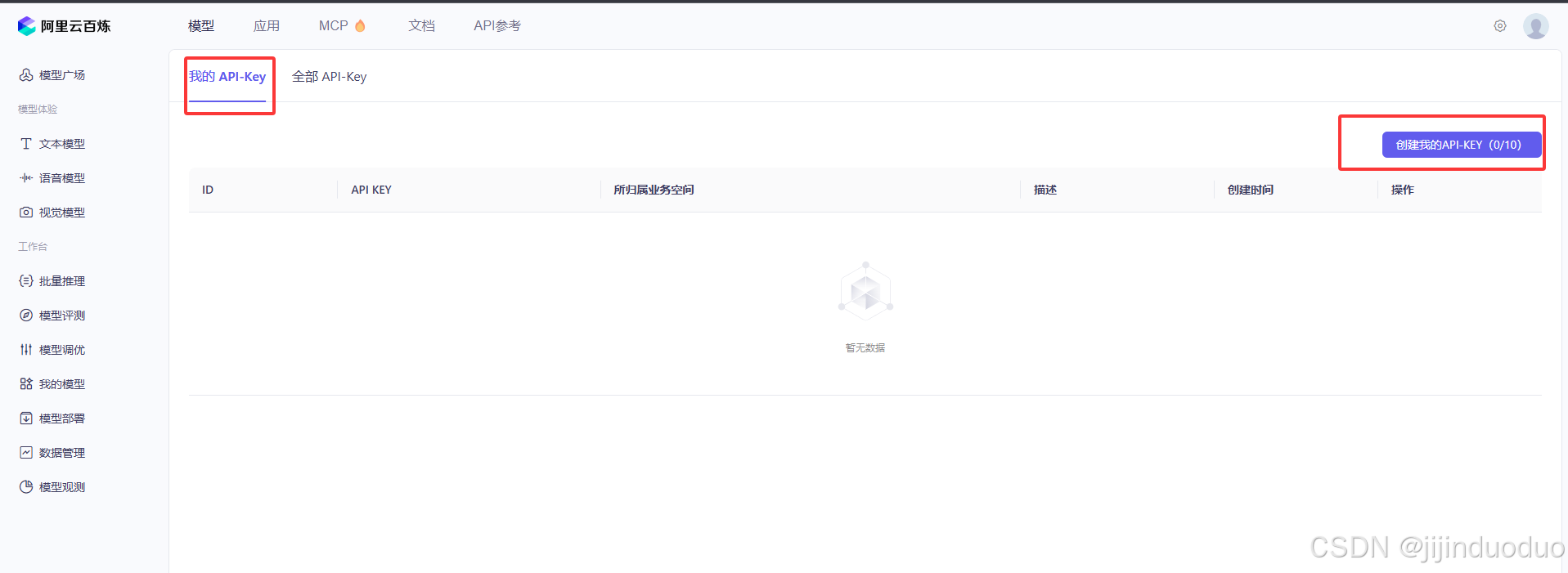
你可以在阿里云百炼的「模型广场」查看免费额度。如果领取时提示未实名,在阿里云主页右上角点击「账号中心」,进入「实名认证」页面,按引导完成个人认证就行。
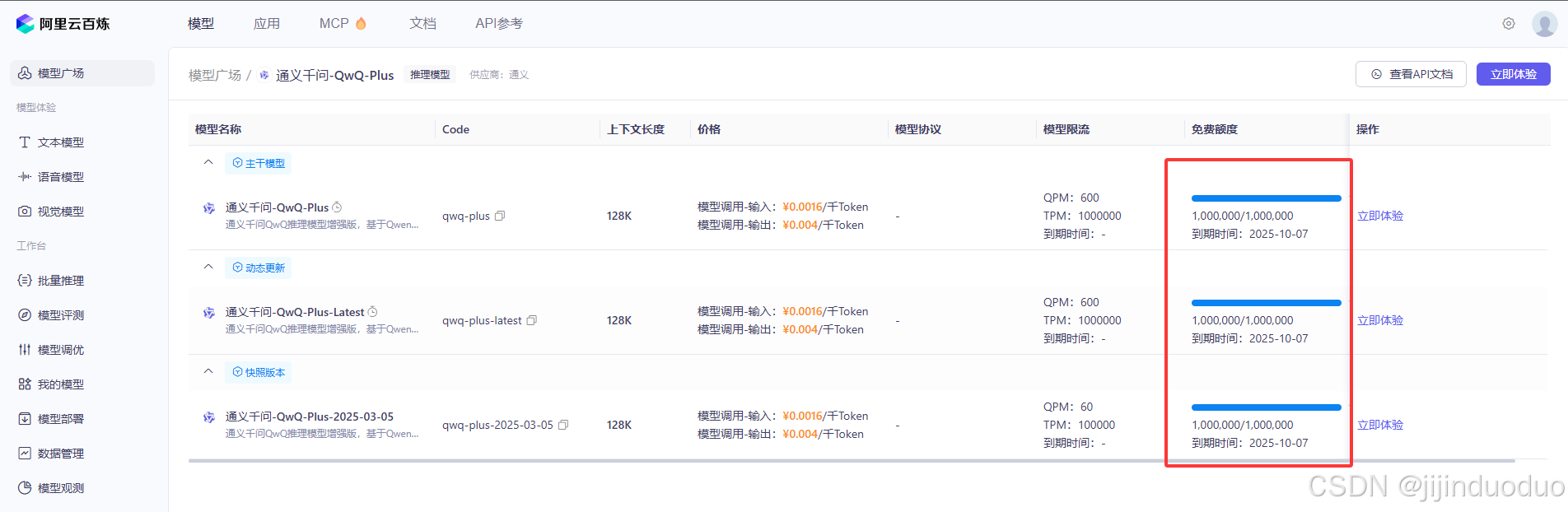

三、本地私有化模型部署与调用方式(可跳过)
方式1:Ollama 部署(推荐)
- 环境准备
- 硬件要求
- 显存:建议至少 24GB 显存(如 RTX 3090/4090),若使用量化版本(如
q4_K_M),最低需 16GB 显存。 - 存储空间:完整模型约 65GB,量化版本约 19-22GB。
- 操作系统:支持 Windows(需更新至最新补丁)、Linux、macOS。
- 显存:建议至少 24GB 显存(如 RTX 3090/4090),若使用量化版本(如
- 软件依赖
- 安装 Python 3.8+、Git 及常用包管理工具(如 pip)。
- 确保 CUDA 驱动与 PyTorch 版本兼容(如 CUDA 12.1 + PyTorch 2.3)。
- 硬件要求
- 部署ollama
- 安装 Ollama
- Windows/macOS:从 https://ollama.ai 下载安装包,按提示完成安装。
- Linux:
curl -fsSL https://ollama.com/install.sh | sh
- 配置环境变量(可选)
- 修改模型存储路径(如 Windows):
set OLLAMA_MODELS=D:\ollama\ # 自定义路径 - Linux/Unix 系统:
在~/.bashrc中添加export OLLAMA_MODELS=/path/to/models。
- 修改模型存储路径(如 Windows):
- 安装 Ollama
- 下载模型
- 下载 QwQ-32B 模型
ollama run qwq
- 注意事项:
- 若下载卡顿,按
Ctrl+D中断后重新运行ollama run qwq可加速。 - 模型下载路径默认为
~/.ollama/models(Linux/macOS)或C:\Users\<用户>\.ollama\(Windows)。
- 若下载卡顿,按
- 检查模型列表
ollama list # 确认模型已安装 - 启动模型服务
ollama serve # 后台运行,默认端口 11434 - 交互测试
输入问题(如ollama run qwq你是谁?)测试响应。
方式2:PAI-Model Gallery一键部署
- 进入PAI控制台
- 登录PAI控制台,选择支持QwQ-32B的地域(除北京外均可),进入对应工作空间。
- 部署模型
- 导航至“快速开始 → Model Gallery”,搜索并点击“QwQ-32B”模型卡片 → 选择部署框架(如vLLM、BladeLLM) → 配置资源(推荐4卡4090) → 点击“部署”。
- 获取服务信息
- 部署成功后,在服务详情页获取Endpoint(访问地址)和Token,用于API调用。
方式3:Docker手动部署(适合高级用户)
- 环境准备
- 确保GPU实例已安装Docker(检查命令:
sudo systemctl status docker)。
- 确保GPU实例已安装Docker(检查命令:
- 下载模型与启动服务
# 拉取推理镜像 sudo docker pull egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.7.2-sglang0.4.3.post2-pytorch2.5-cuda12.4-20250224 # 下载模型文件(约123GB) sudo docker run -d --rm -v /mnt/QwQ-32B:/data ... git-lfs clone https://modelscope.cn/models/Qwen/QwQ-32B.git /data # 启动服务(需挂载模型路径) sudo docker run -d --gpus all -v /mnt/QwQ-32B:/data ... vllm-server --model QwQ-32B --port 30000
四、API调用示例
