







Hive介绍
Hive是Facebook开源,用于解决海量结构化的日志数据统计问题;Hive是构建在Hadoop(HDFS/MapReduce/YARN)之上的数据仓库;Hive的数据是存放在HDFS上面的,分为数据和元数据,底层的执行引擎可以是:MapReduce/Tez/Spark,只需要通过一个参数就能够切换底层的执行引擎;Hive的作业是提交到YARN上运行的。
Hive的优缺点
- 优点:使用SQL进行操作
- 缺点:如果底层引擎是基于MapReduce,性能必然不高
Hive架构

其中元数据:表名、所属数据库、列(名/类型/index)、表类型、表数据所在目录
Hive和RDMS的区别
- 相同点:都支持写sql;都支持事务;insert/update/delete是Hive在0.14版本之后才支持,不过Hive数据仓库,写比较少的,批次加载数据到Hive然后进行统计分析
- 不同点:体量和集群规模;延迟和时性
Hive部署
- 参考文:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
- 环境:Linux,JDK8,Hadoop2.x,Mysql
- 下载安装包:wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.16.2.tar.gz
- 解压:tar -zxvf hive-1.1.0-cdh5.16.2.tar.gz -C ~/app/
- 软连接:ln -s hive-1.1.0-cdh5.16.2 hive
- 配置环境变量:vi .bashrc
export HIVE_HOME=/home/hadoop/app/hive export PATH=$HIVE_HOME/bin:$PATH - source .bashrc
- 修改配置文件 hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop01:3306/fei_hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>feixiang</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> <property> <name>hive.cli.print.header</name> <value>true</value> </property> </configuration> - 拷贝Mysql驱动包到$HIVE_HOME/lib下
Hive操作命令
- use dbname;切换到dbname所在的数据库
- show tables;查看当前数据库下的所有表
- 创建表:create table stu(id int, name string, age int);
- 查看表结构:desc stu;desc extended stu;desc formatted stu;
- 插入数据:insert into stu values(1,‘fei’,30);
- 查询数据:select * from stu;
Hive存储介绍
上面创建的stu表,默认的存储在HDFS的hdfs://hadoop01:8020/user/hive/warehouse/stu 上,其中stu是表名字;配置存储路径的参数hive.metastore.warehouse.dir:/user/hive/warehouse,表的完整路径是${hive.metastore.warehouse.dir}/tablename
Hive的完整执行日志
- cp hive-log4j.properties.template hive-log4j.properties
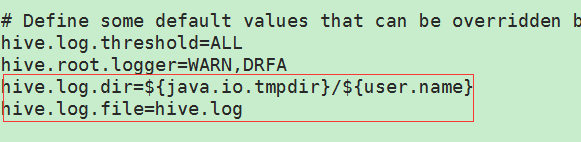
所以Hive的日志路径在${java.io.tmpdir}/${user.name}/${hive.log.file}即/tmp/hadoop/hive.log
Hive配置属性
- 全局:$HIVE_HOME/hive-site.xml
- 临时/当前session:仅对当前session生效
- 查看当前的属性:set key;(set hive.metastore.warehouse.dir)
- 修改当前的属性:set key = value(或者hive -hiveconf key=value)
Hive中交互式命令
- -e:不需要进入hive命令,就可以跟上sql语句查询
- -f:执行指定文件(内容是SQL语句)
基于Hive的离线统计/数据仓库,一般是把SQL封装到shell脚本中去,使用hive -e “query sql …”,然后使用调度器:crontab,去调度
创建数据库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
- CREATE DATABASE IF NOT EXISTS fei_hive;自己创建的Hive数据库的存放目录规则:${hive.metastore.warehouse.dir}/dbname.db=/user/hive/warehouse/fei_hive.db

