







概述
一个正常的mr程序,有三个阶段可以进行压缩:map输入,map输出(中间阶段,要求尽可能的快,压缩时间要短),reduce输出
hadoop压缩格式

一个简单的案例对于集中压缩方式之间的压缩比和压缩速度进行一个感观性的认识
测试环境: 8 core i7 cpu
8GB memory
64 bit CentOS
1.4GB Wikipedia Corpus 2-gram text input
- 压缩比

- 压缩时间
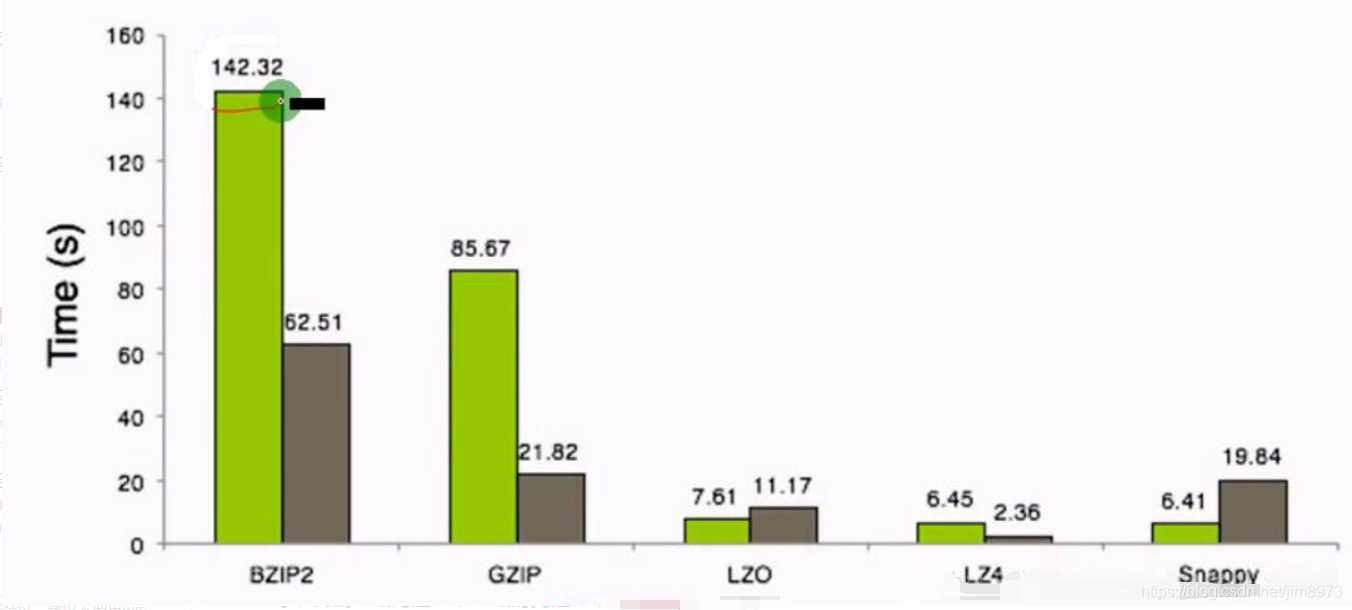
可以看出压缩比越高,压缩时间越长,压缩比:Snappy < LZ4 < LZO < GZIP < BZIP2
压缩格式的选择
压缩比和压缩速度,根据业务需求场景去选择,压缩是需要CPU支持的,是耗费CPU的,所以IO密集型的业务场景可以选择,但是计算密集型的业务是不适合的
在hadoop中的应用场景总结在三方面:输入,中间,输出。
整体思路 hdfs --> map --> shuffle -->reduce
- Use Compressd Map Input:从HDFS中读取文件进行Mapreuce作业,如果数据很大,可以使用压缩并且选择支持分片的压缩方式(Bzip2,LZO),可以实现并行处理,提高效率,减少磁盘读取时间,同时选择合适的存储格式例如Sequence
Files,RC,ORC等; - Compress Intermediate Data:Map输出作为Reducer的输入,需要经过shuffle这一过程,需要把数据读取到一个环形缓冲区,然后读取到本地磁盘,所以选择压缩可以减少了存储文件所占空间,提升了数据传输速率,建议使用压缩速度快的压缩方式,例如Snappy和LZO.