请确保你已经安装了阿里云 Python SDK,可以使用以下命令进行安装:
pip install aliyun-python-sdk-core aliyun-python-sdk-qianwen-apiPython代码调用
import json
from aliyunsdkcore.client import AcsClient
from aliyunsdkcore.acs_exception.exceptions import ClientException
from aliyunsdkcore.acs_exception.exceptions import ServerException
from aliyunsdkqianwen_api.request.v20240216 import ChatRequest
# 配置阿里云访问凭证
access_key_id = 'your_access_key_id'
access_key_secret = 'your_access_key_secret'
region_id = 'cn-hangzhou'
# 创建 AcsClient 实例
client = AcsClient(access_key_id, access_key_secret, region_id)
def chat_with_qianwen(prompt):
# 创建 ChatRequest 请求
request = ChatRequest.ChatRequest()
request.set_accept_format('json')
# 构建请求体
request_body = {
"modelId": "QwQ-32B",
"messages": [
{
"role": "user",
"content": prompt
}
]
}
request.set_content(json.dumps(request_body))
try:
# 发起请求
response = client.do_action_with_exception(request)
response_json = json.loads(response)
# 提取模型回复内容
answer = response_json.get('result', {}).get('choices', [{}])[0].get('message', {}).get('content')
return answer
except ClientException as e:
print(f"ClientException: {e}")
except ServerException as e:
print(f"ServerException: {e}")
return None
# 示例调用
prompt = "你好,介绍一下自己"
answer = chat_with_qianwen(prompt)
if answer:
print("模型回复:", answer) 代码说明:
- 配置访问凭证:你需要将
your_access_key_id和your_access_key_secret替换为你自己的阿里云 AccessKey ID 和 AccessKey Secret。 - 创建请求:使用
ChatRequest创建一个请求对象,并设置请求体,指定模型 ID 和用户输入的提示信息。 - 发起请求:使用
client.do_action_with_exception方法发起请求,并处理可能的客户端和服务器异常。 - 提取回复:从响应中提取模型的回复内容并返回。


















 3702
3702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