- CREATE DATABASE IF NOT EXISTS fei_hive2 LOCATION ‘/fei/directory’;
- CREATE DATABASE IF NOT EXISTS fei_hive3 COMMENT ‘this is fei database’ WITH DBPROPERTIES(‘creator’=‘fei’, ‘date’=‘9012-12-30’);
删除数据库
-
删除database命令
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
-
DROP DATABASE IF EXISTS fei_hive2;CASCADE(了解即可,慎用):1 个database
对应多张表的时候
Hive数据类型
-
基本数据类型
数值类型:int、bigint、float、double、decimal
字符串类型:string (占了90%)
布尔类型:boolean true/false
日期类型:date timestamp … -
分隔符
delimiter code ^A \001 字段之间的分隔符 \n \n 记录分隔符 ^B \002 ARRAY/STRUCT (Hive中的复杂数据类型) ^C \003 key/value of MAP (Hive中的复杂数据类型)create table stu2(id int, name string, age int) row format delimited fields terminated by ','; insert into stu2 values(1,'fei',30);
Hive 创建表
-
Hive中有两种常见类型的表
内部表:MANAGED TABLE
外部表:EXTERNAL TABLECREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later) [(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)] ON ((col_value, col_value, ...), (col_value, col_value, ...), ...) [STORED AS DIRECTORIES] [ [ROW FORMAT row_format] [STORED AS file_format] | STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later) ] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later) [AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables) -
创建内部表
CREATE TABLE emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; -
导入数据
LOAD DATA LOCAL INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.txt' into table emp; -
复制表结构:create table emp2 like emp;
-
复制表结构和数据:CREATE TABLE emp3 as select * from emp;
-
创建外部表
CREATE EXTERNAL TABLE emp_external( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/fei/hive_external_table/emp/'; -
导入数据:需要把对应的emp.txt放入到HDFS上的/fei/hive_external_table/emp/目录下即可
Hive 删除表
- 内部表删除时候:HDFS和META都被删除
- 外包表删除的时候:HDFS不删除 ,仅META被删除
分区
- 不分区的话,磁盘IO和网络IO开销太大;分区其实对应就是HDFS上的一个文件夹和目录
create table order_partition( order_no string, event_time string ) PARTITIONED BY (event_month string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; - 分区列不是一个"真正的"表字段,其实是HDFS上表对应的文件夹下的一个文件夹;分区表加载数据一定要指定分区字段
LOAD DATA LOCAL INPATH '/home/hadoop/data/order_created.txt' INTO TABLE order_partition PARTITION (event_month='2014-05');

- 对于分区表操作,如果你的数据是写入到HDFS,默认sql是查询不到,因为元数据里面没有该信息

多级分区
- 单级分区是一层目录,多级分区是多层目录
创建表 create table order_mulit_partition( order_no string, event_time string ) PARTITIONED BY (event_month string, step string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; 导入数据 LOAD DATA LOCAL INPATH '/home/hadoop/data/order_created.txt' INTO TABLE order_mulit_partition PARTITION (event_month='2014-05',step='1');
注意:使用分区表时,加载数据一定要指定我们的所有分区字段
复制数据静态分区
- 创建静态分区表
CREATE TABLE emp_partition( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double ) PARTITIONED BY (deptno int) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; INSERT OVERWRITE TABLE emp_partition PARTITION (deptno=10) select empno,ename,job,mgr,hiredate,sal,comm from emp where deptno=10;
动态分区
- 创建动态分区表
CREATE TABLE emp_dynamic_partition( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double ) PARTITIONED BY (deptno int) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; INSERT OVERWRITE TABLE emp_dynamic_partition PARTITION (deptno) select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp; - 导入数据的时候要把查询select语句的deptno放在最后

通过该种方式进行导入分区数据,需要打开属性set hive.exec.dynamic.partition.mode=nonstrict
Hive DML
-
加载命令
LOAD DATA LOCAL INPATH '/home/hadoop/data/order_created.txt' [OVERWRITE] INTO TABLE order_mulit_partition PARTITION (event_month='2014-05',step='1');LOAD DATA : 加载数据
LOCAL: “本地” 没有的话就HDFS
INPATH: 指定路径
OVERWRITE:数据覆盖 ,没有的话就是追加CTAS:create table … as select …,表不能事先存在
insert:表必须事先存在insert overwrite table emp4 select empno,job,ename,mgr,hiredate,sal,comm,deptno from emp; -----把数据导入到hdfs某一目录中 INSERT OVERWRITE DIRECTORY '/hivetmp' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' SELECT empno,ename FROM emp;
Hive Select语句
- 查询命令
聚和函数时多进一出,比如max,min,count,sum,avgSELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [ORDER BY col_list] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ] [LIMIT [offset,] rows]
分组:group by
案例:求每个部门的平均工资大于2000
select deptno,avg(sal) avg_sal from emp group by deptno having avg_sal>2000;
其中select中出现的字段,如果没有出现在group by中,必须出现在聚和函数中
Hive中使用dual伪表
- 创建含有‘X’的dual.txt文本

- 创建表并且导入dual.txt中的数据

Hive修改元数据存储路径
- metatool -updateLocation
更改hive的fs.defaultFS配置 - metatool -updateLocation hdfs://hadoop01:19000 hdfs://hadoop01:9000















 790
790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