- Compress Reducer Output:进行归档处理或者链接Mapreduce的工作(该作业的输出作为下个作业的输入),压缩可以减少了存储文件所占空间,提升了数据传输速率,如果作为归档处理,可以采用高的压缩比(Gzip,Bzip2),如果作为下个作业的输入,考虑是否要分片进行选择。
编译hadoop源码使其支持相应的几种压缩格式
-
软件环境
件名称 组件版本 Hadoop hadoop-2.6.0-cdh5.16.2.tar.gz(包含源码) dk jdk-7u80-linux-x64.tar.gz maven apache-maven-3.6.3-bin.zip protobuf protobuf-2.5.0.tar.gz -
安装JDK,添加环境变量
-
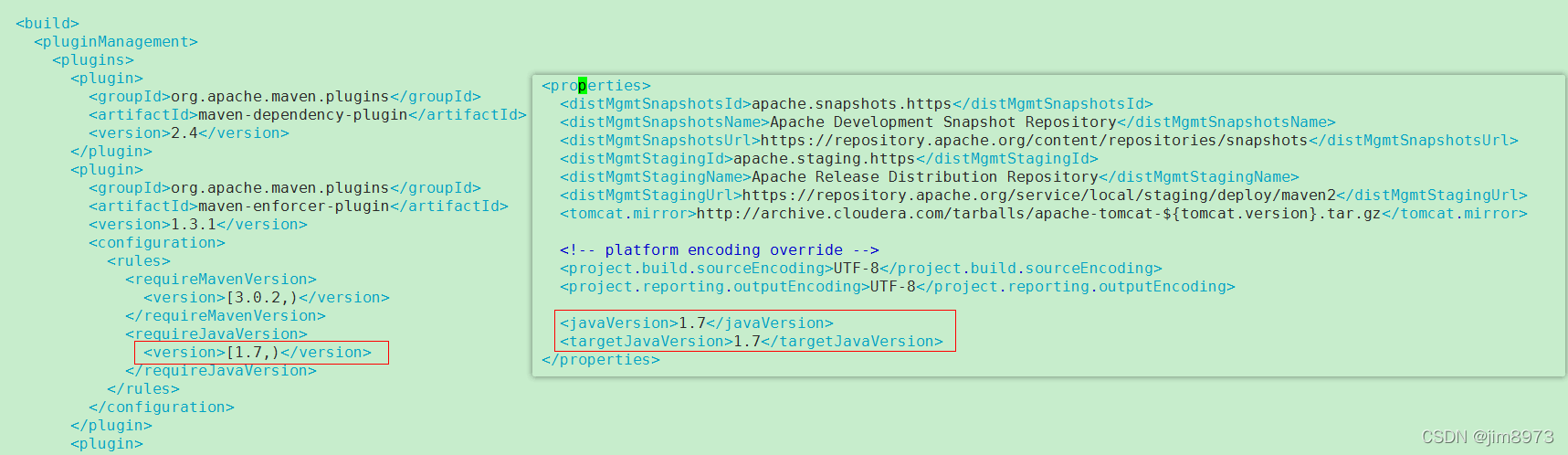
安装maven,添加环境变量。并且加上阿里云镜像
<mirror> <id>nexus-aliyun</id> <mirrorOf>central</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror>注意:jdk7如果无法找到,可以修改hadoop-2.6.0-cdh5.16.2/src/pom.xml,改成1.8即可
-
安装必要的依赖库
[root@hadoop01 ~]# yum install -y svn ncurses-devel [root@hadoop01 ~]# yum install -y gcc gcc-c++ make cmake [root@hadoop01 ~]# yum install -y openssl openssl-devel svn ncurses-devel zlib-devel libtool [root@hadoop01 ~]# yum install -y snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop autoconf automake cmake -
安装protobuf
protobuf它是一种轻便高效的数据格式,类似于Json,平台无关、语言无关、可扩展,可用于通讯协议和数据存储等领域。
优点:
平台无关,语言无关,可扩展;
提供了友好的动态库,使用简单;
解析速度快,比对应的XML快约20-100倍;
序列化数据非常简洁、紧凑,与XML相比,其序列化之后的数据量约为1/3到1/10。**编译protobuf** 1.[hadoop@hadoop02 ~]$ tar -zxvf ~/software/protobuf-2.5.0.tar.gz -C ~/app/ 2.[hadoop@hadoop02 ~]$ cd ~/app/protobuf-2.5.0/ # --prefix= 是用来待会编译好的包放在为路径 3.[hadoop@hadoop02 protobuf-2.5.0]$ ./configure --prefix=/home/hadoop/app/protobuf-2.5.0 4.[hadoop@hadoop02 protobuf-2.5.0]$ make 5.[hadoop@hadoop02 protobuf-2.5.0]$ make install添加到环境变量
vi .bashrc export PROTOBUF_HOME=/home/hadoop/app/protobuf-2.5.0 export PATH=$PROTOBUF_HOME/bin:$PATH source .bashrc -
编译Hadoop(耗时很长)
编译命令参考Hadoop官网
 进入src目录编译hadoop使其支持压缩:mvn clean package -Pdist,native -DskipTests -Dtar
进入src目录编译hadoop使其支持压缩:mvn clean package -Pdist,native -DskipTests -Dtar正常会报异常:无法下载相应的jar或者pom文件,可以直接wget或者本地找到相应的jar放入repository。例如
Failed to execute goal on project hadoop-auth: Could not resolve dependencies for project org.apache.hadoop:hadoop-auth:jar:2.6.0-cdh5.16.2: Failed to collect dependencies at org.mortbay.jetty:jetty-util:jar:6.1.26.cloudera.4: Failed to read artifact descriptor for org.mortbay.jetty:jetty-util:jar:6.1.26.cloudera.4: Could not transfer artifact org.mortbay.jetty:jetty-util:pom:6.1.26.cloudera.4 from/to cdh.repo (https://repository.cloudera.com/artifactory/cloudera-repos): Transfer failed for https://repository.cloudera.com/artifactory/cloudera-repos/org/mortbay/jetty/jetty-util/6.1.26.cloudera.4/jetty-util-6.1.26.cloudera.4.pom: Received fatal alert: protocol_version -> [Help 1]
则可以通过wget https://repository.cloudera.com/artifactory/cloudera-repos/org/mortbay/jetty/jetty-util/6.1.26.cloudera.4/jetty-util-6.1.26.cloudera.4.pom放入repository中即可。
当出现找不到avro-maven-plugin-2.6.0-cdh5.16.2,cloudera仓库中确实不存在,可以修改pom.xml中相应版本号1.7.6<plugin> <groupId>org.apache.avro</groupId> <artifactId>avro-maven-plugin</artifactId> <version>1.7.6</version> <executions> <execution> <id>generate-avro-test-sources</id> <phase>generate-test-sources</phase> <goals> <goal>schema</goal> </goals> </execution> </executions> <configuration> <testOutputDirectory>${project.build.directory}/generated-test-sources/java</testOutputDirectory> </configuration> </plugin> -
编译完成
经过漫长等待和手动添加jar和pom文件到repository中,终于build success了
进入到src/hadoop-dist/target/hadoop-2.6.0-cdh5.16.2/lib/native目录,复制native下面所有的文件到之前相同版本的集群中,重启集群。
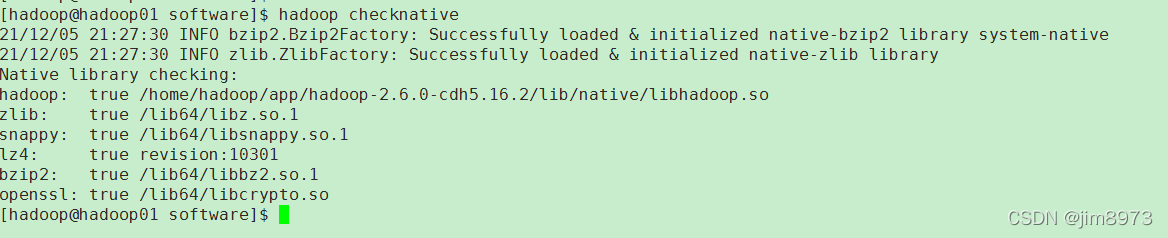
命令检查hadoop checknative
中间压缩配置和最终压缩配置
配置文件
core-site.xml(配置支持的压缩格式)
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec,
org.apache.hadoop.io.compress.Lz4Codec,
org.apache.hadoop.io.compress.SnappyCodec,
</value>
</property>
mapred-site.xml
#支持压缩的开关
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
#压缩方式
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.BZip2Codec</value>
</property>
中间压缩:中间压缩就是处理作业map任务和reduce任务之间的数据,对于中间压缩,最好选择一个节省CPU耗时的压缩方式(快)
hadoop压缩有一个默认的压缩格式,当然可以通过修改mapred.map.output.compression.codec属性,使用新的压缩格式,这个变量可以在mapred-site.xml 中设置
<property>
<name>mapred.map.output.compression.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description> This controls whether intermediate files produced by Hive
between multiple map-reduce jobs are compressed. The compression codec
and other options are determined from hadoop config variables
mapred.output.compress* </description>
</property>
最终压缩:可以选择高压缩比,减少了存储文件所占空间,提升了数据传输速率
mapred-site.xml 中设置
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.BZip2Codec</value>
</property>
Hive中设置压缩方式
SET hive.exec.compress.output=true; //默认不支持压缩
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Codec; //设置最终以bz2存储
注意:不建议再配置文件中设置(那样就不容易更改)
- BZip2整合Hive
[hadoop@hadoop data]$ du -sh page_views.dat
19M page_views.dat
创建表:
create table page_views(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
加载数据:
load data local inpath "/home/hadoop/data/page_views.dat" overwrite into table page_views;
hive:
SET hive.exec.compress.output=true;
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Codec;
create table page_views_bzip2
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
as select * from page_views;
hdfs dfs -du -s -h /user/hive/warehouse/fei_hive.db/page_views_bzip2/000000_0.bz2
大小:3.6 M
- snappy整合Hive
SET hive.exec.compress.output=true;
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
create table page_views_Snappy
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
as select * from page_views;
hdfs dfs -du -s -h /user/hive/warehouse/hive.db/page_views_snappy/000000_0.snappy
大小:8.4


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









